[SPSS] 윌콕슨 순위 합 검정, 맨 휘트니 U 검정 (비모수 독립 표본 중앙값 검정: Wilcoxon rank sum test, Mann-Whitney U test)
두 분포의 평균이 다른지 확인하는 방법을 이전에는 독립 표본 T검정 (Two-Sample T test)로 시행했었다. (2022.11.12 - [모평균 검정/R] - [R] 독립 표본 T검정 (Independent samples T-test) - t.test(), var.test(), levene.test()) 하지만 여기에는 중요한 가정이 필요한데, 각각의 분포가 정규성을 따르는 것이다. 하지만 분포가 정규성을 따르지 않는다면 어떻게 해야 할까? 그럴 때 사용하는 것이 Wilcoxon rank sum test (윌콕슨 순위 합 검정)이다. 윌콕슨 순위 합 검정 (Wilcoxon rank sum test)는 이후에 Mann과 Whitney가 개정을 하였고 그때 U 통계량을 사용하므로 맨 휘트니 U 검정(Mann-Whitney U test)이라고도 한다. 또한 세 사람의 이름을 붙여 Wilcoxon-Mann-Whitney Test (WMW test)라고도 한다.
이번 포스팅에서는 윌콕슨 순위 합 검정 (Wilcoxon rank sum test)에 대해 알아볼 것이다.
2) 분석하고자 하는 변수인 GGT을 "종속변수"에 넣고, 음주 여부에 따라 분석할 것이므로 ALCOHOL을 "요인(F)"에 넣는다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
