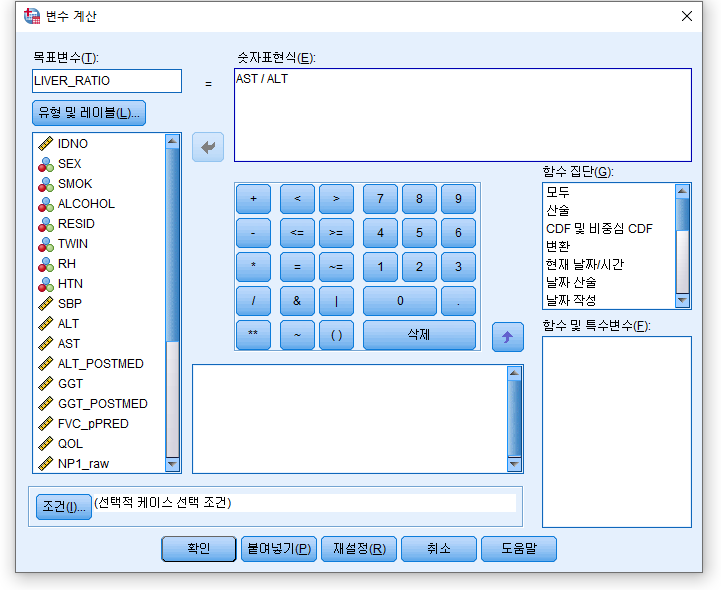
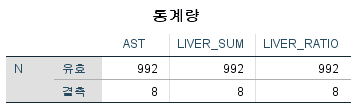
#4) 나누기 df$LIVER_RATIO=df$AST/df$ALT : AST를 ALT로 나누어 그 값을 LIVER_RAIO라는 변수에 저장해라
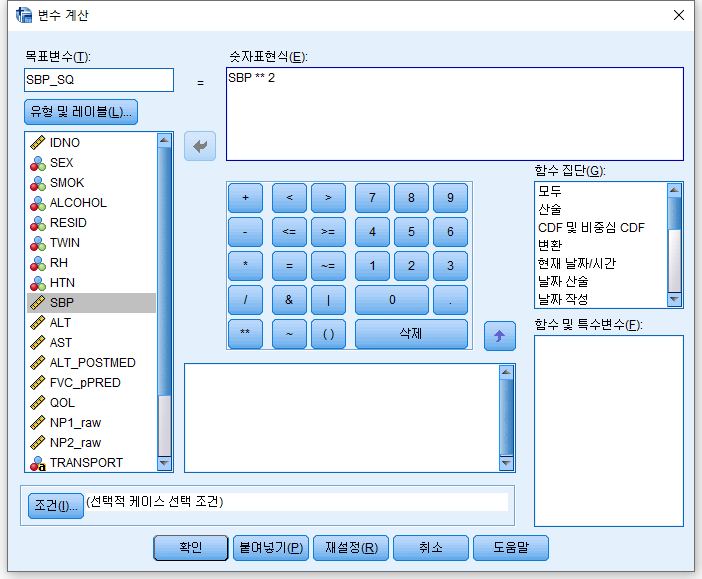
#5) 거듭제곱 (승) df$SBP_SQ=df$SBP**2 : SPB를 제곱하여 SBP_SQ에 저장해라. 만약 세제곱을 원한다면 "SBP**3"을 사용하면 된다.
