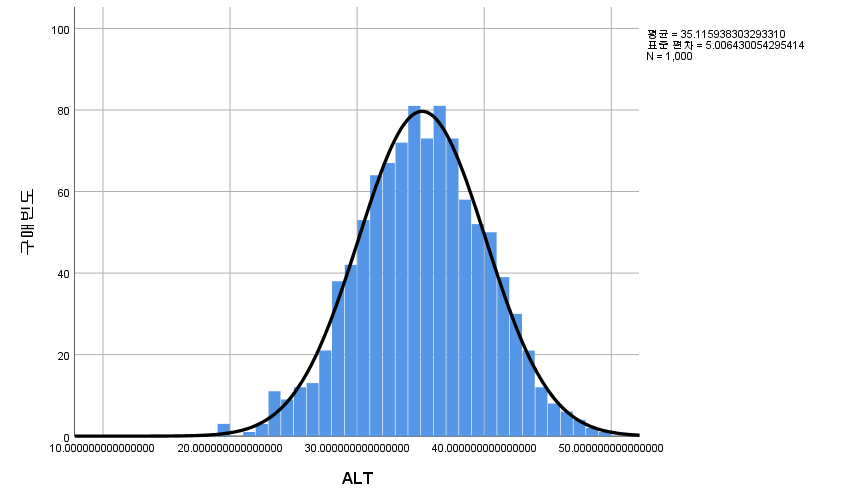
[SPSS] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등)
1,000명으로 어떤 연구를 했다고 하자. 그들의 키, 몸무게 등 지표들은 서로 다를 것이다. 논문의 저자가 이 모든 것을 독자들에게 보여주고자 한다면 행이 1,000인 표를 제시해야 할 것이다. 그렇게 큰 표를 실어줄 저널이 없기도 하거니와, 독자들이 보기에도 한눈에 들어오지 않는다. 그 대신 키의 '평균', 몸무게의 '평균'을 제시하면 한눈에 들어오니 보기가 좋다. 연속 변수는 평균, 표준편차 등으로 요약을 하여 보여주고, 범주형 자료 (흡연 여부, 음주 여부 등)는 도수분포표 혹은 분할표로 제시하게 된다. 분할표를 작성하는 방법은 다음 링크에서 확인할 수 있다.
2022.09.06 - [기술 통계/SPSS] - [SPSS] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기
어떤 지표로 요약해줄 것인가?
1) 정규성을 따를 때: 평균 및 표준편차
어떤 변수가 정규 분포를 따른다고 할 수 있다면, 평균과 표준편차만 알면 된다. 단 두 개의 지표만 있으면 전체 분포를 알아낼 수 있기 때문이다. (정규성을 따르는지는 정규성 검정으로 확인할 수 있으며 정규성 검정을 하는 방법은 다음 링크에서 확인할 수 있다.)
2022.08.11 - [기술 통계/SPSS] - [SPSS] 정규성 검정
2) 정규성을 따르지 않을 때: 중위수, 최댓값, 최솟값, 분위수, 사분위 범위 등
정규성을 따르지 않는다면 평균과 표준편차를 안다고 해도 전체 분포를 알아낼 수는 없다. 따라서 분포에 대한 직접적인 정보를 주는데, 예를 들어 '하위 25%에 위치하는 사람의 ALT값은 얼마인가?' 등을 제시하는 것이다. 그런 지표로는 중위수, 최댓값, 최솟값, 분 위수, 사분위 범위 등이 있다.
이번 포스팅에서는 이 모든 지표들 (평균, 표준편차, 표준오차, 중위수, 최댓값, 최솟값, 분위수, 사분위 범위 등)을 구하는 법에 대해 소개할 것이다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.29)
분석용 데이터 (update 22.08.29)
2022년 08월 29일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법 1) 엑셀 파일 2) CSV 파일 3) 코드북
medistat.tistory.com
먼저 데이터를 불러온다. 데이터를 불러오는 방법은 다음 글을 확인하길 바란다.
