[SAS] 연속성 수정 카이 제곱 검정 (Yates's correction for continuity) - PROC FREQ
본 글은 기존 카이 제곱 검정 포스팅의 후속 포스팅이므로 다음 글을 미리 읽고 오길 권한다.
2022.08.19 - [범주형 자료 분석/SAS] - [SAS] 카이 제곱 검정 - PROC FREQ
[SAS] 카이 제곱 검정 - PROC FREQ
[SAS] 카이 제곱 검정 - PROC FREQ 카이 제곱 검정은 범주형 변수 간에 분포의 유의미한 차이가 있는지 확인하는 방법이다. 이해할 수 있는 언어로 표현하면 다음과 같다. 분할표를 작성하였을
medistat.tistory.com
도수분포표에 들어가는 숫자는 '정수'인 이산 변수인데 카이 제곱 분포에는 연속 변수가 사용된다. 이산 분포를 연속 분포에 근사하면서 발생하는 문제를 해결하기 위해 고안된 것이 "연속성 수정(Yates's correction for continuity)"이다. 쉽게 말해 20대 성인의 평균 나이는 20살이 아니라 25살이라고 보는 것이 합당하다는 이야기인데, 더 자세한 내용이 알고 싶은 독자들은 이전 포스팅을 참고하길 바란다.
[이론] 연속성을 수정한 카이 제곱 검정 (Chi-squared test with Yates's correction for continuity)
[이론] 연속성을 수정한 카이 제곱 검정 (Chi-squared test with Yates's correction for continuity) 이 글을 읽기 전에 이전 포스팅을 읽고 오길 권한다. 2022.08.29 - [통계 이론] - [이론] 카이..
medistat.tistory.com
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.29)
분석용 데이터 (update 22.08.29)
2022년 08월 29일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법 1) 엑셀 파일 2) CSV 파일 3) 코드북
medistat.tistory.com
시작하기 위해 라이브러리를 만들고, 파일을 불러온다.
라이브러리 만드는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 라이브러리 만들기 - LIBNAME
파일 불러오는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 데이터 불러오기 및 저장하기 - PROC IMPORT, PROC EXPORT
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
코드
연속성을 수정한 카이 제곱 검정을 시행하는 코드는 다음과 같다. (일반 카이 제곱 검정과 100% 일치한다)
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL/CHISQ NOFREQ NOPERCENT NOROW NOCOL EXPECTED;
RUN;PROC FREQ DATA=hong.df; 분할표 분석을 시작하고 Data는 hong 라이브러리의 df 파일을 이용한다.
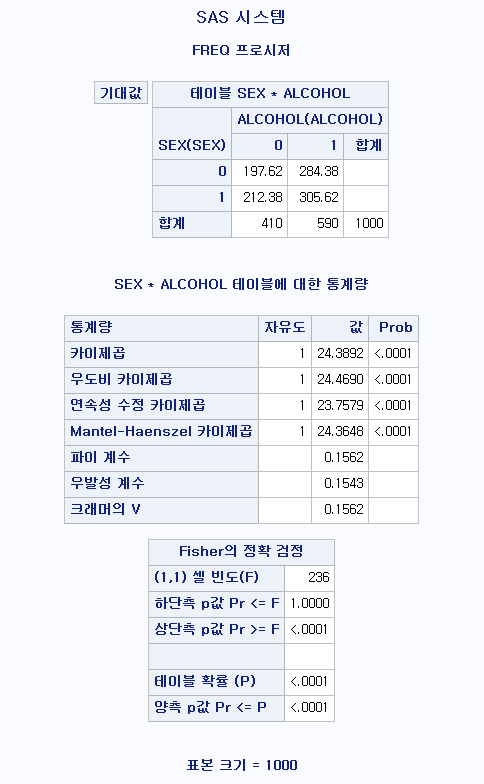
TABLE SEX*ALCOHOL/CHISQ NOFREQ NOPERCENT NOROW NOCOL EXPECTED; : SEX와 ALCOHOL의 분할표를 작성하고 카이제곱 검정을 시행한다. 빈도, 백분율, 행백분율, 열백분율은 나타내지 말고 기댓값(기대 빈도)을 나타낸다.
