
[R] 일표본 T검정 (One-sample T-test) - t.test()
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
1) 일표본 T검정 (One sample T-test)
: 모집단의 평균이 특정 값이라고 할 수 있는가?
예) 모집단의 ALT 평균이 50이라고 할 수 있는가?
2) 독립 표본 T검정 (Independent samples T-test): 2022.11.12 - [모평균 검정/R] - [R] 독립 표본 T검정 (Independent samples T-test) - t.test(), var.test(), levene.test()
: 두 모집단의 평균이 다르다고 할 수 있는가?
예) 고혈압 환자와 일반인의 수축기 혈압 평균이 서로 다르다고 할 수 있는가?
3) 대응표본 T검정 (Paired samples T-test): 2022.11.25 - [반복 측정 자료 분석/R] - [R] 대응 표본 T검정 (Paired samples T-test) - t.test()
: 모집단의 짝지어진 변수들의 평균이 다르다고 할 수 있는가?
예) 간기능 개선제 복용 전 ALT 평균은 간기는 개선제 복용 후 ALT 평균과 다르다고 할 수 있는가?
이번 포스팅에서는 일표본 T검정 (One sample T-test)에 대해 알아볼 것이다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.10.11)
분석용 데이터 (update 22.10.11)
2022년 10월 11일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 범주형 자료 분석 - 모평균 검정 - 반복 측정 자료 분석 - 통계
medistat.tistory.com
코드를 보여드리기에 앞서 워킹 디렉토리부터 지정하겠다.
워킹 디렉토리에 관한 설명은 다음 링크된 포스트에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 작업 디렉토리 (Working Directory) 지정 - getwd(), setwd()
setwd("C:/Users/user/Documents/Tistory_blog")
데이터를 불러와 df에 객체로 저장하겠다.
데이터 불러오는 방법은 다음 링크에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : EXCEL - read_excel(), read.xlsx()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 저장하기 : CSV 파일 - write.csv(), write_csv()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : SAS file (.sas7bdat) - read.sas7bdat(), read_sas()