2022.08.04 - [통계 프로그램 사용 방법/SPSS] - [SPSS] 데이터 불러오기 및 저장하기
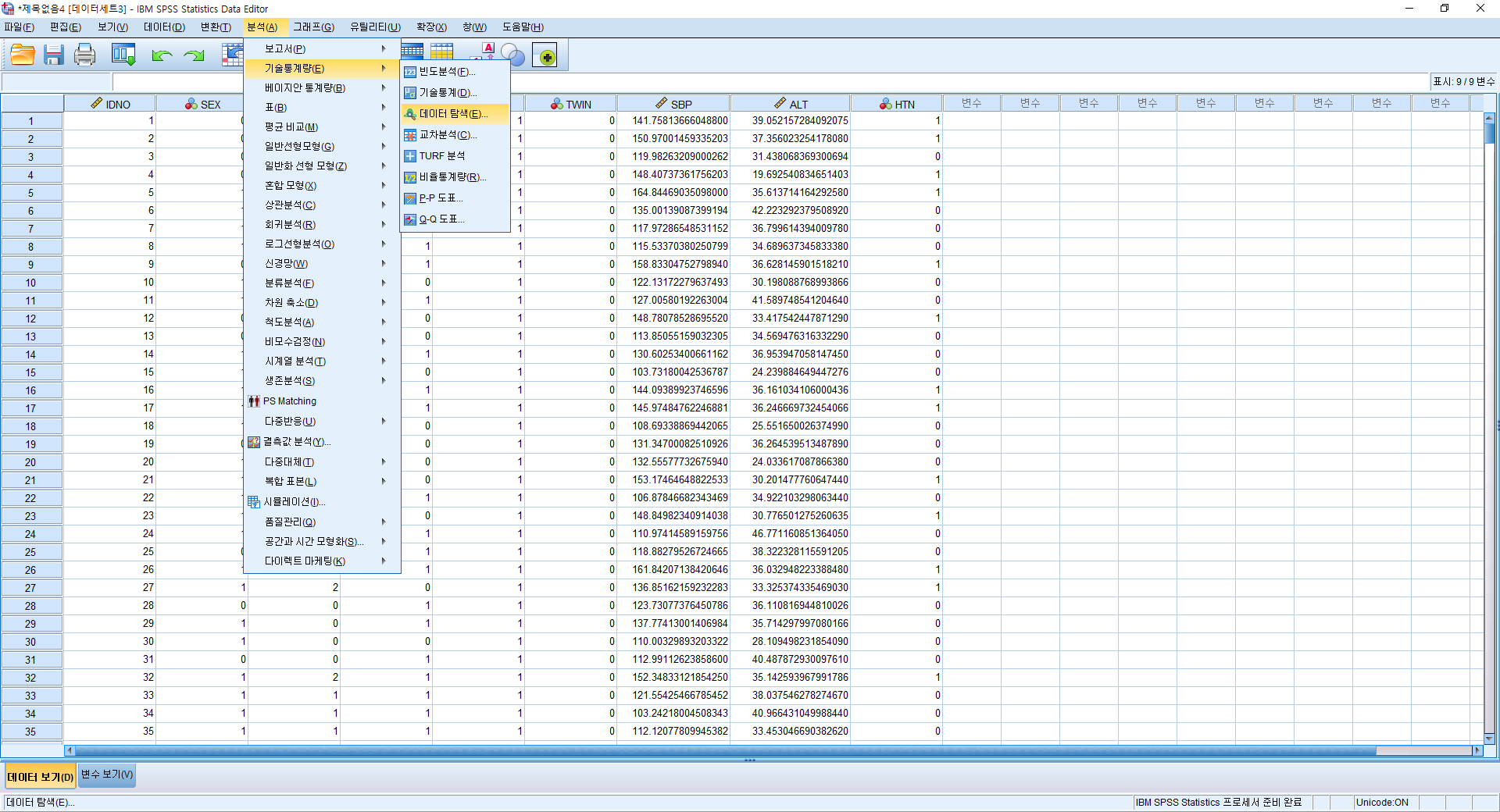
SPSS에서는 기술 통계량을 구하는 곳이 세 군데로 나누어져 있다. 일부 기술 통계량은 중복되어 있어서 여러 곳에서 구할 수도 있다.