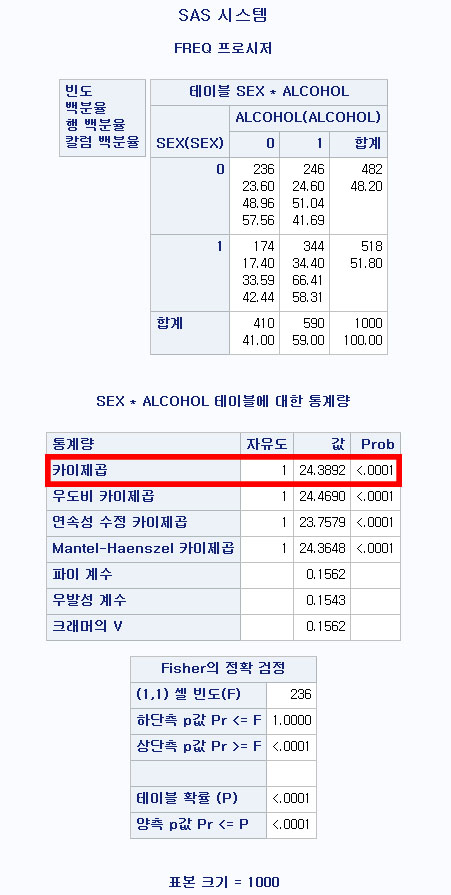
결과
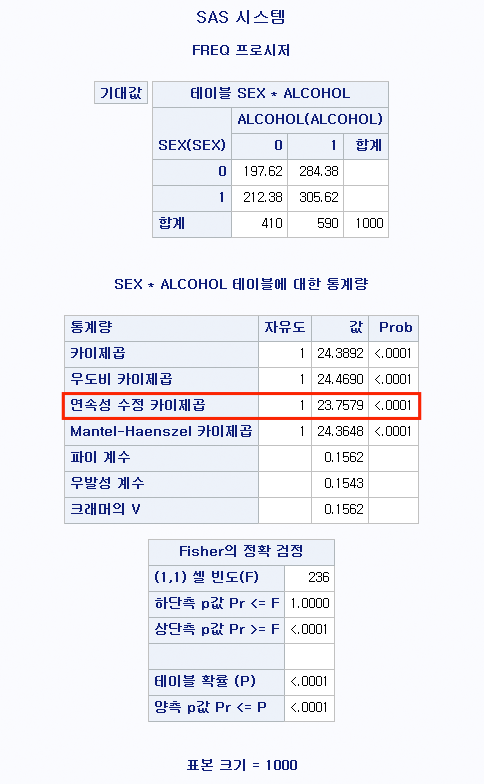
해석
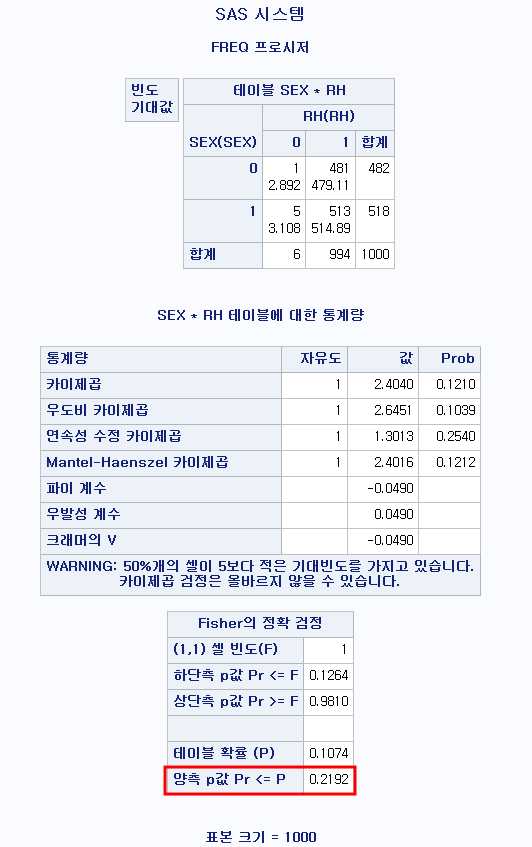
모든 셀에서 기대 빈도가 5 이상이므로 카이 제곱 검정을 시행하는 데에 문제가 없다.
연속성 수정한 카이 제곱 검정 결과 p-value <0.0001으로 성별과 음주 여부에는 유의미한 관계가 있다.
일반적인 카이 제곱 검정량 (24.3892) 보다 낮아 보수적인 통계량임을 알 수 있다.
SAS 연속성 수정 카이 제곱 검정 (Yates's correction for continuity) 정복 완료!
작성일: 2022.08.30.
최종 수정일: 2022.08.30.
이용 프로그램: SAS v9.4
운영체제: Windows 10
'범주형 자료 분석 > SAS' 카테고리의 다른 글
| [SAS] 피셔 정확 검정 - PROC FREQ (0) | 2022.08.29 |
|---|---|
| [SAS] 카이 제곱 검정 - PROC FREQ (2) | 2022.08.19 |