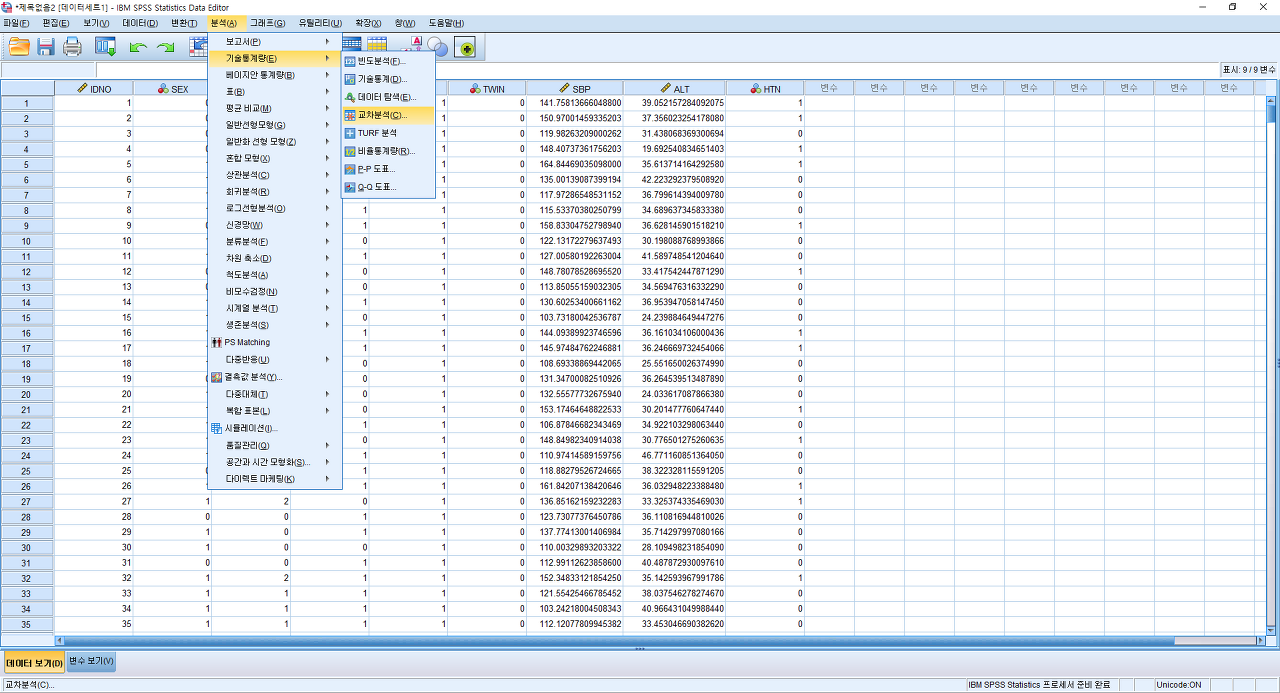
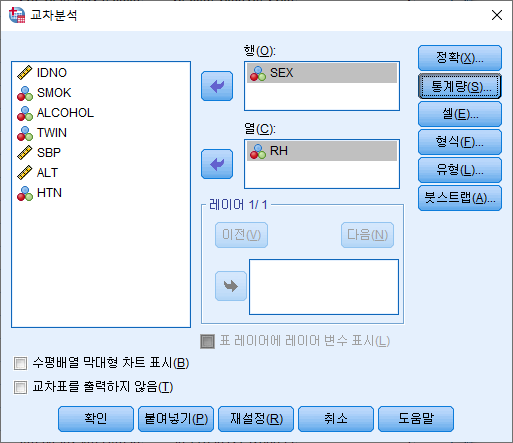
2) 행과 열에 원하는 변수를 넣어주기. 여기에서는 행에 SEX를, 열에 RH을 넣었다. 그리고 통계량(S)를 클릭한다.
3) 카이제곱(H)의 체크박스를 선택한다. "계속(C)"버튼을 누른다.
4) 셀(E)을 클릭한다.
5) 기대빈도 (E) 체크박스를 선택하고 "계속(C)"를 누른다.
6) "확인" 버튼을 눌러 결과를 확인한다.
