왜 이렇게 표현되는지를 이해해야 추후에 나오는 log-log plot 등을 이해할 수 있기에 여기에서 소개한다.
1. Notation
먼저 notation에 대해 소개하고자 한다.
1)$\mathbf{X}$
$\mathbf{X}$는 $X$들의 집합체이며, $X$는 모델을 설명하는 변수를 의미한다. 예를 들면, 특정 위험 요소에 노출 여부, 성별, 나이, 인종, 음주 여부, 흡연 여부 등이 있을 수 있다. 이 모든 것들을 적기에는 귀찮고 공간 낭비이므로 $\mathbf{X}$로 표현한다.
2)$S(t,\mathbf{X})$
$S(t,\mathbf{X})$는 특정 $\mathbf{X}$을 가진 사람의 시간 $t$에서의 생존 확률이다. 예를 들면, 남자, 53세, 백인, 음주자, 비흡연자의 12개월에서의 생존 확률인 것이다.
3) $S_0(t)$
$S_0 (t)$는 모델을 설명하는 변수들의 값이 기본값(reference)인 사람의 시간 $t$에서의 생존 확률을 의미한다. 예를 들어 모델의 기본값을 남성, 0세, 흑인, 비음주자, 비흡연자로 잡았다면, 이런 사람의 12개월에서의 생존 확률을 의미한다.
4) $e^{\sum_{i=1}^{p} \beta_i X_i}$
이 식에서 모델을 설명하는 변수는 $p$개 였음을 알 수 있고, $\beta_i$는 각 변수에 대한 회귀계수를 의미한다.
처음 ($t=0$)에는 모든 사람이 살아있으므로 $S(0)=1$이다. 이번에는 $S \left( \frac {1} {n} \right)$을 구해볼 것이다.
그렇다면 우리가 관심을 갖는 시간의 구간은 $\left[ 0, \frac{1}{n} \right]$이다.
위험 함수는 "그 순간에 단위시간당 사망할 확률"이므로 매 순간마다 다른 값을 가지는 것이 당연하지만, $n$이 매우 큰 수이므로 구간 $\left[ 0, \frac{1}{n} \right]$은 매우 짧은 찰나의 순간일 것이고, 그 사이에는 값이 거의 변하지 않는다고 봐도 무방하다. 이 구간의 $h(t)$는 $h \left( \frac {1} {n} \right)$으로 고정되어 있다고 가정하자.
그런데 위험함수는 단위 시간당 사망할 확률이므로 기준이 구간 $[0,1]$이다. 그런데 우리가 관심을 갖는 구간은 $\left[ 0, \frac{1}{n} \right]$이므로 이 구간에서 사망할 확률은 $h \left( \frac {1} {n} \right)$에 $\frac{1}{n}$을 곱해주어야 한다.
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