분석(A)>기술통계량(E)>
1) 빈도분석(F)
2) 기술통계(D)
3) 데이터 탐색(E)
각 기술 통계량을 구할 수 있는 곳을 정리해놓은 표는 다음과 같다.
| 빈도분석 | 기술통계 | 데이터 탐색 | |
| 대상자 수 | O | O | O |
| 결측치 수 | O | X | O |
| 평균 | O | O | O |
| 표준편차 | O | O | O |
| 분산 | O | O | O |
| 표준오차 | O | O | O |
| 최솟값 | O | O | O |
| 최댓값 | O | O | O |
| 중위수 | O | X | O |
| 최빈값 | O | X | X |
| 평균의 신뢰구간 | X | X | O |
| 사분위수 | O | X | O |
| 사분위범위 | X | X | O |
| 백분위수 | O | X | △ (숫자 지정불가) |
각 방법에 따라 하나씩 살펴보도록 한다.
빈도분석
1) 분석(A)>기술통계량(E)>빈도분석(F)
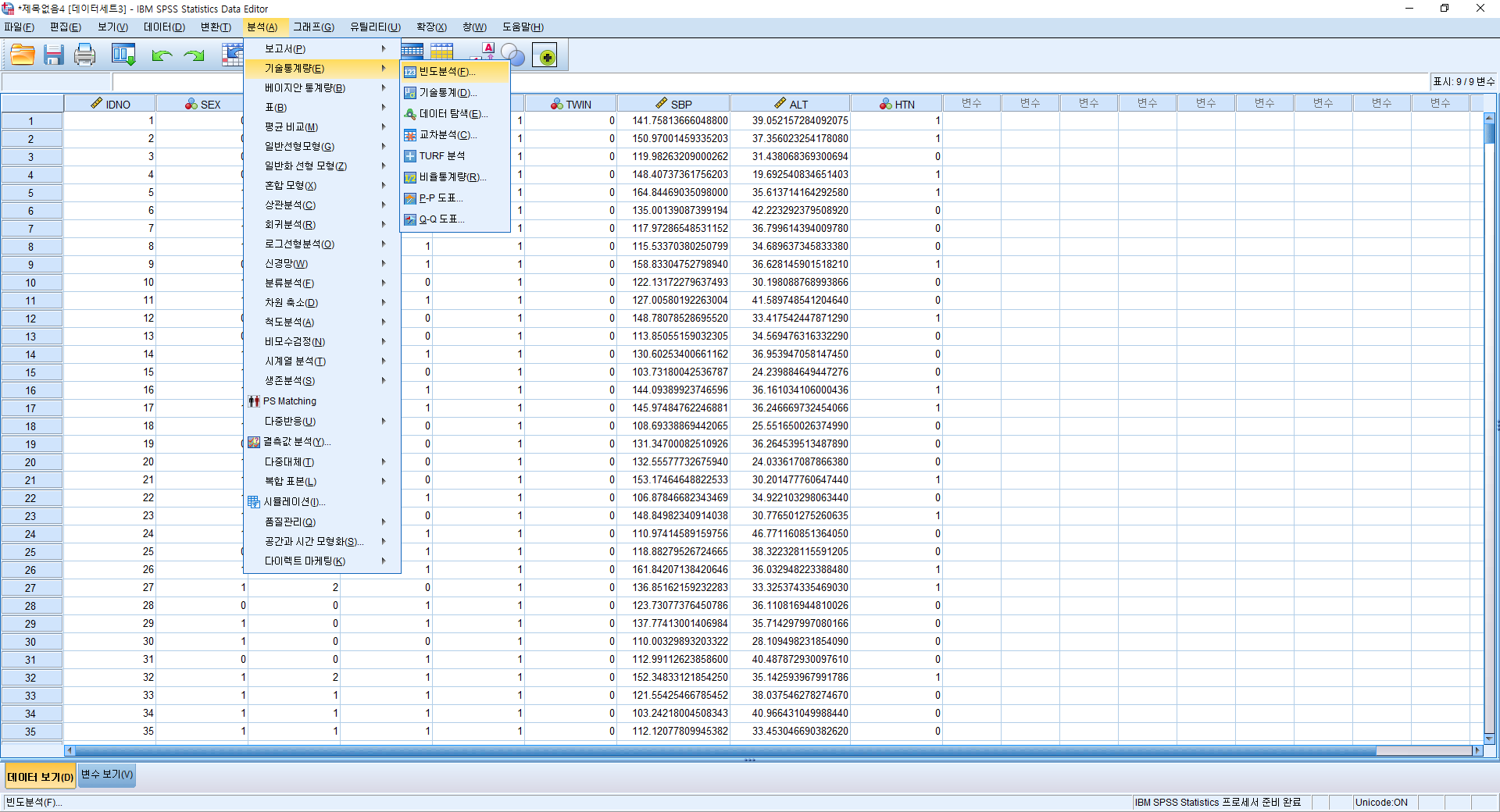
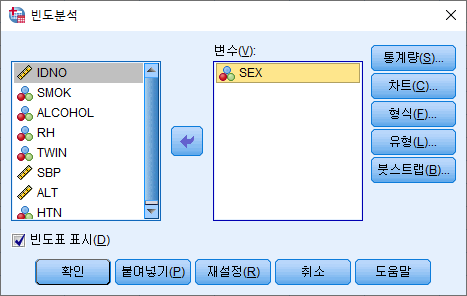
2) 분석하고자 하는 변수 (ALT)를 오른쪽으로 옮기고 "통계량(S)"를 누른다.
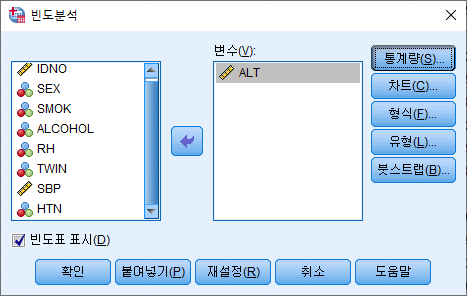
3) 원하는 통계량 박스를 체크한다. 백분위수를 구하고자 한다면 원하는 백분위 숫자를 입력한 뒤 "추가(A)"를 누른다. 그다음 "계속(C)"를 누른다.
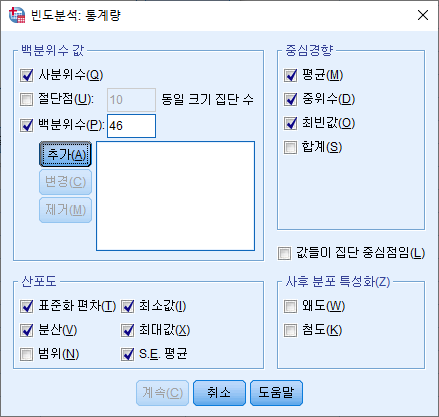
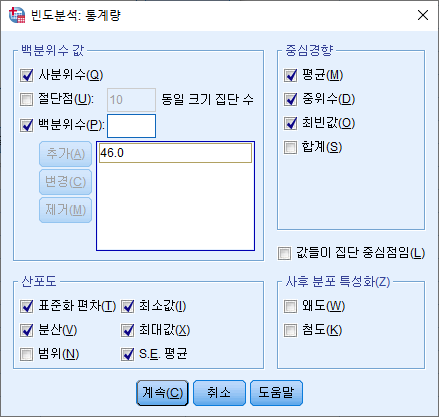
4) 연속 변수를 분석하는 경우 "빈도표 표시(D)"박스는 반드시 해제하고, "확인" 버튼을 누른다.