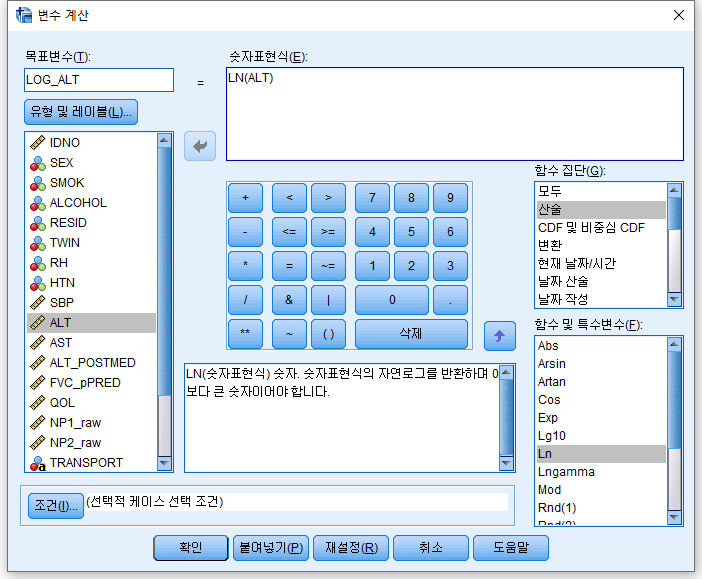
#6) 로그 (log) df$LOG_ALT=log(df$ALT) : ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 e다. df$LOG10_ALT=log(df$ALT, base=10): ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 10이다. df$LOG7_ALT=log(df$ALT)/log(7): ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 7이다. 원하는 숫자를 밑으로 하고 싶으면 7이 아닌 원하는 숫자를 적으면 된다.
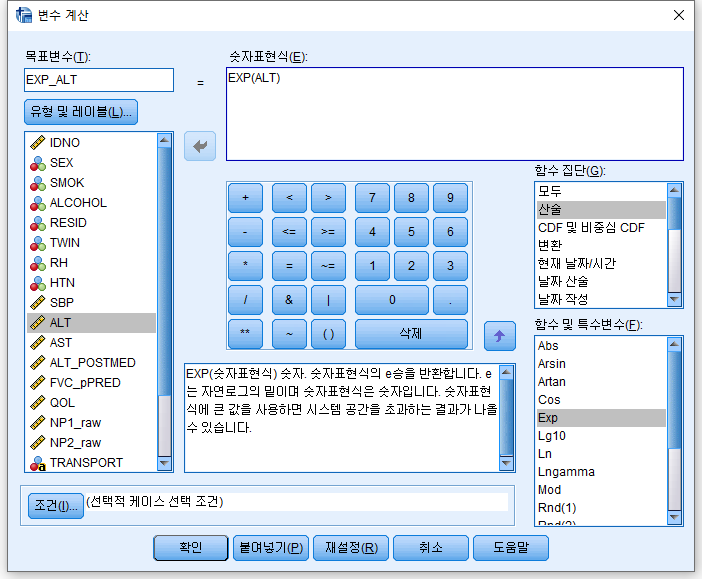
#7) 지수 df$EXP_ALT=exp(df$ALT): e의 ALT승(eALT)을 EXP_ALT에 저장해라. df$EXP10_ALT=exp(df$ALT*log(10)): 10의 ALT승(10ALT)을 EXP10_ALT에 저장해라. 만약 10이 아닌 5의 ALT승(5ALT)를원하면 "log(5)"를 사용하면 된다.
is.na(df) : 결측치는 "TRUE"를, 결측치가 아니면 "FALSE"를 반환하는 함수를 데이터 df에 적용하라
결과
IDNO SEX SMOK ALCOHOL RESID TWIN RH HTN SBP ALT AST ALT_POSTMED FVC_pPRED TRANSPORT
[1,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[2,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[3,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[4,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[5,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[6,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[7,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[8,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[9,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE[10,]FALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSEFALSE
결과창 중 일부만 가져왔다. 1000명에 대한 데이터이므로 행의 개수는 1000개인데 그 중 10개만 가져온 것이다.
결측치는 TRUE로 반환했을 것인데, 여기까지는 결측치가 보이지 않는다.
결측치가 몇 개인지 알고 싶은데, 이 1000개를 들여다보는 것은 말은 안 된다. 이때 다음 코드를 쓰면 개수를 구할 수 있다.