결과
1) 기대빈도
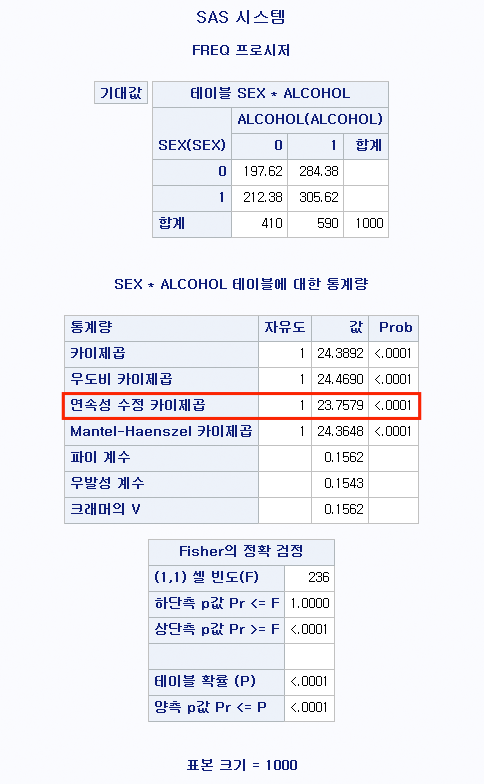
기대 빈도가 5 미만인 셀이 2개 (50%)이므로 카이 제곱 검정이 아닌 피셔 정확 검정 (Fisher's exact test)을 시행해야 한다.
또한, "2 셀 (50.0%)은(는) 5보다 작은 기대 빈도를 가지는 셀입니다."이라고 말하며 카이 제곱 검정이 아닌 피셔 정확 검정을 시행해야 한다고 경고하고 있다.
2) 피셔 정확 검정 결과
피셔 정확 검정의 결과를 볼 때에는 정확 유의확률 (양측검정)의 결과를 보는 것이 일반적이다. 유의성 기준을 0.05로 잡았을 때, 성별과 RH 혈액형 여부는 독립이 아니라고 할 수 없다. 따라서 성별과 RH 혈액형 사이에는 어떠한 관계가 있다고 볼 수 없다. 양측 검정이 아닌 단측 검정을 보아야 할 때도 있다. 이는 대립 가설이 어떤 것이냐에 따라 달라지는데 이에 대한 자세한 내용은 다음 포스팅에서 확인할 수 있다.
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
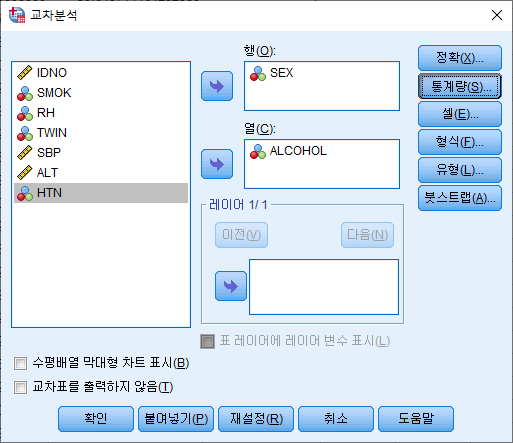
2) 행과 열에 원하는 변수를 넣어주기. 여기에서는 행에 SEX를, 열에 ALCOHOL을 넣었다. 그리고 통계량(S)를 클릭한다.
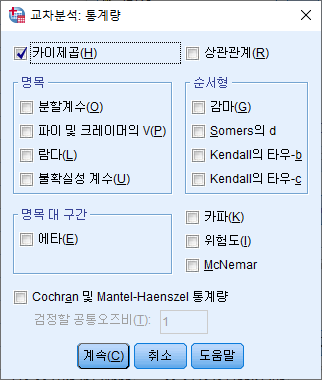
3) 카이제곱(H)의 체크박스를 선택한다. "계속(C)"버튼을 누른다.
4) 셀(E)을 클릭한다.
4) 기대빈도 (E) 체크박스를 선택하고 "계속(C)"를 누른다.
5) "확인" 버튼을 눌러 결과를 확인한다.