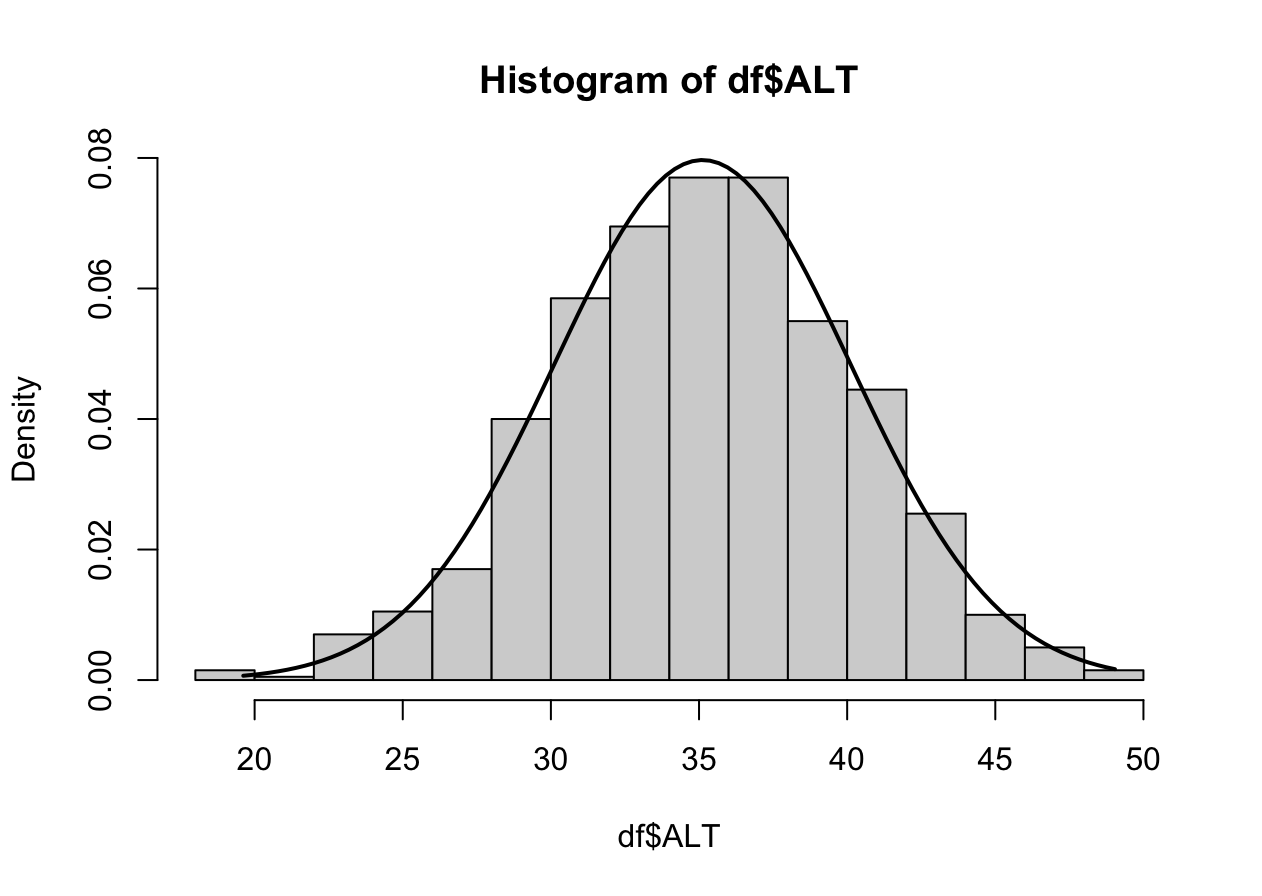
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
Shapiro-Wilk normality test
data: df$ALT
W = 0.9982, p-value = 0.3749
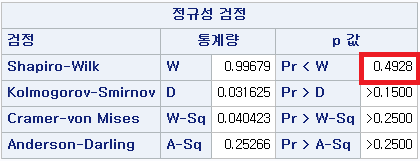
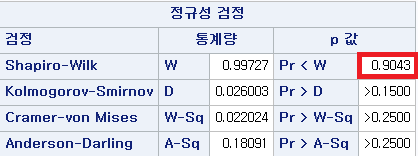
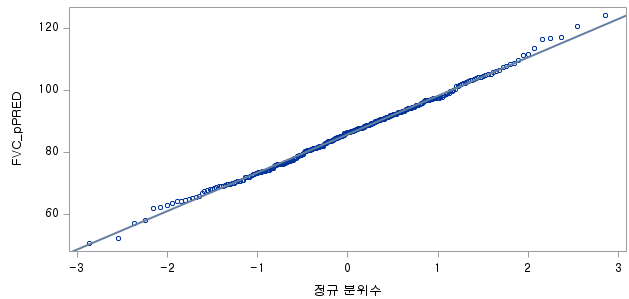
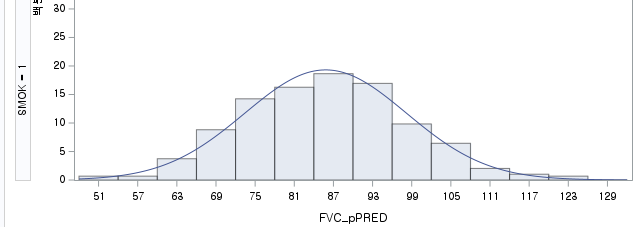
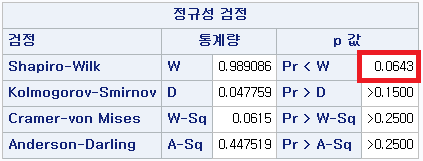
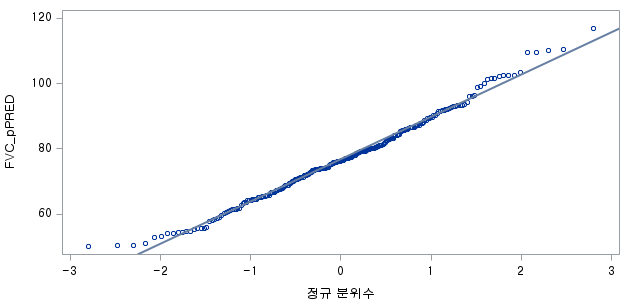
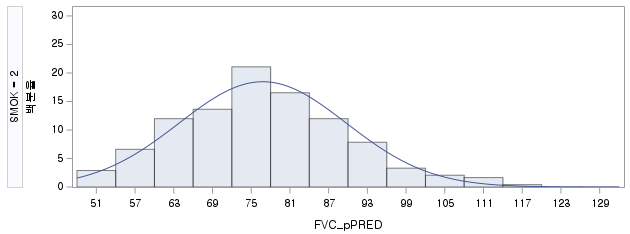
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다. 따라서 ALT로는 일표본 T검정 (One-sample T-test)를 시행할 수 있다.
일표본 T검정 (One sample T test)의 귀무가설과 대립 가설
이번 일표본 T검정 (One sample T test)의 귀무가설은 하나다.
귀무가설: $H_0=$ 모집단의 ALT 평균은 50이다.
하지만 대립 가설은 3개가 된다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
3) $H_1=$ 모집단의 평균은 50보다 크거나 작다. (양측 검정)
대립 가설 별로 코드를 보고자 한다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
t.test(df$ALT, mu=50, alternative="greater")
t.test(df$ALT, mu=50, alternative="greater") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균이 50보다 크다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value = 1
alternative hypothesis: true mean is greater than 50
95 percent confidence interval:
34.85529 Inf
sample estimates:
mean of x
35.11594
위의 결과 중 다음 내용에 주목해야 한다.