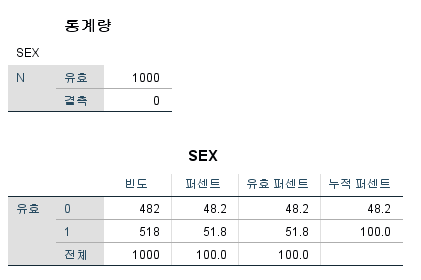
결과
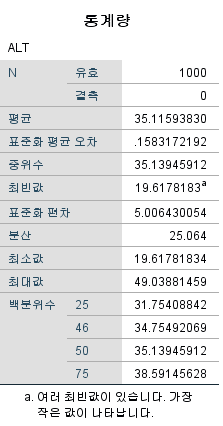
나와있는 값은 위에서부터 순서대로 다음과 같다.
대상자수
결측치
평균
표준오차
중위수
최빈값
표준편차
분산
최솟값
최댓값
1사분위수
46백분위수
2사분위수(=중위수)
3사분위수
하지만 최빈값의 경우 유의해야 한다. 최빈값이 여러 개일 경우 아래 footnote와 같이 "a. 여러 최빈값이 있습니다. 가장 작은 값이 나타납니다."라고 나온다. 즉 지금 표기된 최빈값은 최빈값이 아니므로 신뢰해서는 안 된다는 이야기다.
최빈값이 여러 개라는 것은 다음과 같은 상황을 의미한다.
5개의 숫자 (1, 2, 3, 4, 5)가 있다면 모두 1개씩 있으므로 어떠한 것도 최빈값이라고 할 수 없다.
5개의 숫자 (1, 2, 2, 3, 3)가 있다면 2와 3 둘 다 2개씩 있으므로 2와 3 둘 다 최빈값은 아니다. 즉 최빈값이 없다.
사분위수는 SAS, SPSS, R의 결과가 서로 다를 수 있다. 왜냐하면 각 프로그램에서 사분위수를 구하는 방법이 다를 수 있기 때문이다. 각 프로그램에는 사분위수를 구하는 여러가지 방법이 내장되어 있으며, 골라서 사용할 수도 있다.
SAS의 사분위수 확인하기: 2022.09.23 - [기술 통계/SAS] - [SAS] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등) - PROC UNIVARIATE, PROC MEANS
R의 사분위수 확인하기: 2022.09.27 - [기술 통계/R] - [R] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등)
기술통계
1) 분석(A)>기술통계량(E)>기술통계(D)
2) 분석하고자 하는 변수 (ALT)를 오른쪽으로 옮기고 "옵션(O)"를 누른다.
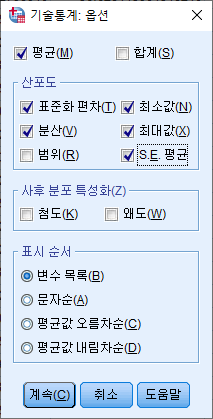
3) 원하는 통계량 박스를 체크하고 "계속(C)"를 누른다.
4) "확인" 버튼을 누른다.
결과

왼쪽에서부터 나오는 통계량을 차례대로 적으면 다음과 같다.