결과
1) 기대빈도
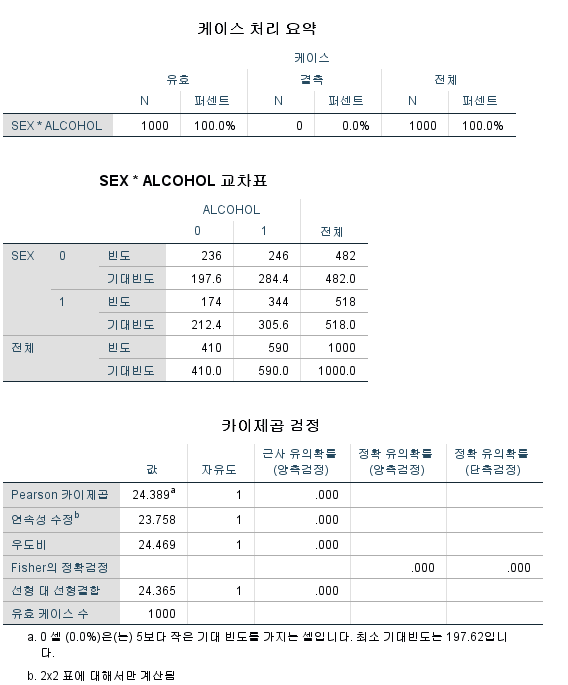
카이 제곱 검정을 시행하기 위한 전제조건은 기대 빈도가 5 미만이 셀이 전체 셀 중 25% 미만이어야 한다는 것이므로 기대 빈도를 산출해 보았고 모두 5 이상이므로 문제가 없었다.
또한, "0 셀 (0.0%)은(는) 5보다 작은 기대 빈도를 가지는 셀입니다."이라고 말하며 카이 제곱 검정을 시행해도 된다고 안심시켜주고 있다.
2) 카이 제곱 검정 결과
카이 제곱 검정의 결과를 볼 때에는 첫 번째 행 "Pearson 카이제곱"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. "0.000"이라고 쓰여있는 것은 "<0.001"을 의미한다. 따라서 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
3) 연속성 수정 카이 제곱 검정 결과 (Chi-squared test with Yates's correction for continuity)
연속성 수정을 하고 싶은 경우 두 번째 행 "연속성 수정"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. p-value는 0.001보다 작으므로 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
CrossTable(df$SEX, df$RH, prop.chisq=FALSE, fisher=TRUE,expected=TRUE, prop.r=FALSE, prop.c=FALSE, prop.t=FALSE) : df에 있는 SEX변수와 RH변수로 분할표를 만들라. 카이 제곱 기여분은 표시하지 말라 (prop.chisq=FALSE), 피셔 정확 검정은 시행하고 셀 별로 기댓값을 산출하라 (fisher=TRUE,expected=TRUE), 행백분율, 열백분율, 백분율은 산출하지 말라 (prop.r=FALSE, prop.c=FALSE, prop.t=FALSE)]
결과
'Cell Contents
|-------------------------|
| N |
| Expected N |
|-------------------------|
Total Observations in Table: 1000
| df$RH
df$SEX | 0 | 1 | Row Total |
-------------|-----------|-----------|-----------|
0 | 1 | 481 | 482 |
| 2.892 | 479.108 | |
-------------|-----------|-----------|-----------|
1 | 5 | 513 | 518 |
| 3.108 | 514.892 | |
-------------|-----------|-----------|-----------|
Column Total | 6 | 994 | 1000 |
-------------|-----------|-----------|-----------|
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 2.403963 d.f. = 1 p = 0.1210283
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 1.30126 d.f. = 1 p = 0.2539832
Fisher's Exact Test for Count Data
------------------------------------------------------------
Sample estimate odds ratio: 0.2135842
Alternative hypothesis: true odds ratio is not equal to 1
p = 0.2191681
95% confidence interval: 0.004505326 1.918452
Alternative hypothesis: true odds ratio is less than 1
p = 0.1264398
95% confidence interval: 0 1.492381
Alternative hypothesis: true odds ratio is greater than 1
p = 0.9809505
95% confidence interval: 0.009115443 Inf
Warning messages:
1: In chisq.test(t, correct = TRUE, ...) :
Chi-squared approximation may be incorrect
2: In chisq.test(t, correct = FALSE, ...) :
Chi-squared approximation may be incorrect
1) Pearson's Chi-squared test ,Pearson's Chi-squared test with Yates' continuity correction
카이 제곱 검정을 시행하는 말은 없었으나, 기댓값을 산출하라는 코드(expected=TRUE)가 있었으므로 카이 제곱 검정은 자동으로 시행한다. 하지만 맨 밑에 경고에서 볼 수 있듯이 카이 제곱 검정 결과는 사용하지 않는 게 좋다.