One Sample t-test data: df$ALT t = -94.014, df = 999, p-value = 1 alternative hypothesis: true mean is greater than 50 95 percent confidence interval: 34.85529 Inf sample estimates: mean of x 35.11594
P-value는 1.0000이다. 즉, 대립 가설 (모평균의 참값은 50보다 크다.)을 선택하는 것이 말이 안 된다는 것이다. 평균이 50보다 크다고 보는 것보다는 50이라고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
t.test(df$ALT, mu=50, alternative="less")
t.test(df$ALT, mu=50, alternative="less") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균이 50보다 작다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is less than 50
95 percent confidence interval:
-Inf 35.37659
sample estimates:
mean of x
35.11594
P-value는 $2.2 \times 10^{-16}$보다 작다. 즉, 대립 가설 (모평균의 참값은 50보다 작다.)이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
위 두 개의 코드는 같은 결과를 내준다. 왜냐하면 양측 검정 (alternative="two.sided")가 기본 값이어서 alternative 옵션을 지정해주지 않으면 alternative="two.sided"라고 인식하고 코드가 돌아가기 때문이다.
t.test(df$ALT, mu=50, alternative="two.sided") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균은 50이 아니다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 50
95 percent confidence interval:
34.80527 35.42661
sample estimates:
mean of x
35.11594
alternative hypothesis: true mean is not equal to 50
95 percent confidence interval:
34.80527 35.42661
sample estimates:
mean of x 35.11594
P-value는 $2.2 \times 10^{-16}$보다 작다. 즉, 대립 가설 (모평균의 참값은 50dㅣ 아니다.)이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작거나 크다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
주로 양측 검정이 이용되나, 사실 일표본 T검정은 거의 시행되지 않고 다음 글로 나올 독립 표본 T검정이 더 많이 사용된다.
음주 여부는 "1) 음주자", "2) 비음주자"로 나뉘는 이분형 변수다. 즉, 음주자의 ALT 평균과 비음주자의 ALT 평균을 비교한 것이었다.
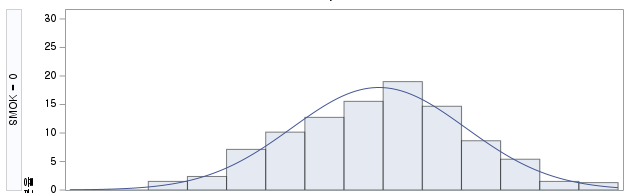
만약, 두 개 이상의 범주로 나뉘는 변수에 대해 모평균의 검정을 하고자 한다면 어떻게 해야 할까? 예를 들어, 흡연 상태를 "1) 비흡연자", "2) 과거 흡연자", "3) 현재 흡연자"로 나누었고, 각 그룹의 폐기능 검사 중 하나인 FVC (Forced Vital Capacity)의 평균에 차이가 있는지 알아보고자 한다.
이때 사용할 수 있는 방법이 일원 배치 분산 분석인 One-way ANOVA (Analysis of Variance)이며 이번 포스팅에서 다뤄볼 주된 내용이다.
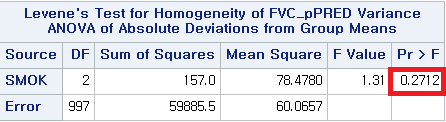
*1) Levene;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/ HOVTEST=LEVENE(TYPE=ABS);
RUN;
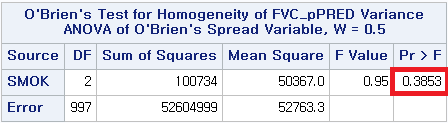
*2) O'Brien;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/ HOVTEST=OBRIEN;
RUN;
*3) Brwon and Forsythe;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/ HOVTEST=BF;
RUN;
*4) Bartlett;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/ HOVTEST=BARTLETT;
RUN;
QUIT;
결과
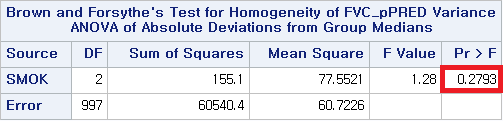
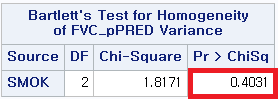
1) Levene
2) O'Brien
3) Brown and Forsythe
4) Bartlett
어떤 방법을 사용하더라도 p-value>0.05로 등분산성이라는 전제조건을 만족한다는 것을 알 수 있다. 따라서 일원 배치 분산 분석 (One-way ANOVA)를 시행할 수 있다.
일원 배치 분산 분석 (One way ANOVA) 코드
*1)사후분석- 본페로니;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/BON CLDIFF;
RUN;
QUIT;
*2)사후분석- 본페로니;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
LSMEANS SMOK/ADJUST=BON PDIFF;
RUN;
QUIT;
*3)사후분석- 던칸;
PROC GLM DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK/DUNCAN;
RUN;
QUIT;
세 가지 방법으로 코드를 소개했지만, 모두 대동소이하다. 첫 세 줄이 ANOVA 코드로 모두 동일하다. 네 번째 줄은 사후 분석 및 출력 방법에 대한 코드다. 사후 분석에 대해서는 아래에 설명하도록 하겠다.
1) 사후 분석: 본페로니(BONferroni) 방법을 사용하고, 차이의 신뢰구간 (Confidence Limits for DIFFerence)을 나타내라. PROC GLM DATA=hong.df; : 일반화 선형 모델 (GLM)을 시행하겠다. 데이터는 hong라이브러리의 df파일을 사용하라. CLASS SMOK; : 흡연 상태에 따라 분산 분석 (ANOVA)를 시행하라. MODEL FVC_pPRED=SMOK; : 흡연 상태(SMOK)에 따라 FVC % 예측치(FVC_pPRED)의 평균에 차이가 있는지 나타내라. MEANS SMOK/BON CLDIFF; : 흡연 상태(SMOK)에 따른 FVC % 예측치(FVC_pPRED)의 평균을 보여달라. 사후 분석은 본페로니(BONferroni, BON) 방법을 사용하고, 차이의 신뢰구간 (Confidence Limits for DIFFerence, CLDIFF)을 보여달라
- CLDIFF를 사용하기 위해서는 "MEANS"로 시작하는 구문을 사용해야 한다.