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
목표: 모집단의 ALT 평균이 50이라고 할 수 있는가?
이번 포스팅의 목적은 1000명의 데이터를 가지고, 이 1000명이 기원한 모집단의 ALT평균이 50이라고 할 수 있는지 판단하는 것이다.
전제조건 (정규성) - 코드
일표본 (One sample) T 검정의 전제조건은 해당 분포가 정규성을 따른다는 것이다. 정규성 검정을 하도록 하겠다. 정규성 검정에 관한 분석 내용은 다음 글에서 살펴볼 수 있다.
2022.08.11 - [기술 통계/R] - [R] 정규성 검정 (1) : Q-Q plot - qqnorm(), qqline()
2022.08.11 - [기술 통계/R] - [R] 정규성 검정 (2) : 히스토그램 - hist(), dnorm()
2022.08.12 - [기술 통계/R] - [R] 정규성 검정 (4) : 정량적 검정 (Lilliefors test) - lillie.test()
2022.08.16 - [기술 통계/R] - [R] 고급 Q-Q Plot - Van der Waerden, Rankit, Tukey, Blom
# 1) Q-Q plot 그리기
qqnorm(df$ALT)
qqline(df$ALT)
# 2) 히스토그램 그리기
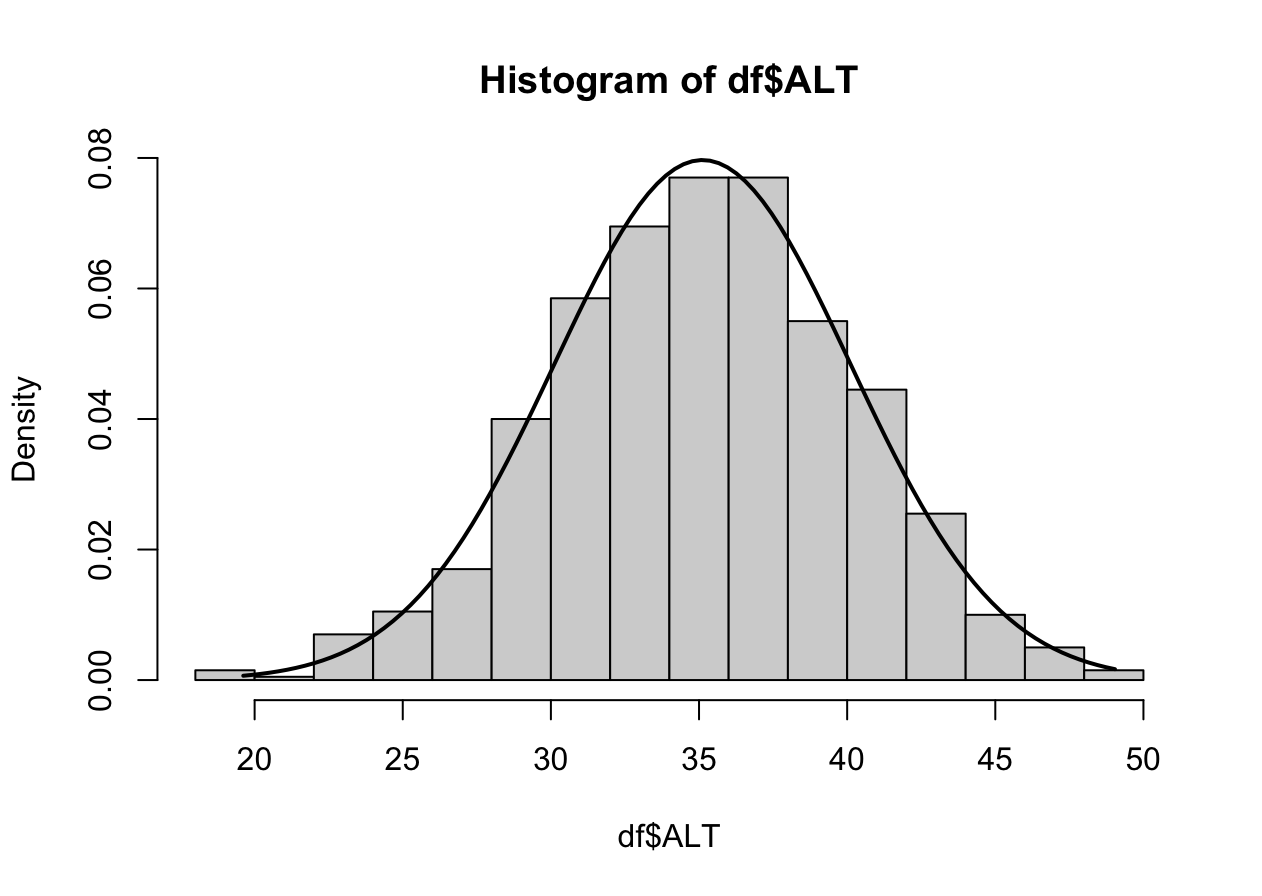
hist(df$ALT, prob=TRUE)
ALTrange<-seq(min(df$ALT),max(df$ALT),length=max(max(df$ALT)-min(df$ALT),100))
ND<-dnorm(ALTrange,mean=mean(df$ALT),sd=sd(df$ALT))
lines(ALTrange, ND, lwd=2)
# 3) Shapiro-Wilk test 시행하기
shapiro.test(df$ALT)
정규성 검정 - 결과

Shapiro-Wilk normality test
data: df$ALT
W = 0.9982, p-value = 0.3749
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다. 따라서 ALT로는 일표본 T검정 (One-sample T-test)를 시행할 수 있다.
일표본 T검정 (One sample T test)의 귀무가설과 대립 가설
이번 일표본 T검정 (One sample T test)의 귀무가설은 하나다.
귀무가설: H0= 모집단의 ALT 평균은 50이다.
하지만 대립 가설은 3개가 된다.
1) H1= 모집단의 평균은 50보다 크다. (단측 검정)
2) H1= 모집단의 평균은 50보다 작다. (단측 검정)
3) H1= 모집단의 평균은 50보다 크거나 작다. (양측 검정)
대립 가설 별로 코드를 보고자 한다.