결과
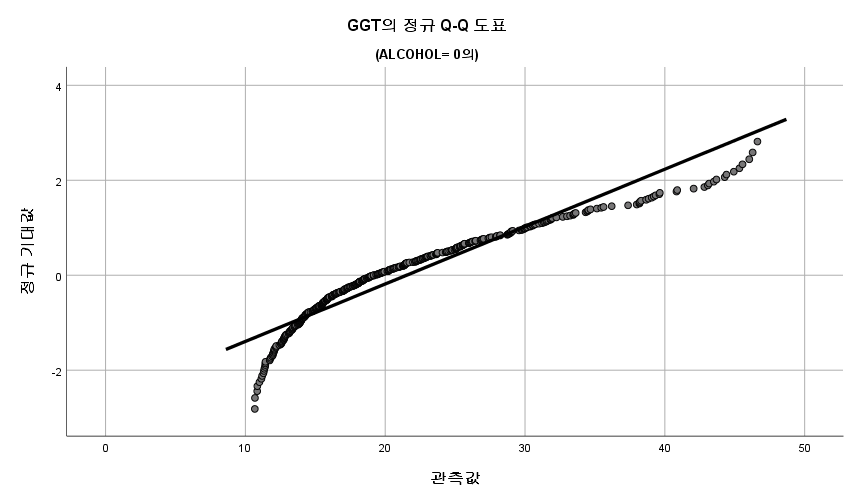
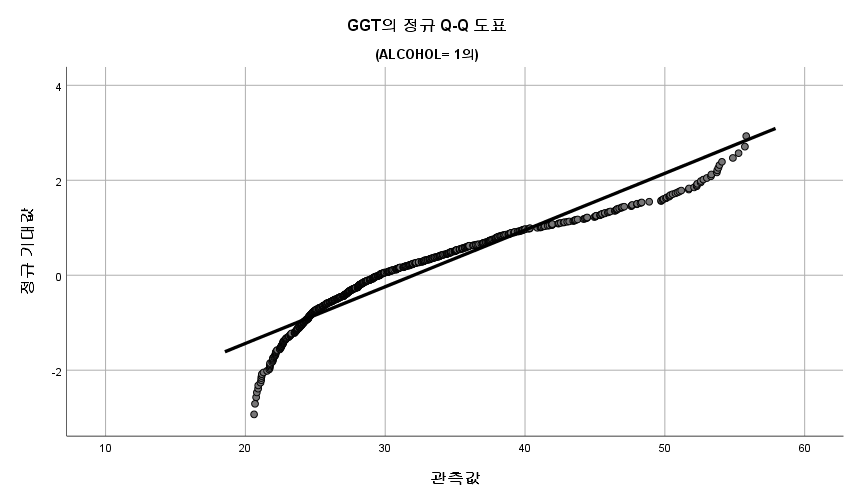
1) Q-Q Plot
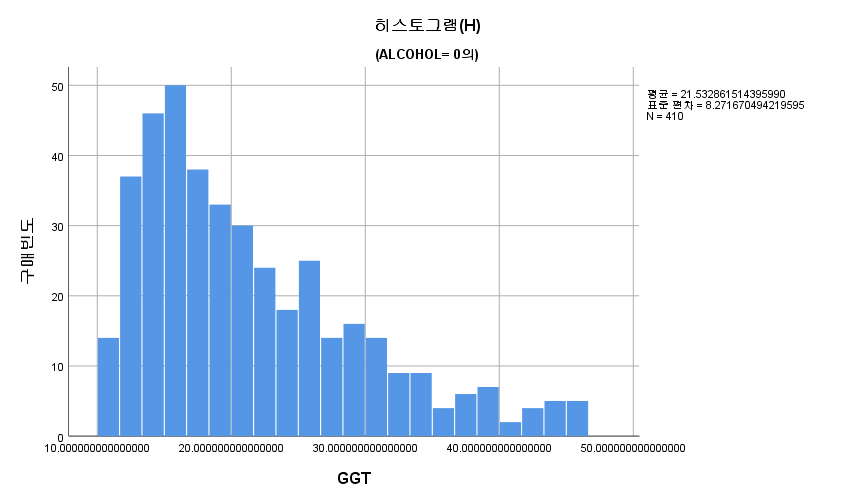
2) 히스토그램
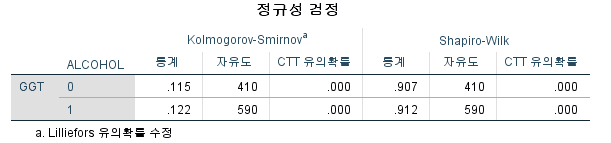
3) Shapiro-Wilk 검정
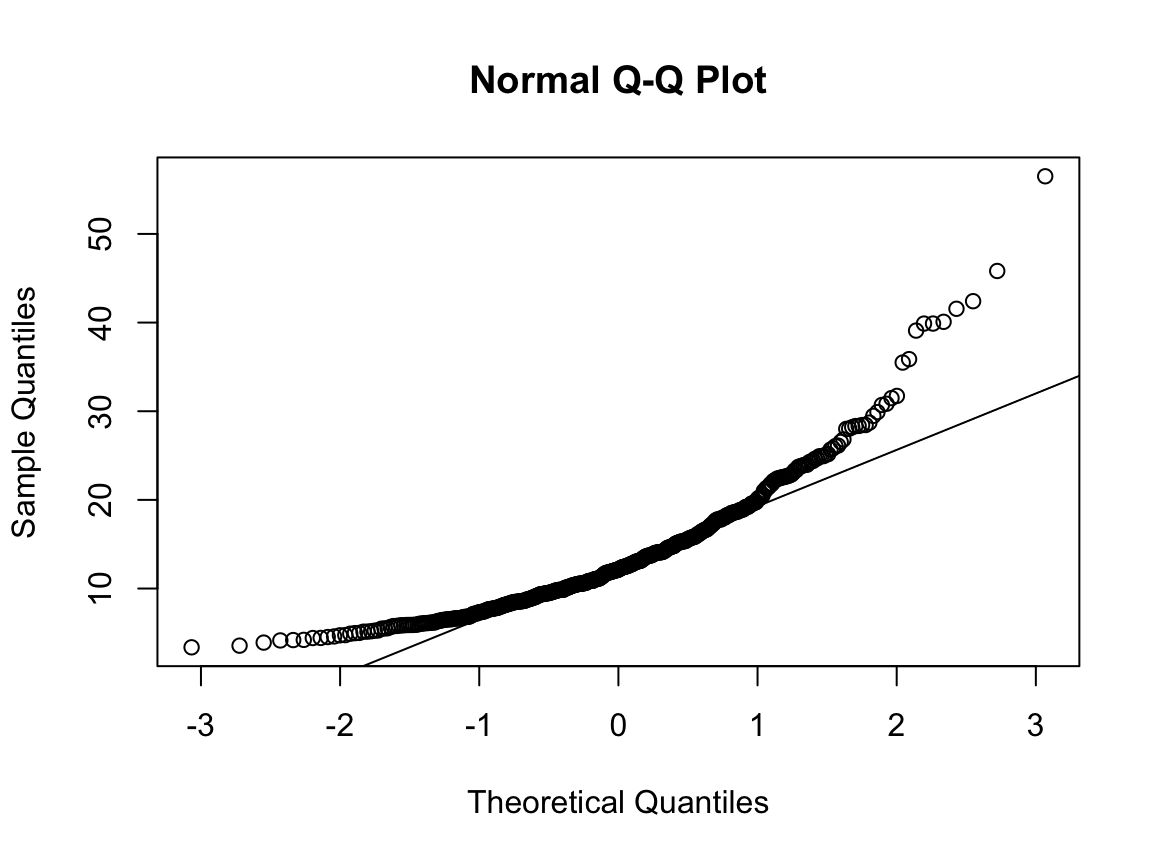
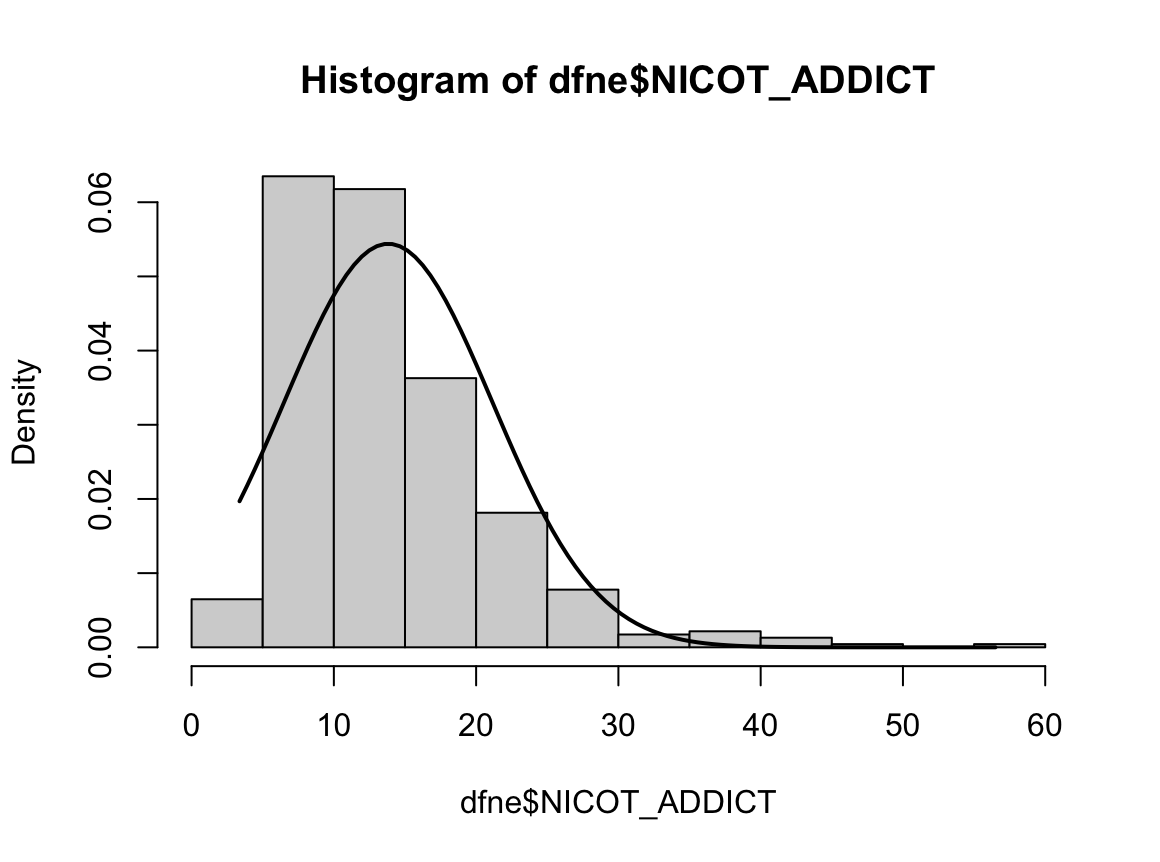
