
[SAS] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - PROC FREQ
수천 명의 정보를 포함한 데이터를 한눈에 요약하고 싶을 때가 많다. 나이, 혈압과 같은 연속형 변수는 평균으로 요약하곤 하는데, 성별이나 음주 여부는 평균을 구할 수 없으니 빈도를 제시하곤 한다. 이를 표로 제시하면 도수분포표 (Frequency table)가 된다. 이를 넘어서 남성 중 음주자가 몇 명인지, 여성중 비음주자가 몇 명인지 알고 싶을 때가 있는데, 이때 사용하는 것이 분할표 (Contingency table)이다. 즉 본 글의 목적은 다음 두 개의 표 내용을 채우는 것이다.
<도수분포표>
| 빈도 | 백분율 | 누적빈도 | 누적백분율 | |
| 여성 | ||||
| 남성 |
<분할표>
| 비음주자 | 음주자 | 합계 | |
| 여성 | |||
| 남성 | |||
| 합계 |
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.18)
분석용 데이터 (update 22.08.18)
2022년 08월 18일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법 1) 엑셀 파일 2) CSV 파일 3) 코드북
medistat.tistory.com
시작하기 위해 라이브러리를 만들고, 파일을 불러온다.
라이브러리 만드는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 라이브러리 만들기 - LIBNAME
파일 불러오는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 데이터 불러오기 및 저장하기 - PROC IMPORT, PROC EXPORT
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
코드
성별과 음주 여부의 분할표를 만드는 코드는 다음과 같다.
-변수
1) SEX: 성별
-0: 여성
-1: 남성
2) ALCOHOL: 음주 여부
-0: 비음주자
-1: 음주자
도수분포표
PROC FREQ DATA=hong.df;
TABLE SEX;
RUN;PROC FREQ DATA=hong.df; : 도수분포표를 구하는 코드를 시작하며, 데이터는 hong 라이브러리 내의 df 파일을 사용한다.
TABLE SEX; : SEX의 도수분포표를 구하라
결과
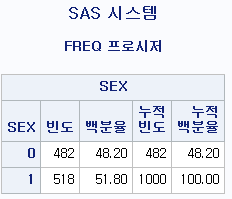
위 결과에 숫자가 너무 많아 지저분해 보이고, 한눈에 잘 들어오지 않을 수 있다. 그런 경우 다음과 같은 옵션을 통해 표시되는 숫자들을 제어할 수 있다.
NOPERCENT: 백분율 표시 안 함
NOCUM: 누적 빈도 및 누적 백분율 표시 안 함
PROC FREQ DATA=hong.df;
TABLE SEX/ NOCUM ;
RUN;결과

분할표
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL;
RUN;PROC FREQ DATA=hong.df; : 분할표를 구하는 코드를 시작하며, 데이터는 hong 라이브러리 내의 df 파일을 사용한다.
TABLE SEX*ALCOHOL; : SEX와 ALCOHOL 변수로 분할표를 만들어라.
- *표시 앞에 오는 변수가 세로축에, 뒤에 오는 변수가 가로축에 놓이게 된다.
결과
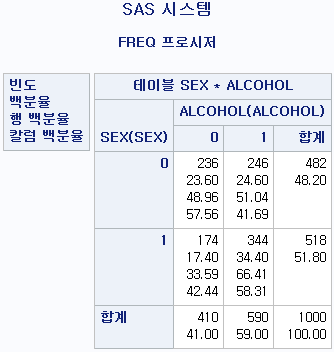
각 셀 안의 내용물은 다음과 같다
(1) 빈도 - 각 셀에 해당하는 인구의 수
| 비음주자 | 음주자 | 합계 | |
| 여성 | 236 23.60 48.96 57.56 |
246 24.60 51.04 41.69 |
482 48.20 |
| 남성 | 174 17.40 33.59 42.44 |
344 34.40 66.41 58.31 |
518 51.80 |
| 합계 | 410 41.00 |
590 59.00 |
1000 100.00 |
(2) 백분율 - 빈도를 전체 인구 (1,000)으로 나눠 %로 나타낸 값
세로 혹은 가로로 더하면 합계의 백분율과 일치하며 백분율의 총합은 100과 같다.
| 비음주자 | 음주자 | 합계 | |
| 여성 | 236 23.60 48.96 57.56 |
246 24.60 51.04 41.69 |
482 48.20 |
| 남성 | 174 17.40 33.59 42.44 |
344 34.40 66.41 58.31 |
518 51.80 |
| 합계 | 410 41.00 |
590 59.00 |
1000 100.00 |
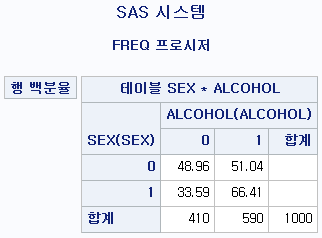
(3) 행 백분율 - 각 행에서 빈도가 차지하는 분율.
- 여성에서 비음주자가 차지하는 분율은 48.96%, 음주자가 차지하는 분율은 51.04%다.
- 남성에서 비음주자가 차지하는 분율은 33.59%, 음주자가 차지하는 분율은 66.41%다.
따라서 행별로 더하면 (=같은 색깔끼리 더하면) 100%가 나오게 된다.
| 비음주자 | 음주자 | 합계 | |
| 여성 | 236 23.60 48.96 57.56 |
246 24.60 51.04 41.69 |
482 48.20 |
| 남성 | 174 17.40 33.59 42.44 |
344 34.40 66.41 58.31 |
518 51.80 |
| 합계 | 410 41.00 |
590 59.00 |
1000 100.00 |
(4) 칼럼 백분율 - 각 열(칼럼)에서 빈도가 차지하는 분율.