대상자 수
최솟값
최댓값
평균
표준오차
표준편차
분산
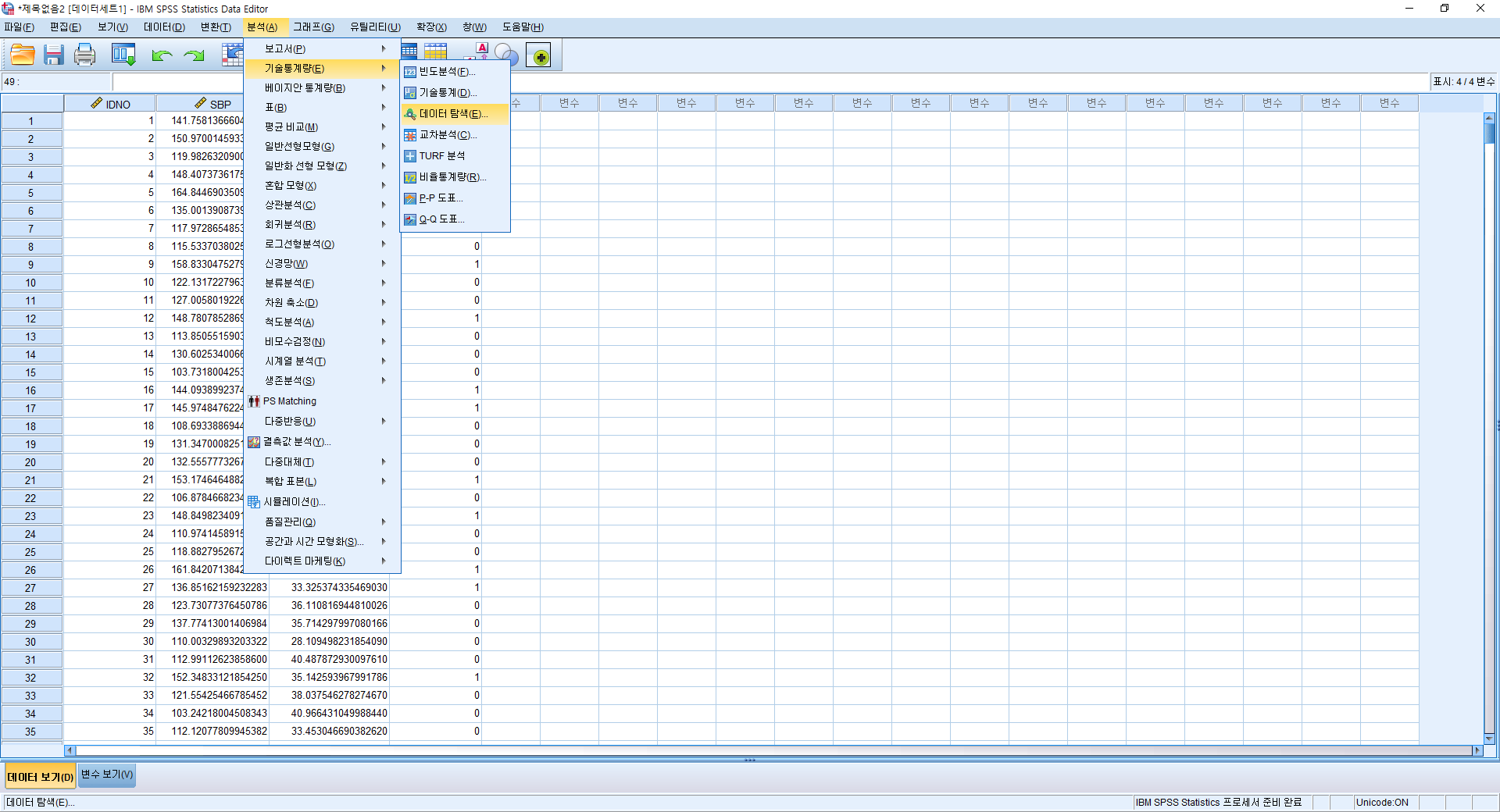
데이터 탐색
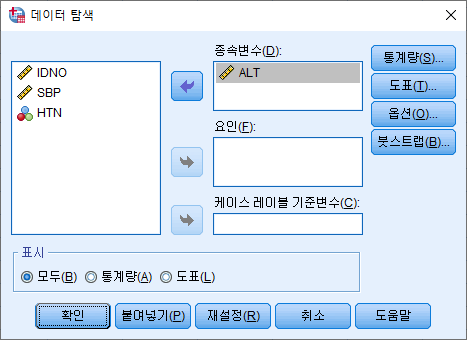
1) 분석(A)>기술통계량(E)>데이터 탐색(E)
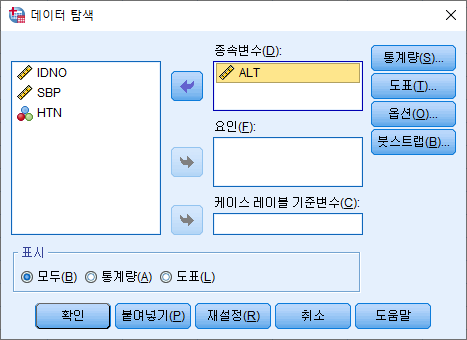
2) 분석하고자 하는 변수 (ALT)를 오른쪽으로 옮기고 "통계량(S)"를 누른다.