2) 사후 분석: 본페로니(BONferroni) 방법을 사용하고, 차이의 p-value (P-value for DIFFerence)를 나타내라. PROC GLM DATA=hong.df; : 일반화 선형 모델 (GLM)을 시행하겠다. 데이터는 hong라이브러리의 df파일을 사용하라. CLASS SMOK; : 흡연 상태에 따라 분산 분석 (ANOVA)를 시행하라. MODEL FVC_pPRED=SMOK; : 흡연 상태(SMOK)에 따라 FVC % 예측치(FVC_pPRED)의 평균에 차이가 있는지 나타내라. LSMEANS SMOK/ADJUST=BON PDIFF;: 흡연 상태(SMOK)에 따른 FVC % 예측치(FVC_pPRED)의 최소 제곱 평균(Least Squares MEANS, LSMEANS)을 보여달라. 사후 분석은 본페로니(BONferroni, BON) 방법을 사용하고, 차이의 p-value (P-value for DIFFerence)를 보여달라
- PDIFF를 사용하기 위해서는 "LSMEANS"로 시작하는 구문을 사용해야 한다.
3) 사후 분석: 던칸(DUNCAN) 방법을 사용하라. PROC GLM DATA=hong.df; : 일반화 선형 모델 (GLM)을 시행하겠다. 데이터는 hong라이브러리의 df파일을 사용하라. CLASS SMOK; : 흡연 상태에 따라 분산 분석 (ANOVA)를 시행하라. MODEL FVC_pPRED=SMOK; : 흡연 상태(SMOK)에 따라 FVC % 예측치(FVC_pPRED)의 평균에 차이가 있는지 나타내라. MEANS SMOK/DUNCAN;: 흡연 상태(SMOK)에 따른 FVC % 예측치(FVC_pPRED)의 평균을 보여달라. 사후 분석은 던칸(DUNCAN) 방법을 사용하라.
결과
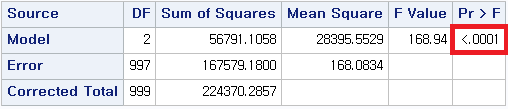
위 세 개의 코드에서 공통적인 부분 (ANOVA)의 결과는 다음과 같다.
P-value가 <0.0001이므로 귀무가설을 기각하고 대립 가설을 채택한다. 그렇다면 여기에서 귀무가설 및 대립 가설은 무엇이었는가?
귀무가설: $H0=$ 세 집단의 모평균은 "모두" 동일하다.
대립 가설: $H1=$ 세 집단의 모평균이 모두 동일한 것은 아니다.
우리는 대립 가설을 채택해야 하므로 "세 집단의 모평균이 모두 동일한 것은 아니다."라고 결론 내릴 것이다.
이 말은, 세 집단 중 두 개씩 골라 비교했을 때, 적어도 한 쌍에서는 차이가 난다는 것이다. 따라서 세 집단 중 두 개씩 골라 비교를 해보아야 하며, 이를 사후 분석 (post hoc analysis)이라고 한다. 세 집단에서 두 개씩 고르므로 가능한 경우의 수는 $_3 C_2=3$이다.
(1) 비흡연자 vs 과거 흡연자
(2) 비흡연자 vs 현재 흡연자
(3) 과거 흡연자 vs 현재 흡연자
사후 분석 결과 부분을 보겠다.
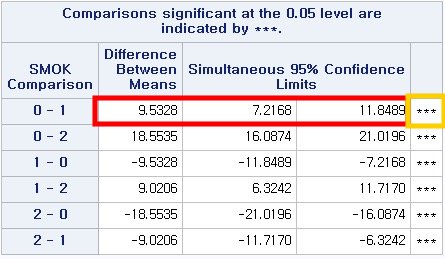
1) 사후 분석으로 본페로니(BONferroni) 방법을 사용하고, 차이의 신뢰구간 (Confidence Limits for DIFFerence)을 나타내라.
빨간 박스를 먼저 설명하면, 비흡연자 (SMOK=0)가 과거 흡연자 (SMOK=1)보다 FVC가 9.5328%p 더 크다. 그 차이의 95% 신뢰구간은 7.2168에서 11.8499이다. 즉 신뢰구간에 0이 포함되어있지 않으므로 유의미한 차이가 있다고 할 수 있다. 그런 경우 노란 박스의 "***" 표시를 해준다. 밑의 결과도 해석은 같다.
즉, 모든 사후 분석 결과에서 유의미한 차이가 있음을 알 수 있다.
2) 사후 분석: 본페로니(BONferroni) 방법을 사용하고, 차이의 p-value (P-value for DIFFerence)를 나타내라.
위의 방법 1)에서는 95% 신뢰구간만을 보여주고, p-value가 0.05보다 작은지만 보여줄 뿐, 정확한 p-value의 값은 알려주지 않는다. 정확한 p-value값을 알고 싶은 경우 LSMEANS구문에 PDIFF옵션을 사용하면 된다.
예를 들어 위의 빨간 박스는 그룹 1 (비흡연자)와 그룹 2(과거 흡연자) 사이의 평균의 차이에 대한 p-value를 보여준다. 위와 다르게 p-value를 보여준다는 장점은 있지만, 그 차이가 얼마인지, 신뢰구간은 얼마인지 보여주지 못하는 단점이 있다. 둘 중 어떤 방법으로 출력을 할지는 개인이 선택을 하면 된다.
3) 사후 분석: 던칸(DUNCAN) 방법을 사용하라.
이 시점에서 이런 의문이 들 수 있다.
"각각의 그룹별로 평균을 비교하면 되지, 굳이 왜 ANOVA라는 방법까지 사용하는 것인가?"