코드 - 결측치 개수 확인
sum(is.na(df))
sum(is.na(df)) : is.na(df)에서 TRUE인 것의 개수를 계산하라.
결과
8
8개가 결측치임을 알 수 있다.
그럼 만약에 변수별로 결측치의 개수를 확인하고 싶다면 어떻게 해야할까? 만약 AST의 결측치 개수를 보고 싶다면 다음 코드를 시행하면 된다.
[R] 변수의 유형 (타입, type) 확인 및 변경 - as.factor(), as.numeric(), str()
변수는 보통 다음 네 가지의 종류로 나누곤 한다.
1) 명목 척도: 범주형, 순서 없음
예시) 성별 - "남성", "여성"
2) 순서 척도: 범주형, 순서 있음
예시) 암의 병기 - "1기", "2기", "3기", "4기"
3) 등간 척도: 연속형, 곱셈 불가
예시) IQ 점수 - IQ가 150인 사람보다 100인 사람은 50점이 더 높다. 100점인 사람이 50점인 사람도 똑같이 50점이 더 높다. 하지만 100점인 사람이 50점보다 두 배 더 똑똑하다고 할 수는 없다.
4) 비율 척도: 연속형, 곱셈 가능
예시) 나이 - "1세", "55세",...
그런데, 학문적으로 저렇게 나눈다고 하여도, 의학 통계를 하는 사람에게 저렇게 세분하는 것이 그렇게까지 중요한 것은 아니다. 단지 우리에게는 범주형 (비연속형, 이산형) 변수와 연속형 변수가 있다는 사실만이 중요하다. 이번 포스팅에서는 변수의 형태를 확인하고, 원하는 경우 다른 유형으로 변경하는 방법에 대해 알아보겠다.
맨 앞에 있는 "IDNO", "SEX", "SMOK", "ALCOHOL", ... ,"TRNASPORT"는 변수의 이름이다.
"IDNO"부터 "FVC_pPRED"까지는 num이라고 적혀있다. 이는 numeric의 약자이며, 숫자형 (연속형) 변수임을 의미한다.
"TRANSPORT"는 chr이라고 적혀있다. 이는 character의 약자이며, 문자형 변수임을 의미한다.
그런데, 서두에 우리는 변수를 범주형, 연속형 변수로 나누기로 했다. 그런데, 숫자로 이루어진 변수는 모두 연속형 변수로 취급되고 있고, 문자가 들어간 변수는 그저 문자형 변수로 취급되고 있다. 그런데 이는 적절하지 않다. 예를 들어 성별을 나타내는 "SEX"변수는 1과 2로 이루어진 범주형 변수다. 여성을 나타내는 0이 남성을 나타내는 1보다 작다고 할 수 없는 것이다. 그저 숫자로 나타낸 것 뿐이다. 여성을 2로 나타낼 수도 있었는데, 그렇다고 하여 여성이 남성보다 크다고 할 수는 없는 것이다.
코드북을 살펴보면 알 수 있지만, 다음과 같이 변수를 구분할 수 있다.
변수명
변수 종류
SEX
범주형
SMOK
범주형
ALCOHOL
범주형
RESID
범주형
TWIN
범주형
RH
범주형
HTN
범주형
SBP
연속형
ALT
연속형
AST
연속형
ALT_POST
연속형
FVC_pPRED
연속형
TRANSPORT
범주형
따라서, "IDNO", "SEX", "SMOK", "ALCOHOL", "RESID", "TWIN", "RH", "HTN", "TRANSPORT"는 범주형 자료로 바꿔주어야 한다. 이럴 때에는 범주형 변수로 바꾸어주는 as.factor() 함수를 사용해야 한다.
위에서 "IDNO", "SEX", "SMOK", "ALCOHOL", "RESID", "TWIN", "RH", "HTN", "TRANSPORT"의 변수 형태는 "num"이었는데 "Factor"로 바뀐 것을 알 수 있다.