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않고, 히스토그램에서도 정규성을 따르지 않는 것처럼 보인다. 따라서 독립 표본 T검정 (Two-sample T-test)를 시행할 수 없고, 맨 휘트니 U 검정 (Mann-Whitney U test)을 시행해야 한다.
맨 휘트니 U 검정 (Mann-Whitney U test)
1) 분석(A) > 비모수검정(N) > 독립표본(I)
2) 이때 나오는 창의 첫 페이지인 "목적"은 건들지 않는다.
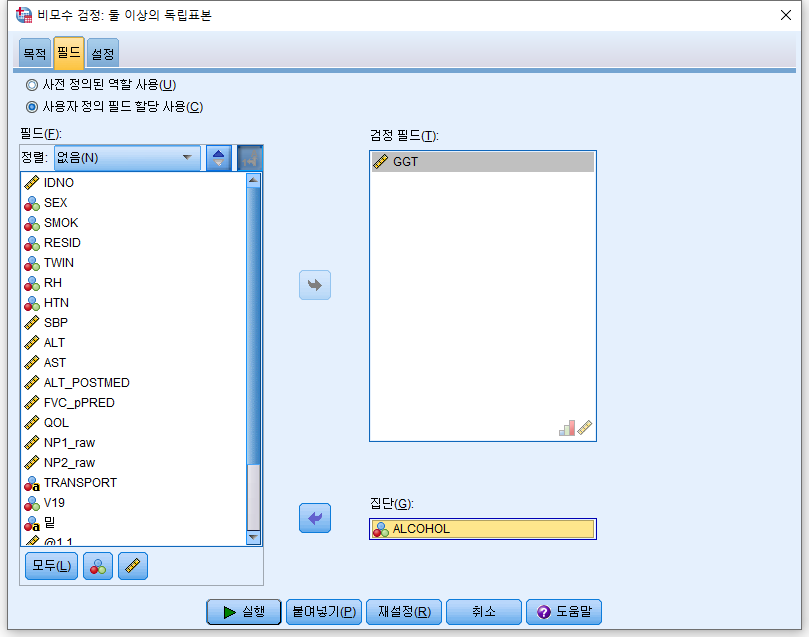
3) "필드"를 누르고 분석하고자 하는 GGT를 "검정 필드(T)"로 넘긴다. 음주 여부에 따라 검정할 것이므로 ALCOHOL을 "집단(G)"로 옮긴다.