아주 논리적인 의문점이다. 하지만, 반드시 ANOVA를 사용해야 한다. 그 이유는 다음과 같다. 본 사례는 흡연 상태에 따른 조합 가능한 경우의 수가 3인데, 각각 유의성의 기준을 $\alpha=0.05$로 잡아보자. 이때 세 번의 비교에서 모두 귀무가설이 학문적인 진실인데(평균에 차이가 없다.), 세 번 모두 귀무가설을 선택할 확률은 $(1-0.95)^3 \approx 0.86$이다. (이해가 어려우면 p-value에 대한 설명 글을 읽고 오길 바란다. 2022.09.05 - [통계 이론] - [이론] p-value에 관한 고찰)
그런데, ANOVA의 귀무가설은 "모든 집단의 평균이 같다."이다. 따라서 모든 집단의 평균이 같은 것이 학문적 진실일 때, 적어도 한 번이라도 대립 가설을 선택하게 될 확률은 $1-0.86=0.14$가 된다. 즉, 유의성의 기준이 올라가게 되어, 덜 보수적인 결정을 내리게 되고, 다시 말하면 대립 가설을 잘 선택하는 쪽으로 편향되게 된다. 학문적으로는 '다중 검정 (multiple testing)을 시행하면 1종 오류가 발생할 확률이 증가하게 된다.'라고 표현한다.
따라서, 각각을 비교해보는 것이 아니라 한꺼번에 비교하는 ANOVA를 시행해야 함이 마땅하다.
여기에서 한 번 더 의문이 들 수 있다.
"사후 분석을 할 때에는 1종 오류가 발생하지 않는가?"
그렇다. 1종 오류가 발생할 확률이 있으므로, p-value의 기준을 더 엄격하게 (0.05보다 더 작게) 잡아야 한다. P-value를 보정하는 방법은 여러 가지가 나와있는데, 가장 간단하고 제일 보수적인 방법이 위에 예시에서 사용한 본페로니 방법이다. 그 외에도 많은 방법이 있고 다른 방법을 사용하기 위해서는 BON의 자리에 다음 중 하나를 입력하면 된다.
코드
내용
코드
내용
BON
Bonferroni t test
SCHEFFE
Scheffe's multiple comparison
DUNCAN
Duncan's multiple range test
SIDAK
Pairwise t test (Sidak's inequality)
DUNNETT
Dunnett's two-tailed t test
SMM (혹은 GT2)
Pairwise comparisons (studentized maximum modulus, Sidak's uncorrelated t-inequality)
DUNNETTL
Dunnett's one-tailed t test (less)
SNK
Student-Newman-Keuls
DUNNELLU
Dunnett's one-tailed t test (greater)
T (혹은 LSD)
Pairwise t test
GABRIEL
Gabriel's multiple comparison
TUKEY
Tukey's studentized range test
REGWQ
Ryan-Einot-Habriel-Welsch
WALLER
Waller-Duncan k-ratio t test
굉장히 많은 방법이 있지만, Bonferroni, Duncan, Scheffe, Tukey가 가장 많이 쓰이는 듯하다. 이 중에 Duncan, Tukey는 그룹별로 표본의 수가 같을 때만 사용해야 하므로 유의하도록 한다.
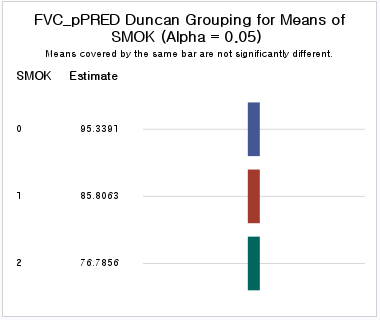
그중에 DUNCAN옵션을 사용하여 산출한 결과는 다음과 같다.
막대기가 연결되어 있으면 평균이 서로 다르다고 할 수 없는 것이고, 끊어져 있으면 서로 다르다고 할 수 있는 것이다. 위의 경우 비흡연자 (SMOK=0)은 파란 막대기가 있고, 과거 흡연자 (SMOK=1)는 빨간 막대기로 파란 막대기와 분리되어 있다. 따라서 과거 흡연자의 FVC는 비흡연자의 FVC와 유의하게 다르다고 할 수 있다. 현재 흡연자 (SMOK=2)는 초록 막대기로 파랑 및 빨간 막대기와 분리되어 있다. 따라서 현재 흡연자의 FVC는 비흡연자 및 과거 흡연자의 FVC와 유의하게 다르다고 할 수 있다. 즉 모든 그룹에서 FVC의 평균은 다르다고 할 수 있다.
어떤 사후 분석을 쓸 것인가
이 논의에 대해 정답이 따로 있는 것은 아니다. 적절한 방법을 사용하여 논문에 제시하면 되고, 어떤 것이 정답이라고 콕 집어 이야기할 수는 없다. 다만, 사후 분석 방법이 여러 가지가 있다는 것은 '사후 분석 방법에 따라 산출되는 결과가 달라질 수 있다.'는 것을 의미하고, 심지어는 '어떤 사후 분석 방법을 채택하냐에 따라 유의성 여부가 달라질 수도 있다.'는 것을 의미한다. 심지어, ANOVA에서는 유의한 결과가 나왔는데, 사후 분석을 해보니 유의한 차이를 보이는 경우가 없을 수도 있다. 따라서 어떤 사후 분석 방법 결과에 따른 결과인지 유의하여 해석할 필요가 있다.
PROC ANOVA
PROC ANOVA에 대한 설명을 듣고자 본 포스팅에 들어온 독자도 있을 것이다. 하지만 이는 다루지 않을 것이다. 왜냐하면 PROC ANOVA는 그룹별로 표본의 수가 같아야만 사용할 수 있는, 아주 제한적인 상황에서만 쓸 수 있는 코드이기 때문이다. 따라서 웬만하면 PROC GLM을 사용하길 권한다. 만약 사용하고자 한다면, PROC GLM을 PROC ANOVA로만 바꾸어 다음과 같이 사용하면 된다.