"SMOK"는 "Factor w/ 3 levels"이라고 적혀있는데, 이는 "Factor with 3 levels"의 약자로 "범주형 변수인데, 3개의 범주가 존재한다"는 뜻이다. 실제로도 '비흡연자', '과거 흡연자', '현재 흡연자'로 나누어놨으니 맞게 변환된 것을 알 수 있다.
위와 같이 바꾸고 나서 가끔은 다시 연속형 변수로 바꾸거나 문자형 변수로 되돌려야 할 때가 있을 수 있다. 이때는 각각 as.numeric()과 as.character() 함수를 사용하면 된다. "RESID" 변수를 연속형 변수로, "TRANSPORT"변수를 문자형 변수로 되돌려보자.
참고로, as.factor()가 아닌 factor()라는 함수도 존재한다. 기능은 같으나 as.factor()가 특정 상황에서 조금 더 빠르게 작동하여 as.factor()를 본문에서는 소개했지만, factor() 함수를 사용해도 같은 결과를 내니 원하는 것을 사용하면 된다.
df_whtn<-df[df$HTN==1,] df에서 HTN이 1인 행만 추출하여 df_whtn에 저장한다. (행이라서 쉼표 앞에 조건이 붙는다.) df_wohtn<-df[df$HTN==0,]df에서 HTN이 0인 행만 추출하여 df_wohtn에 저장한다. (행이라서 쉼표 앞에 조건이 붙는다.)
"%>%"은 dplyr에서 chain operation이라고 불리는 연산자인데, Ctrl(Cmd for mac) + Shift + M이라는 단축키로 입력할 수 있고, 처음에는 어색해 보일 수 있지만 쓰다 보면 이렇게 편한 연산자가 없다. 이는 생각의 흐름대로 분석을 할 수 있게 해 준다.
이 경우, "데이터 df을 가져와서 HTN이 1인 데이터만 고르는 필터링을 하라."로 이해할 수 있다.
IF AST>=40 THEN AST_S3=0; : AST가 40 이상이면 AST_S3의 값은 0을 부여한다. ELSE IF AST<40 AND AST>=20 THEN AST_S3=1; : AST가 40 미만이면서 20 이상이면 AST_S3의 값은 1을 부여한다. ELSE IF AST<20 THEN AST_S3=2; : AST가 20 미만이면 AST_S3의 값은 2를 부여한다.
DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;IF AST>=40 THEN AST_S3=0;
ELSEIF AST<40 AND AST>=20 THEN AST_S3=1;
ELSEIF AST<20 THEN AST_S3=2;
*AST 결측 여부 확인 변수 만들기;IF AST=. THEN AST_MISS=1;
ELSE AST_MISS=0;
RUN;*분할표 만들기;PROC FREQ DATA=hong.df_new;
TABLE AST_S3 * AST_MISS / NOROW NOCOL NOPERCENT;RUN;
결과
결측값 8개에 AST_S3의 값으로 2가 부여되어 있다. 이는 명백히 "ELSE IF AST<20 THEN AST_S3=2;" 코드에서 기인한 문제다. 즉, SAS는 AST의 결측치에 대해 "AST<20"가 옳다고 (TRUE) 본 것이다. 이를 해결하기 위해서는 코드를 다음과 같이 작성해야 한다. (두 가지 방법 모두 옳다.)
코드
*방법 1: "AST>=0"을 추가하기;DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;IF AST>=40 THEN AST_S3=0;
ELSEIF AST<40 AND AST>=20 THEN AST_S3=1;
ELSEIF AST<20 AND AST>=0 THEN AST_S3=2;
RUN;*방법 2: "AST^=."을 추가하기;DATA hong.df_new;
SET hong.df;
*AST를 기준으로 셋으로 나누기;IF AST>=40 THEN AST_S3=0;
ELSEIF AST<40 AND AST>=20 THEN AST_S3=1;
ELSEIF AST<20 AND AST^=. THEN AST_S3=2;
RUN;
방법 1은 "AST>=0"을 추가하여 결측치는 해당 조건을 만족하지 않게 조정한 것이다.