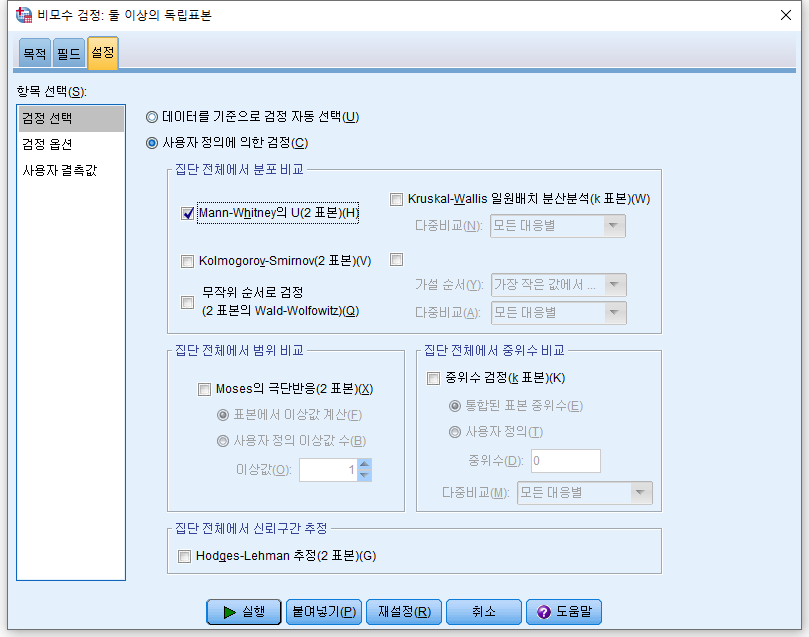
4) "사용자 정의에 의한 검정(C)"를 누르고 "Mann-Whitney의 U(2표본)(H)"을 체크한다.
결과
유의확률이 0.000으로 0.001보다 작다. 따라서 유의한 결과임을 알 수 있다. 따라서 귀무가설을 기각하고 대립 가설을 택해야 한다. 여기에서 귀무가설과 대립 가설은 무엇일까?
귀무가설$H_0=$ 분포는 동일하다.
대립가설$H_1=$ 두 분포는 평균만 다를 뿐, 분포는 똑같이 생겼다.
즉, 대립 가설이 의미하는 것은 두 분포는 평행이동 관계에 있다는 것이다. 그래야 대립가설을 선택하더라도 중앙값이 달라진 것인지 확인할 수 있다.
평행이동 관계
이 말은, 맨 휘트니 U 검정에도 필요한 가정이 있다는 말이다. 두 분포는 동일하게 생겼어야 한다.
조금 어렵게 이야기하면, 두 분포의 first moment는 다르지만, 그보다 고차원의 central moment는 같아야 한다.
만약 맨 휘트니 U 검정이 "중앙값이 같은지 확인하는 검정"이라고만 알고 있다면 중앙값이 완전히 같은 이런 경우에도 "중앙값에 차이가 있다."라고 결론 내릴 것이다. 하지만 이 경우 귀무가설을 기각하고 "두 분포는 다르게 생겼다."라고 결론 내려야 옳은 결론에 다다른다. 그러므로 맨 휘트니 U 검정의 가정인 "모양이 똑같이 생겼다."를 반드시 준수하길 바란다.
[SPSS] 윌콕슨 순위 합 검정, 맨 휘트니 U 검정 (비모수 독립 표본 중앙값 검정: Wilcoxon rank sum test, Mann-Whitney U test) 정복 완료!
어떤 분포의 평균이 특정 값인지 확인하는 방법을 이전에는 일표본 T검정 (One-Sample T test)로 시행했었다. (2022.11.29 - [모평균 검정/SPSS] - [SPSS] 일표본 T검정 (One-sample T-test)) 하지만 여기에는 중요한 가정이 필요한데, 분포가 정규성을 따르는 것이다. 하지만 분포가 정규성을 따르지 않는다면 어떻게 해야 할까? 그럴 때 사용하는 것이 One-Sample Wilcoxon Signed Rank Test (일표본 윌콕슨 부호 순위 검정)이다.
이번 포스팅에서는 One-Sample Wilcoxon Signed Rank Test (일표본 윌콕슨 부호 순위 검정)에 대해서 알아볼 것이다.