PROC ANOVA DATA=hong.df;
CLASS SMOK;
MODEL FVC_pPRED=SMOK;
MEANS SMOK;
RUN;
SAS 일원 배치 분산 분석 (One-way ANOVA, ANalysis Of VAriance) 정복 완료!
[SAS] 대응 표본 T검정 (Paired samples T-test) - PROC TTEST
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 그리고, 간 기능 개선제를 복용시킨 뒤 ALT 검사를 다시 시행하였다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서 간 기능 개선제 복용은 ALT 수치를 개선시키는지 여부를 확인하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
예) 간 기능 개선제 복용 전 ALT 평균은 간기는 개선제 복용 후 ALT 평균과 다르다고 할 수 있는가?
이번 포스팅에서는 대응 표본 T검정 (Paired samples T-test)에 대해 알아볼 것이다.
왜 대응 표본 T 검정이 필요할까?
독립 표본 T 검정을 공부한 사람이라면 대응 표본 T 검정의 필요성에 대해 의구심을 가질 수 있다. 간 기능 개선제 복용 전 ALT와 간 기능 개선제 복용 후 ALT에 대해 독립 표본 T 검정을 돌리면 될 것이라고 생각할 수 있기 때문이다. 하지만 결론적으로 그렇게 하면 안 된다. 예를 들어 다음 사례를 봐보자.
환자 번호
시험 공부 전 시험 점수
시험 공부 후 시험 점수
1번
0.1
0.2
2번
0.2
0.3
...
$x$
$x+0.1$
999번
99.9
100.0
1000번
100.0
100.0
1000명이 시험을 보았고, 원래 100점을 받았던 1000번을 제외한 모든 사람이 시험공부로 0.1점이 올랐다. 1000명 중 999명의 점수가 올랐으므로 공부는 시험 점수를 올리는데 유의미한 영향력을 미칠 수 있다고 결론이 나야 합당할 것이다. 하지만 공부 전 후 시험 점수의 평균은 둘 다 50점에 가깝고 큰 변화는 없는 것처럼 보인다. 따라서 독립 표본 T 검정으로 내린 결론은 잘못된 것이다. 즉, 대응되는 (paired) 경우 그 값 자체보다는 둘 사이의 차이에 집중해야 한다.
DATA hong.df;
SET hong.df;
*차이를 나타내는 변수는 ALT_DIF;
ALT_DIF=ALT-ALT_POSTMED;
RUN;
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
VAR ALT_DIF;
HISTOGRAM ALT_DIF/ NORMAL (MU=EST SIGMA=EST);
RUN;
결과
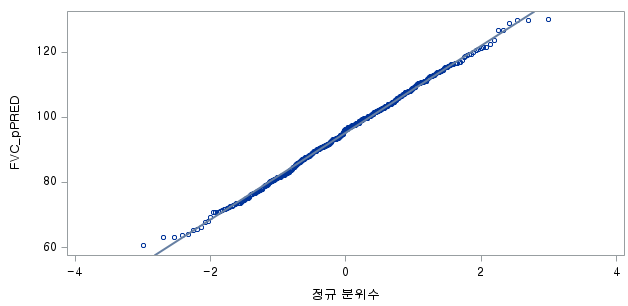
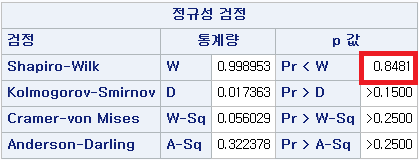
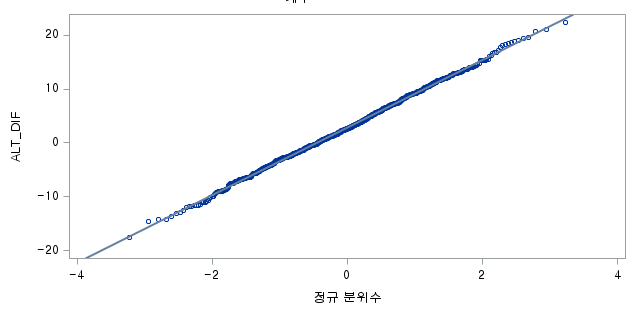
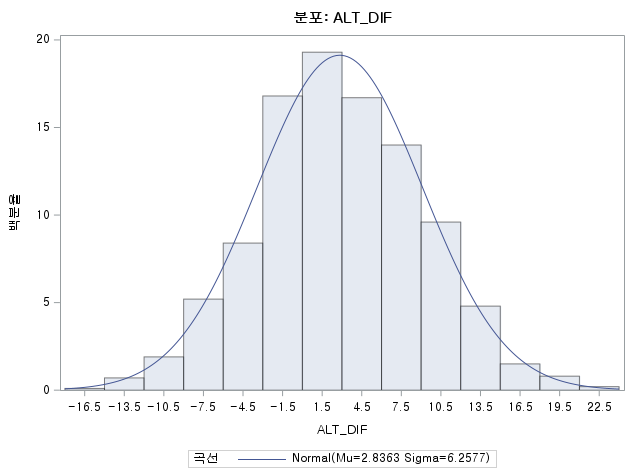
N 수는 1000으로 2000 미만이므로 Shapiro-Wilk 통계량의 p-value는 0.05 이상이다. Q-Q plot상에서 대부분의 데이터가 직선상에 있으며, 히스토그램 또한 정규분포를 따르는 것처럼 보이므로 두 변수의 차는 정규분포를 따른다고 할 수 있다. 따라서 대응 표본 T 검정 (Paired samples T test)를 시행할 수 있다.