방법 2는 "AST^=."을 추가하였다. "^="는 같지 않다는 뜻이므로, AST가 결측이 아니라는 뜻을 의미한다.
각 방법에는 세 가지 조건이 존재한다. 방법 2를 기준으로 한다면
조건 1: AST>=40
조건 2: AST<40 AND AST>=20
조건 3: AST<20 AND AST^=.
인데, 결측치는 세 조건 모두 부합하지 않았다. 따라서 결측치는 THEN 뒤로 넘어가 본 적이 없다. THEN 뒤에서는 AST_S3의 값을 배정받으므로 결측치는 AST_S3값을 배정받아본 적이 없는 것이다. 따라서 AST가 결측인 경우에는 AST_S3 또한 결측치가 된다.
>, <, >=, <=등은 실제 코딩을 하다 보면 매우 입력하기 귀찮아지는데, 다음과 같은 영문 부호로 이를 대체할 수도 있다.
연산 부호
영문 부호
뜻
=
EQ
같다
~= ^=
NE
같지 않다
>
GT
크다
<
LT
작다
>=
GE
크거나 같다
<=
LE
작거나 같다
^> ~>
NG
크지 않다
^< ~<
NL
작지 않다
MAX, MIN
최댓값을 구하는 MAX, 최솟값을 구하는 MIN 함수다. 간 기능 지표 (ALT, AST) 중 큰 것을 고른 LIVER_MAX변수와, 작은 것을 고른 LIVER_MIN변수를 새로 만든다고 하자. 그럼 코드는 다음과 같다.
DATA hong.df_new;
SET hong.df;
*최댓값;
LIVER_MAX=MAX(AST, ALT);
*최솟값;
LIVER_MIN=MIN(AST, ALT);
RUN;
LIVER_MAX=MAX(AST, ALT); : AST와 ALT 중 더 큰 값을 LIVER_MAX에 저장하라. LIVER_MIN=MIN(AST, ALT); : AST와 ALT 중 더 작은 값을 LIVER_MIN에 저장하라.
여기에서는 결측치를 어떻게 처리할까?
AST, ALT 둘 중 하나가 결측치인 경우 MIN, MAX모두 결측치가 아닌 값을 반환한다.
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*과거 흡연자 // 현재 흡연자 + 비흡연자로 나누기;IF SMOK IN (0 2) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
IF SMOK IN (0 2) THEN SMOK_S2=0; : SMOK가 0 혹은 2인 경우 SMOK_S2에는 0을 부여한다. ELSE SMOK_S2=1; : 그 외에는 SMOK_S2에 1을 부여한다.
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (1);IF SMOK=0 THEN SMOK_S2=0;
ELSEIF SMOK=1 THEN SMOK_S2=0;
ELSEIF SMOK=2 THEN SMOK_S2=1;
RUN;
IF구문은 다음과 같은 구조를 띤다.
IF {조건1} THEN {실행1} :"조건 1"을 만족하면 "실행1"을 실시한다.
ELSE IF {조건2} THEN {실행2} :"조건 1"을 만족하지 않는 데이터 중 "조건 2"를 만족하면 "실행 2"를 실시한다.
...
ELSE {마지막 실행} :"조건1", "조건 2", ... 를 만족하지 않는 데이터는 "마지막 실행"을 실시한다.
이를 적용하면 다음과 같이 해석할 수 있다.