- 비음주자에서 여성이 차지하는 분율은 57.56%, 남성이 차지하는 분율은 42.44%다.
- 음주자에서 여성이 차지하는 분율은 41.69%, 남성이 차지하는 분율은 58.31%다.
따라서 열(칼럼) 별로 더하면 (=같은 색깔끼리 더하면) 100%가 나오게 된다.
| 비음주자 | 음주자 | 합계 | |
| 여성 | 236 23.60 48.96 57.56 |
246 24.60 51.04 41.69 |
482 48.20 |
| 남성 | 174 17.40 33.59 42.44 |
344 34.40 66.41 58.31 |
518 51.80 |
| 합계 | 410 41.00 |
590 59.00 |
1000 100.00 |
위 결과에 숫자가 너무 많아 지저분해 보이고, 한눈에 잘 들어오지 않을 수 있다. 그런 경우 다음과 같은 옵션을 통해 표시되는 숫자들을 제어할 수 있다.
NOFREQ: 빈도 표시 안 함
NOPERCENT: 백분율 표시 안 함
NOROW: 행 백분율 표시 안 함
NOCOL: 열(칼럼) 백분율 표시 안 함
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL / NOPERCENT NOROW NOCOL;
RUN;결과
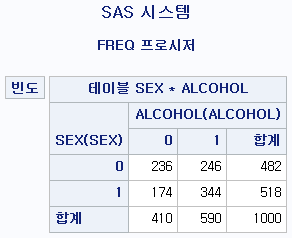
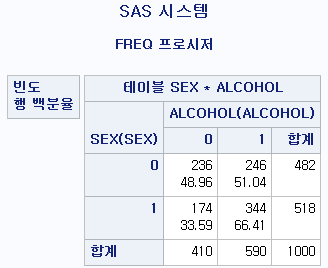
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL / NOPERCENT NOCOL;
RUN;결과
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL / NOFREQ NOPERCENT NOCOL;
RUN;결과
세 개 이상의 변수를 사용하는 분할표
세 개 이상의 변수를 사용하여 분할표를 작성하고 싶을 때가 있다. 다음 두 경우를 생각해보도록 하겠다.
1) 두 가지의 분할표를 작성하는 경우
:성별-음주의 분할표와 성별-고혈압의 분할표를 각각 그리고자 할 때
*방법 1: TABLE 구문 안에 원하는 변수의 조합을 모두 쓴다;
PROC FREQ DATA=hong.df;
TABLE SEX*ALCOHOL SEX*HTN;
RUN;
*방법 2: 공통변수로 묶은 뒤 괄호 안에 나머지 변수를 띄어쓰기로 구분하여 작성한다;
PROC FREQ DATA=hong.df;
TABLE SEX*(ALCOHOL HTN);
RUN;두 개의 코드는 완벽히 똑같은 결과를 제시해준다.
결과
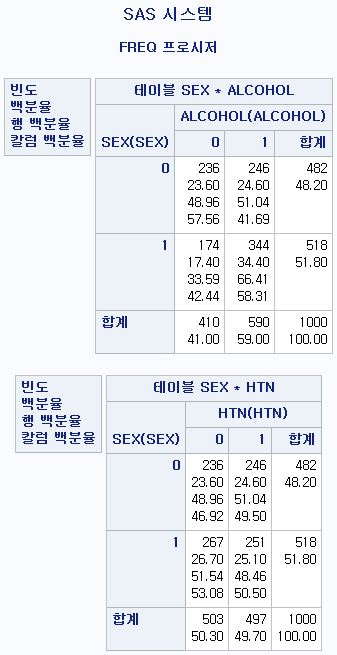
2) 조건에 따라 분할표를 작성하는 경우
:고혈압 여부에 따른 성별-음주의 분할표를 그리고자 할 때
PROC FREQ DATA=hong.df;
TABLE HTN*SEX*ALCOHOL;
RUN;문제 상황처럼 고혈압 여부(HTN)에 따른 성별(SEX)과 음주(ALCOHOL)의 분할표를 그리고자 한다면, 고혈압 여부(HTN)를 TABLE구문 맨 앞에 추가로 붙여준다. 시행하면 다음과 같은 결과를 얻는다.
결과

고혈압이 없는 (HTN=0) 사람의 성별-음주 분할표가 위에 나오고, 고혈압이 있는 (HTN=1) 사람의 성별-음주 분할표가 따라 나오게 된다.
- SAS를 조금 아는 사람이라면 "WHERE 구문을 쓰면 되는데 왜 이렇게 복잡하게 하냐?"라고 이야기할 수도 있지만, 국민건강 영양조사(NHANES, KNHANES) 자료를 쓸 때엔 WHERE 구문이나 BY 구문의 사용이 엄격하게 금지되므로 이 방법이 필수적이다. 물론 이땐 PROC FREQ이 아니라 PROC SURVEYFREQ을 사용하게 된다.
- SAS에는 인구를 나누는 변수를 맨 앞에 쓰지만, R에서는 맨 뒤에 쓴다는 것을 유의해야 한다.
SAS 도수분포표, 분할표 정복 완료!
작성일: 2022.08.18.
최종 수정일: 2022.08.31.
이용 프로그램: SAS v9.4
운영체제: Windows 10
'기술 통계 > SAS' 카테고리의 다른 글
| [SAS] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등) - PROC UNIVARIATE, PROC MEANS (0) | 2022.09.23 |
|---|---|
| [SAS] 정규성 검정 - PROC UNIVARIATE (0) | 2022.08.12 |