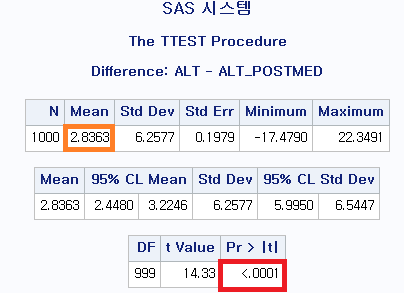
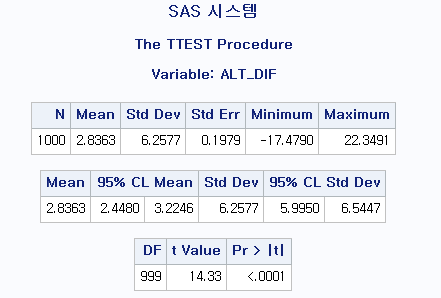
PROC TTEST DATA=hong.df; : T-test를 시행할 것이고, 데이터는 hong 라이브러리의 df 데이터를 이용하라. PAIRED ALT*ALT_POSTMED; : 대응 표본 T 검정(PAIRED)을 시행할 것이고, 각각의 변수는 ALT와 ALT_POSTMED이다.
결과
ALT의 평균이 ALT_POSTMED의 평균에 비해 2.8363만큼 더 크다. 그리고 그 차이의 p-value는 <0.0001로 유의미하다. 따라서 귀무가설을 기각할 수 있다. 본 검정의 귀무가설은 다음과 같다.
귀무가설: $H_0$=간 기능 개선제 복용 전 후의 ALT 평균은 동일하다.
이를 기각하므로 동일하지 않다고 할 수 있고, 간 기능 개선제 복용 후 ALT가 2.8363만큼 낮아져 간 기능에 호전이 있다고 평가할 수 있다.
DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;
IF AST>=40 THEN AST_S3=0;
ELSE IF AST<40 AND AST>=20 THEN AST_S3=1;
ELSE IF AST<20 THEN AST_S3=2;
RUN;
IF AST>=40 THEN AST_S3=0; : AST가 40 이상이면 AST_S3의 값은 0을 부여한다. ELSE IF AST<40 AND AST>=20 THEN AST_S3=1; : AST가 40 미만이면서 20 이상이면 AST_S3의 값은 1을 부여한다. ELSE IF AST<20 THEN AST_S3=2; : AST가 20 미만이면 AST_S3의 값은 2를 부여한다.
DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;
IF AST>=40 THEN AST_S3=0;
ELSE IF AST<40 AND AST>=20 THEN AST_S3=1;
ELSE IF AST<20 THEN AST_S3=2;
*AST 결측 여부 확인 변수 만들기;
IF AST=. THEN AST_MISS=1;
ELSE AST_MISS=0;
RUN;
*분할표 만들기;
PROC FREQ DATA=hong.df_new;
TABLE AST_S3 * AST_MISS / NOROW NOCOL NOPERCENT;
RUN;
결과
결측값 8개에 AST_S3의 값으로 2가 부여되어 있다. 이는 명백히 "ELSE IF AST<20 THEN AST_S3=2;" 코드에서 기인한 문제다. 즉, SAS는 AST의 결측치에 대해 "AST<20"가 옳다고 (TRUE) 본 것이다. 이를 해결하기 위해서는 코드를 다음과 같이 작성해야 한다. (두 가지 방법 모두 옳다.)
코드
*방법 1: "AST>=0"을 추가하기;
DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;
IF AST>=40 THEN AST_S3=0;
ELSE IF AST<40 AND AST>=20 THEN AST_S3=1;
ELSE IF AST<20 AND AST>=0 THEN AST_S3=2;
RUN;
*방법 2: "AST^=."을 추가하기;
DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;
IF AST>=40 THEN AST_S3=0;
ELSE IF AST<40 AND AST>=20 THEN AST_S3=1;
ELSE IF AST<20 AND AST^=. THEN AST_S3=2;
RUN;
방법 1은 "AST>=0"을 추가하여 결측치는 해당 조건을 만족하지 않게 조정한 것이다.
방법 2는 "AST^=."을 추가하였다. "^="는 같지 않다는 뜻이므로, AST가 결측이 아니라는 뜻을 의미한다.
각 방법에는 세 가지 조건이 존재한다. 방법 2를 기준으로 한다면
조건 1: AST>=40
조건 2: AST<40 AND AST>=20
조건 3: AST<20 AND AST^=.
인데, 결측치는 세 조건 모두 부합하지 않았다. 따라서 결측치는 THEN 뒤로 넘어가 본 적이 없다. THEN 뒤에서는 AST_S3의 값을 배정받으므로 결측치는 AST_S3값을 배정받아본 적이 없는 것이다. 따라서 AST가 결측인 경우에는 AST_S3 또한 결측치가 된다.
>, <, >=, <=등은 실제 코딩을 하다 보면 매우 입력하기 귀찮아지는데, 다음과 같은 영문 부호로 이를 대체할 수도 있다.
연산 부호
영문 부호
뜻
=
EQ
같다
~= ^=
NE
같지 않다
>
GT
크다
<
LT
작다
>=
GE
크거나 같다
<=
LE
작거나 같다
^> ~>
NG
크지 않다
^< ~<
NL
작지 않다
MAX, MIN
최댓값을 구하는 MAX, 최솟값을 구하는 MIN 함수다. 간 기능 지표 (ALT, AST) 중 큰 것을 고른 LIVER_MAX변수와, 작은 것을 고른 LIVER_MIN변수를 새로 만든다고 하자. 그럼 코드는 다음과 같다.