2) Alternative hypothesis: true odds ratio is not equal to 1 p = 0.2191681
양측 검정의 결과 p-value는 0.2192다.
3) Alternative hypothesis: true odds ratio is less than 1 p = 0.1264398
하단측 p-value는 0.1264다
4) Alternative hypothesis: true odds ratio is greater than 1 p = 0.9809505
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
우리가 봐야 할 곳은 세 번째 줄의 "p-value = 0.2192"이다. 피셔 정확 검정 결과 p-value는 0.2192로 0.05보다 크므로 "성별에 따라 RH혈액형의 분포가 다르다고 할 수 없다."라고 결론지어야 한다.
피셔 정확 검정을 구동하는 또 다른 방법이 있다. 먼저 분할표를 만든 뒤 시행하는 것이다.
freq_sex_rh<-xtabs(~SEX+RH, data=df) : xtabs()함수를 이용하여 SEX와 RH의 분할표를 만들어라. 단 데이터는 df를 사용하라. 만든 것은 freq_sex_rh에 저장하라. table_sex_rh<-table(df$SEX, df$RH) : df의 SEX와 df의 RH로 분할표를 만들어라. 만든 것은 table_sex_rh에 저장하라.
-freq_sex_rh사용한 결과
Fisher's Exact Test for Count Data
data: freq_sex_rh
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
-table_sex_rh사용한 결과
Fisher's Exact Test for Count Data
data: table_sex_rh
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
#상단 측 p-value
fisher.test(df$SEX, df$RH, alternative="greater")
#하단 측 p-value
fisher.test(df$SEX, df$RH, alternative="less")
결과
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.981
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
0.009115443 Inf
sample estimates:
odds ratio
0.2135842
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.1264
alternative hypothesis: true odds ratio is less than 1
95 percent confidence interval:
0.000000 1.492381
sample estimates:
odds ratio
0.2135842
이전 글에서 R의 chisq.test() 함수를 사용하여 카이 제곱 검정을 하는 방법을 소개하였다(2022.08.31 - [범주형 자료 분석/R] - [R] 카이 제곱 검정 - chisq.test()). 하지만 SAS나 SPSS는 분할표와 카이 제곱 검정 결과를 같이 보여주는 데에 반해 R의 chisq.test()는 카이 제곱 검정 결과만 보여주어 불편한 감이 있다. 따라서 분할표와 카이 제곱 검정 결과를 한꺼번에 보여주는 CrossTable() 함수를 이용하여 카이 제곱 검정을 하고자 한다.
카이 제곱 검정은 범주형 변수 간에 분포의 유의미한 차이가 있는지 확인하는 방법이다. 이해할 수 있는 언어로 표현하면 다음과 같다. 분할표를 작성하였을 때 다음과 같다고 하자. (출처 및 분할표 작성법:
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 2.403963 d.f. = 1 p = 0.1210283
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 1.30126 d.f. = 1 p = 0.2539832
Warning messages:
1: In chisq.test(t, correct = TRUE, ...) :
Chi-squared approximation may be incorrect
혹시 걱정되면 "expected=TRUE" 구문을 넣어 기대 빈도를 확인해보면 된다. 이 경우 카이 제곱 검정이 자동으로 실행되므로 "chisq=TRUE"구문이 필요 없게 된다.
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
chisq.test(df$SEX, df$ALCOHOL, correct=FALSE) : df 데이터의 SEX 변수와 ALCOHOL 변수 사이의 카이 제곱 검정을 시행하라. 이때 연속성 수정은 하지 않는다.
결과
Pearson's Chi-squared test
data: df$SEX and df$ALCOHOL
X-squared = 24.389, df = 1, p-value = 7.871e-07
결과에서 중점적으로 봐야할 곳은 "p-value=7.871e-07"로 이는 "p-value가 $7.871\times10^{-7}= 0.0000007871$이다"라는 뜻이다. p-value가 0.05보다 낮으므로 성별과 음주의 분포에는 유의미한 차이가 있다고 결론내릴 수 있다.
왜 "correct=FALSE"?
R의 chisq.test() 함수는 연속성 수정을 하는 것을 디폴트 값으로 갖는다. 따라서 "correct=FALSE"라고 쓰지 않으면 "correct=TRUE"로 받아들이게 된다. 실제로 코드를 돌려보면 다음과 같다.