1) H1= 모집단의 평균은 50보다 크다. (단측 검정)
t.test(df$ALT, mu=50, alternative="greater")t.test(df$ALT, mu=50, alternative="greater") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균이 50보다 크다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value = 1
alternative hypothesis: true mean is greater than 50
95 percent confidence interval:
34.85529 Inf
sample estimates:
mean of x
35.11594위의 결과 중 다음 내용에 주목해야 한다.
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value = 1
alternative hypothesis: true mean is greater than 50
95 percent confidence interval:
34.85529 Inf
sample estimates:
mean of x 35.11594
P-value는 1.0000이다. 즉, 대립 가설 (모평균의 참값은 50보다 크다.)을 선택하는 것이 말이 안 된다는 것이다. 평균이 50보다 크다고 보는 것보다는 50이라고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
2) H1= 모집단의 평균은 50보다 작다. (단측 검정)
t.test(df$ALT, mu=50, alternative="less")t.test(df$ALT, mu=50, alternative="less") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균이 50보다 작다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is less than 50
95 percent confidence interval:
-Inf 35.37659
sample estimates:
mean of x
35.11594위의 결과 중 다음 내용에 주목해야 한다.
One Sample t-test
data: df$ALT t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is less than 50
95 percent confidence interval:
-Inf 35.37659
sample estimates:
mean of x 35.11594
P-value는 2.2×10−16보다 작다. 즉, 대립 가설 (모평균의 참값은 50보다 작다.)이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
3) H1= 모집단의 평균은 50보다 작거나 크다. (양측 검정)
t.test(df$ALT, mu=50, alternative="two.sided")
t.test(df$ALT, mu=50)위 두 개의 코드는 같은 결과를 내준다. 왜냐하면 양측 검정 (alternative="two.sided")가 기본 값이어서 alternative 옵션을 지정해주지 않으면 alternative="two.sided"라고 인식하고 코드가 돌아가기 때문이다.
t.test(df$ALT, mu=50, alternative="two.sided") : T-test를 시행한다. 검정할 변수는 df 데이터의 ALT변수다. ALT의 모평균이 50이라고 할 수 있는지 검정할 것이다. 대립 가설은 "모평균은 50이 아니다"이다.
결과
One Sample t-test
data: df$ALT
t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 50
95 percent confidence interval:
34.80527 35.42661
sample estimates:
mean of x
35.11594
위의 결과 중 다음 내용에 주목해야 한다.
One Sample t-test
data: df$ALT t = -94.014, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 50
95 percent confidence interval:
34.80527 35.42661
sample estimates:
mean of x 35.11594
P-value는 2.2×10−16보다 작다. 즉, 대립 가설 (모평균의 참값은 50dㅣ 아니다.)이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작거나 크다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
주로 양측 검정이 이용되나, 사실 일표본 T검정은 거의 시행되지 않고 다음 글로 나올 독립 표본 T검정이 더 많이 사용된다.
코드 정리
#워킹 디렉토리 지정
setwd("C:/Users/user/Documents/Tistory_blog")
#데이터 불러오기
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
##정규성 검정##
# 1) Q-Q plot 그리기
qqnorm(df$ALT)
qqline(df$ALT)
# 2) 히스토그램 그리기
hist(df$ALT, prob=TRUE)
ALTrange<-seq(min(df$ALT),max(df$ALT),length=max(max(df$ALT)-min(df$ALT),100))
ND<-dnorm(ALTrange,mean=mean(df$ALT),sd=sd(df$ALT))
lines(ALTrange, ND, lwd=2)
# 3) Shapiro-Wilk test 시행하기
shapiro.test(df$ALT)
##T-test 1
# 단측 (대립가설=크다) 검정 t-test
t.test(df$ALT, mu=50, alternative="greater")
##T-test 2
# 단측 (대립가설=작다) 검정 t-test
t.test(df$ALT, mu=50, alternative="less")
##T-test 3
# 양측 검정 t-test
t.test(df$ALT, mu=50, alternative="two.sided")
t.test(df$ALT, mu=50)
R 일표본 T검정 (One-sample T-test) 정복 완료!
작성일: 2022.11.03.
최종 수정일: 2022.11.29.
이용 프로그램: R 4.1.3
RStudio v1.4.1717
RStudio 2021.09.1+372 "Ghost Orchid" Release
운영체제: Windows 10, Mac OS 10.15.7