DATA hong.df_new;
SET hong.df;
*최댓값;
LIVER_MAX=MAX(AST, ALT);
*최솟값;
LIVER_MIN=MIN(AST, ALT);
RUN;
LIVER_MAX=MAX(AST, ALT); : AST와 ALT 중 더 큰 값을 LIVER_MAX에 저장하라. LIVER_MIN=MIN(AST, ALT); : AST와 ALT 중 더 작은 값을 LIVER_MIN에 저장하라.
여기에서는 결측치를 어떻게 처리할까?
AST, ALT 둘 중 하나가 결측치인 경우 MIN, MAX모두 결측치가 아닌 값을 반환한다.
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*과거 흡연자 // 현재 흡연자 + 비흡연자로 나누기;
IF SMOK IN (0 2) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
IF SMOK IN (0 2) THEN SMOK_S2=0; : SMOK가 0 혹은 2인 경우 SMOK_S2에는 0을 부여한다. ELSE SMOK_S2=1; : 그 외에는 SMOK_S2에 1을 부여한다.
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (1);
IF SMOK=0 THEN SMOK_S2=0;
ELSE IF SMOK=1 THEN SMOK_S2=0;
ELSE IF SMOK=2 THEN SMOK_S2=1;
RUN;
IF구문은 다음과 같은 구조를 띤다.
IF {조건1} THEN {실행1} :"조건 1"을 만족하면 "실행1"을 실시한다.
ELSE IF {조건2} THEN {실행2} :"조건 1"을 만족하지 않는 데이터 중 "조건 2"를 만족하면 "실행 2"를 실시한다.
...
ELSE {마지막 실행} :"조건1", "조건 2", ... 를 만족하지 않는 데이터는 "마지막 실행"을 실시한다.
이를 적용하면 다음과 같이 해석할 수 있다.
IF SMOK=0 THEN SMOK_S2=0; : SMOK가 0이면 SMOK_S2는 0이다. ELSE IF SMOK=1 THEN SMOK_S2=0; : SMOK가 0이 아닌 사람 중 SMOK가 1인 사람의 SMOK_S2는 0이다. ELSE IF SMOK=2 THEN SMOK_S2=1;: SMOK가 0, 1이 아닌 사람 중 SMOK가 1인 사람의 SMOK_S2는 0이다.
여기에는 ELSE구문이 없으므로, 모든 조건에 부합하지 못한 데이터가 만약 있다면 그 사람의 SMOK_S2는 결측치로 대체된다.
2) 방법 2
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (2);
IF SMOK=0 THEN SMOK_S2=0;
ELSE IF SMOK=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
1) 1000명 전원은 {비흡연자, 과거 흡연자, 현재 흡연자} 셋 중의 하나에 반드시 속한다.
2) 비흡연자에게 SMOK_S2는 0의 값을 부여하고, 과거 흡연자에게 SMOK_S2는 1의 값을 부여한다.
3) 아직 SMOK_S2값을 부여받지 못한 사람은 모두 현재 흡연자이므로 SMOK_S2는 1의 값을 부여한다.
위의 3) 내용을 코드로 옮기면 "ELSE SMOK_S2=1"가 된다.
만약 결측치가 있다면 흡연 정보를 모르는 사람 또한 SMOK_S2의 값은 1이 부여되어 현재 흡연자로 평가받기 때문에 결측치가 있을 때에는 이 코드를 사용하면 안 된다.
3) 방법 3
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (3);
IF SMOK=0 OR SMOK=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
OR 연산자를 사용하면 코드가 조금 더 간단해진다.
OR 연산자는 OR 앞뒤로 있는 조건 중 어떤 것이라도 만족하면 옳다고(TRUE)로 인식한다. 우리는 과거 흡연자, 비흡연자 모두 SMOK_S2에서는 0이라는 값을 부여할 것이므로 SMOK변수는 0이든 1이든 둘 중 하나이기만 하면 된다.
IF SMOK=0 OR SMOK=1 THEN SMOK_S2=0;
그래서 SMOK=0, SMOK=1 중 하나라도 만족하면 SMOK_S2에는 0이라는 값을 부여한다는 위 코드를 사용하였다.
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (4);
IF SMOK<=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
과거 흡연자와 비흡연자의 SMOK값은 각각 0,1이므로 "SMOK<=1"이라고 쓸 수도 있다.
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (5);
IF SMOK IN (0 1) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (6);
IF SMOK IN (0:1) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
방법 5의 IF SMOK IN (0 1) THEN SMOK_S2=0;
- SMOK가 0, 1인 데이터에게만 SMOK_S2의 값으로 0을 부여한다는 뜻이다.
방법 6의 IF SMOK IN (0:1) THEN SMOK_S2=0;
- SMOK가 0 이상 1 이하의 정수인 데이터에게만 SMOK_S2의 값으로 0을 부여한다는 뜻이다.
6) 방법 7
방법 6은 사실 "SMOK가 0 이상이면서 1 이하인 정수 데이터"에게 SMOK_S2의 값으로 0을 부여한 것이다. 이는 AND연산자를 사용한 것과 다름없다. AND 연산자는 AND 앞뒤로 있는 조건을 모두 만족해야 TRUE를 반환하는데, 이 경우 SMOK>=0 AND SMOK<=1 이라는 문구를 사용하면 되는 것이다.
*결측치가 없음을 확인하기;
PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (7);
IF SMOK>=0 AND SMOK<=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
AND 연산자는 OR 연산자보다 우선하므로, 괄호를 적절히 치며 사용해야 한다. (사칙연산에서 곱셈이 덧셈보다 우선하는 것과 동일하다)