코드
chisq.test(df$SEX, df$ALCOHOL)
결과
Pearson's Chi-squared test with Yates' continuity correction
data: df$SEX and df$ALCOHOL
X-squared = 23.758, df = 1, p-value = 1.092e-06
보는 바와 같이 "with Yates' continuity correction"이라고 적혀있다. 즉 연속성 수정을 기본적으로 시행하게 된다. 해석 방법은 위의 일반적인 카이 제곱 검정과 같다.
도수분포표에 들어가는 숫자는 '정수'인 이산 변수인데 카이 제곱 분포에는 연속 변수가 사용된다. 이산 분포를 연속 분포에 근사하면서 발생하는 문제를 해결하기 위해 고안된 것이 "연속성 수정(Yates's correction for continuity)"이다. 쉽게 말해 20대 성인의 평균 나이는 20살이 아니라 25살이라고 보는 것이 합당하다는 이야기인데, 더 자세한 내용이 알고 싶은 독자들은 이전 포스팅을 참고하길 바란다.
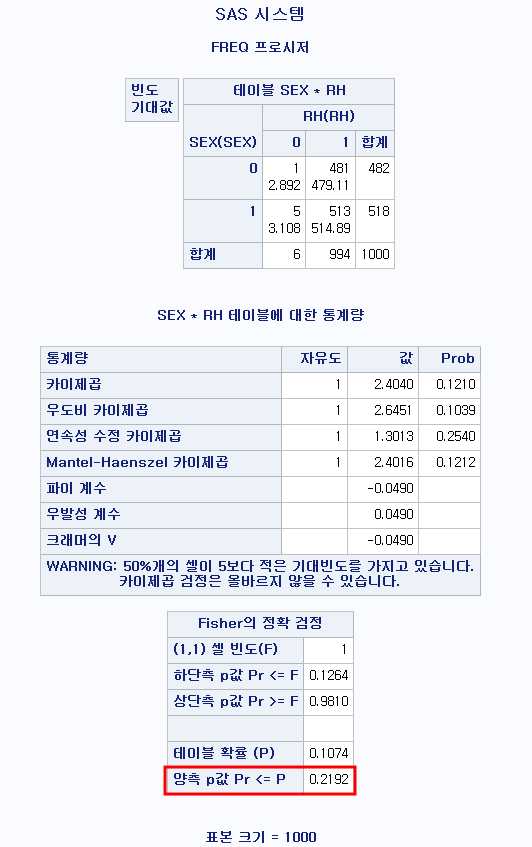
PROC FREQ DATA=hong.df; : 빈도수를 계산하는 코드를 시작하며, 데이터는 hong 라이브러리의 df 파일을 이용한다. TABLE SEX*RH/CHISQ EXPECTED NOROW NOCOL NOPERCENT; : SEX와 RH의 분할표를 계산하며, 카이 제곱 검정을 시행한다. 기대 빈도를 산출하고, 행 백분율, 열 백분율, 백분율은 산출하지 않는다.
"CHISQ" 옵션이 자동으로 피셔 정확 검정 결과까지 산출하므로 카이 제곱 검정을 시행하는 코드와 100% 일치한다. 즉, 굳이 피셔 정확 검정을 시행하는 옵션인 "FISHER"를 적을 필요가 없다.
결과
먼저 기대 빈도 (기댓값)를 산출했는데 기대 빈도가 5 미만인 셀이 두 개가 있다. (2.892와 3.108) 따라서 경고가 뜬다. "WARNING: 50% 개의 셀이 5보다 적은 기대 빈도를 가지고 있습니다. 카이제곱 검정은 올바르지 않을 수 있습니다."즉, 카이제곱 분포가 아닌 아래 나오는 "Fisher의 정확 검정" 표를 참고하라는 말이다.