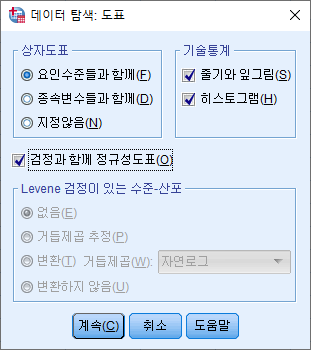
3) "백분위수(P)" 박스를 체크하고 "계속(C)"을 누른다. 신뢰구간 %를 바꾸고 싶다면 원하는 숫자를 적으면 된다.
4) "확인"을 누른다
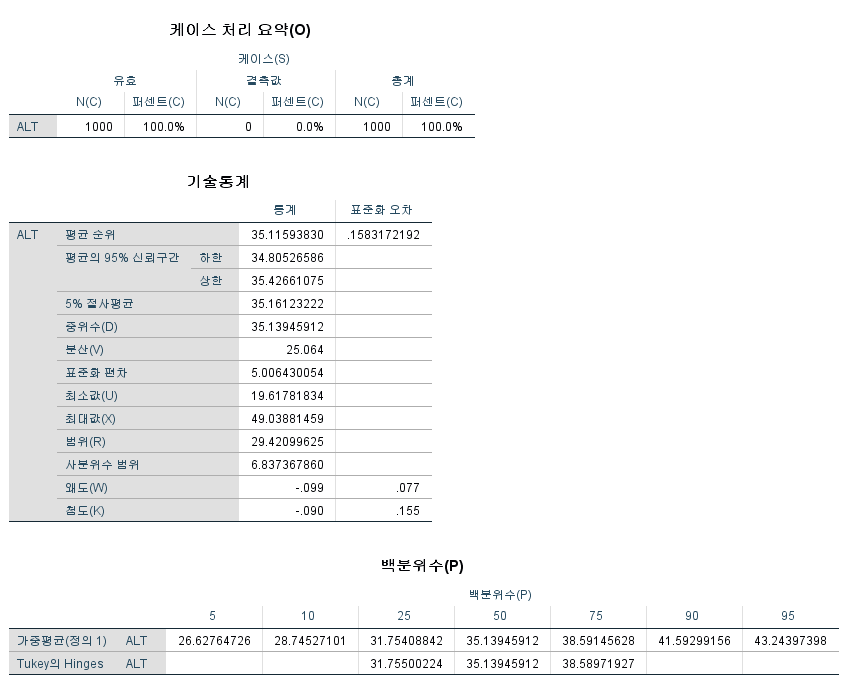
결과
조건에 따른 기술 통계량 산출하기
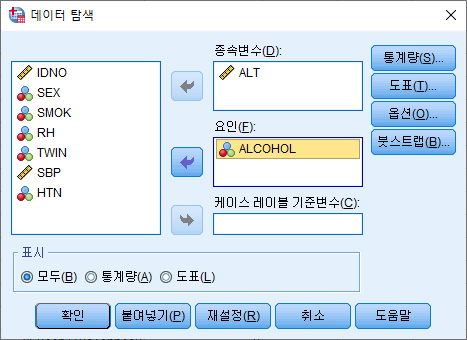
만약 음주 여부에 따른 ALT의 기술 통계량을 산출하고자 한다면 "데이터 탐색"의 "요인"을 사용해야 한다. 요인에 "ALCOHOL"을 넣어주면 된다.