IF SMOK=0 THEN SMOK_S2=0; : SMOK가 0이면 SMOK_S2는 0이다. ELSE IF SMOK=1 THEN SMOK_S2=0; : SMOK가 0이 아닌 사람 중 SMOK가 1인 사람의 SMOK_S2는 0이다. ELSE IF SMOK=2 THEN SMOK_S2=1;: SMOK가 0, 1이 아닌 사람 중 SMOK가 1인 사람의 SMOK_S2는 0이다.
여기에는 ELSE구문이 없으므로, 모든 조건에 부합하지 못한 데이터가 만약 있다면 그 사람의 SMOK_S2는 결측치로 대체된다.
2) 방법 2
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (2);IF SMOK=0 THEN SMOK_S2=0;
ELSEIF SMOK=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
1) 1000명 전원은 {비흡연자, 과거 흡연자, 현재 흡연자} 셋 중의 하나에 반드시 속한다.
2) 비흡연자에게 SMOK_S2는 0의 값을 부여하고, 과거 흡연자에게 SMOK_S2는 1의 값을 부여한다.
3) 아직 SMOK_S2값을 부여받지 못한 사람은 모두 현재 흡연자이므로 SMOK_S2는 1의 값을 부여한다.
위의 3) 내용을 코드로 옮기면 "ELSE SMOK_S2=1"가 된다.
만약 결측치가 있다면 흡연 정보를 모르는 사람 또한 SMOK_S2의 값은 1이 부여되어 현재 흡연자로 평가받기 때문에 결측치가 있을 때에는 이 코드를 사용하면 안 된다.
3) 방법 3
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (3);IF SMOK=0 OR SMOK=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
OR 연산자를 사용하면 코드가 조금 더 간단해진다.
OR 연산자는 OR 앞뒤로 있는 조건 중 어떤 것이라도 만족하면 옳다고(TRUE)로 인식한다. 우리는 과거 흡연자, 비흡연자 모두 SMOK_S2에서는 0이라는 값을 부여할 것이므로 SMOK변수는 0이든 1이든 둘 중 하나이기만 하면 된다.
IF SMOK=0 OR SMOK=1 THEN SMOK_S2=0;
그래서 SMOK=0, SMOK=1 중 하나라도 만족하면 SMOK_S2에는 0이라는 값을 부여한다는 위 코드를 사용하였다.
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (4);IF SMOK<=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
과거 흡연자와 비흡연자의 SMOK값은 각각 0,1이므로 "SMOK<=1"이라고 쓸 수도 있다.
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (5);IF SMOK IN (0 1) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (6);IF SMOK IN (0:1) THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
방법 5의 IF SMOK IN (0 1) THEN SMOK_S2=0;
- SMOK가 0, 1인 데이터에게만 SMOK_S2의 값으로 0을 부여한다는 뜻이다.
방법 6의 IF SMOK IN (0:1) THEN SMOK_S2=0;
- SMOK가 0 이상 1 이하의 정수인 데이터에게만 SMOK_S2의 값으로 0을 부여한다는 뜻이다.
6) 방법 7
방법 6은 사실 "SMOK가 0 이상이면서 1 이하인 정수 데이터"에게 SMOK_S2의 값으로 0을 부여한 것이다. 이는 AND연산자를 사용한 것과 다름없다. AND 연산자는 AND 앞뒤로 있는 조건을 모두 만족해야 TRUE를 반환하는데, 이 경우 SMOK>=0 AND SMOK<=1 이라는 문구를 사용하면 되는 것이다.
*결측치가 없음을 확인하기;PROC MEANS DATA=hong.df NMISS;
VAR SMOK;
RUN;
DATA hong.df_new;
SET hong.df;
*현재 흡연자 // 과거 흡연자 + 비흡연자로 나누기 (7);IF SMOK>=0 AND SMOK<=1 THEN SMOK_S2=0;
ELSE SMOK_S2=1;
RUN;
AND 연산자는 OR 연산자보다 우선하므로, 괄호를 적절히 치며 사용해야 한다. (사칙연산에서 곱셈이 덧셈보다 우선하는 것과 동일하다)