세 개의 p-value가 산출된다. 1) 하단측 p값 Pr<=F2) 상단측 p값 Pr>=F3) 양측 p값 Pr<=P
1)과 2)는 단측 검정 (One-sided or One-tailed)이고 3)은 양측 검정 (Two-sided or two-tailed)이다. 경우에 따라 단측 검정을 쓰기도 하지만 일반적으로는 양측 검정을 사용한다. 이 p-value는 0.2192로 0.05보다 크므로 귀무가설을 기각하지 못해 "성별에 따라 RH 혈액형의 분포에는 차이가 있다고 할 수 없다."라고 결론이 내려진다. 양측 검정 및 단측 검정에 관한 내용은 다음 글을 확인하길 바란다:2022.08.26 - [통계 이론] - [이론] 피셔 정확 검정 (Fisher's exact test)
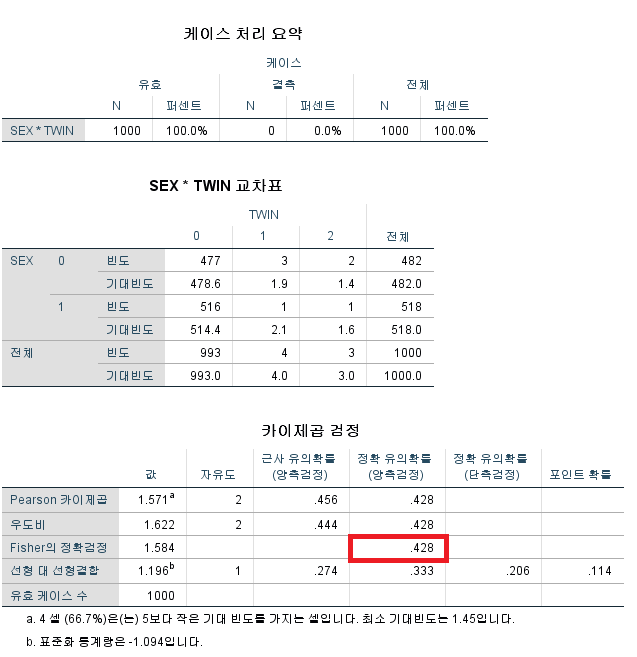
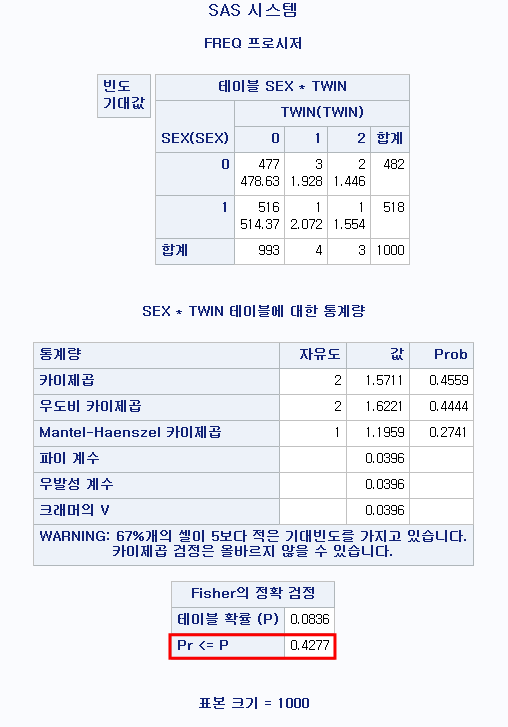
PROC FREQ DATA=hong.df; : 빈도수를 계산하는 코드를 시작하며, 데이터는 hong 라이브러리의 df 파일을 이용한다. TABLE SEX*TWIN/CHISQ EXACT EXPECTED NOROW NOCOL NOPERCENT; : SEX와 TWIN의 분할표를 계산하며, 카이 제곱 검정을 시행한다. 정확 검정도 시행한다. 기대 빈도를 산출하고, 행 백분율, 열 백분율, 백분율은 산출하지 않는다.
2*2 분할표에서만 "CHISQ" 옵션이 자동으로 피셔 정확 검정 결과까지 산출해준다. 따라서 2*2를 넘어서는 분할표에서는 정확 검정을 시행하는 "EXACT"혹은 "FISHER"를 적어야 한다. "FISHER"라는 코드로 검정을 시행하고 결과창에도 "Fisher의 정확 검정"이라고 적혀 있지만 이는 사실 "Freeman-Halton test"다.
결과
2*2 분할표 분석에서 보이는 바와 거의 같은 결과를 내주지만 "Fisher의 정확 검정"에는 양측 검정 결과만이 나온다. 빨간 상자에 있는 값이 p-value다. p>0.05이므로 "성별에 따라 쌍둥이 여부는 어떠한 경향성을 갖는다고 할 수 없다."라고 결론짓게 된다.