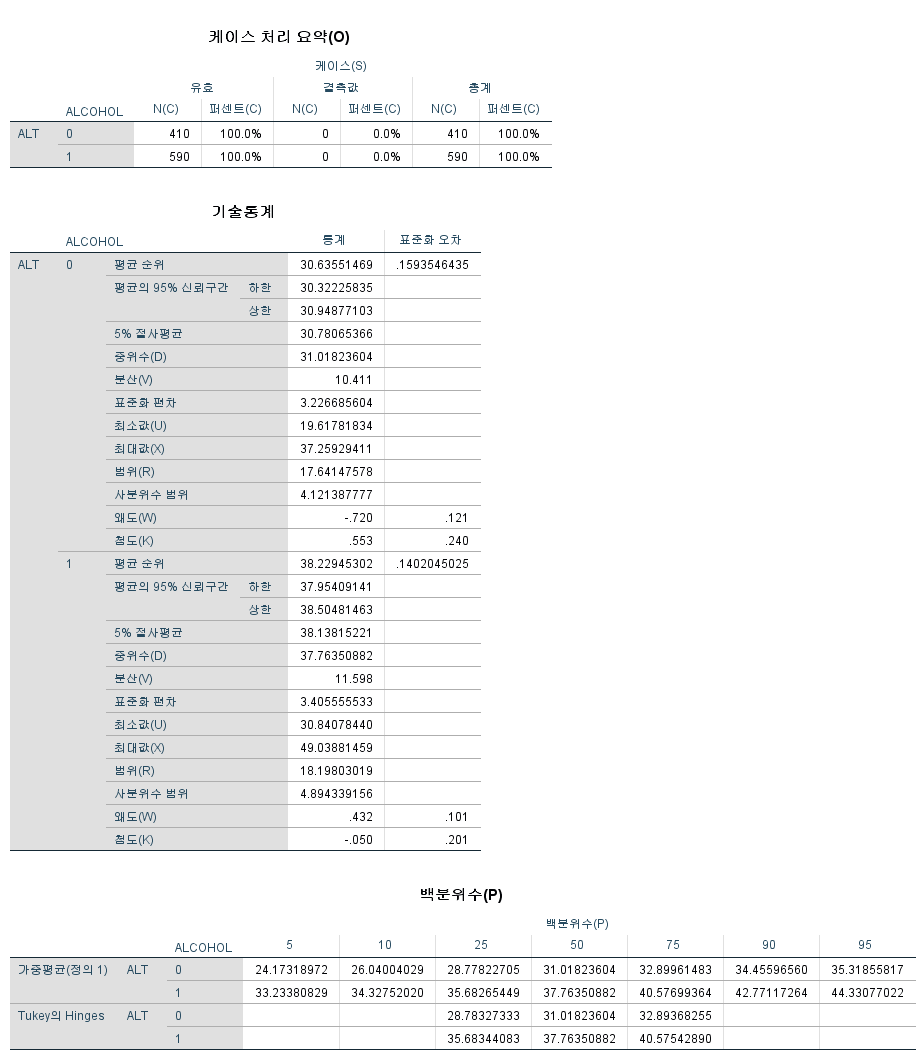
결과
결과가 ALCOHOL 값에 따라 따로따로 산출되는 것을 알 수 있다.
만약 데이터 탐색에서 제공하지 않는 "최빈값"이나 "백분위수"를 음주 여부에 따라 구하고자 한다면 어떻게 해야 할까? SPSS의 "케이스 선택" 기능을 사용하여 ALCOHOL=0 혹은 ALCOHOL=1인 사람만 추려내어 빈도 분석을 시행하면 된다.
케이스 선택을 하는 방법은 다음 글에서 확인할 수 있다.
2022.09.29 - [통계 프로그램 사용 방법/SPSS] - [SPSS] 조건에 맞는 데이터만 선택하기
SPSS 기술통계 정복 완료!
작성일: 2022.09.29.
최종 수정일: 2022.09.29.
이용 프로그램: IBM SPSS v26
운영체제: Windows 10
'기술 통계 > SPSS' 카테고리의 다른 글
| [SPSS] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 (0) | 2022.09.06 |
|---|---|
| [SPSS] 고급 Q-Q Plot - Van der Waerden, Rankit, Tukey, Blom (0) | 2022.08.18 |
| [SPSS] 정규성 검정 (0) | 2022.08.11 |