2) 분석하고자 하는 변수인 NP1_raw을 "종속변수"에 넣어준다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
결과
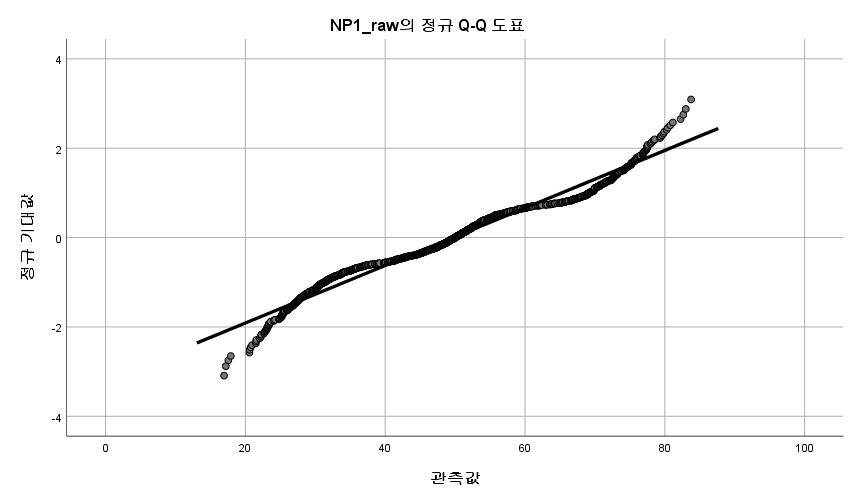
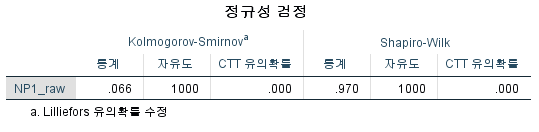
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않고, 히스토그램에서도 정규성을 따르지 않는 것처럼 보인다. 따라서 일표본 T검정 (One-sample T-test)를 시행할 수 없고, 일표본 윌콕슨 부호 순위 검정 (One-Sample Wilcoxon Signed Rank Test)을 시행해야 한다.
일표본 윌콕슨 부호 순위 검정 (One-Sample Wilcoxon Signed Rank Test)
이번 일표본 윌콕슨 부호 순위 검정 (One-Sample Wilcoxon Signed Rank Test)의 귀무가설과 대립 가설은 다음과 같다.
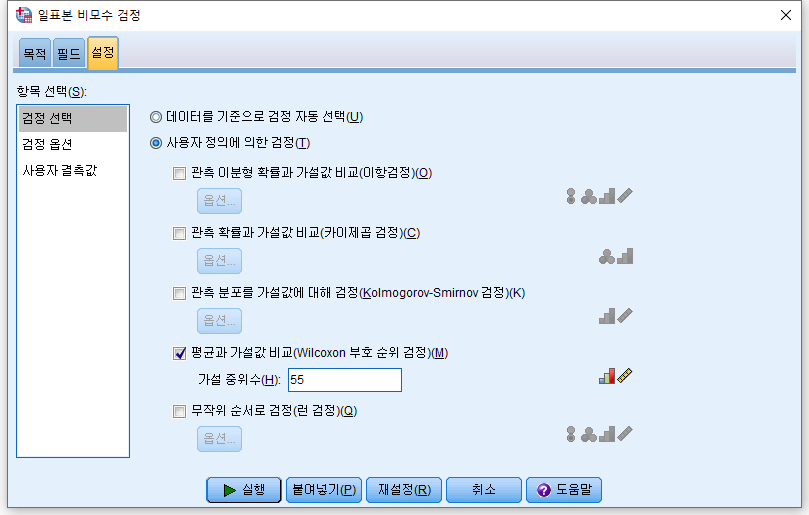
귀무 가설:$H_0=$ 모집단의 NP1_raw 중앙값은 55이다.
대립 가설:$H_1=$ 모집단의 중앙값은 55보다 크거나 작다. (양측 검정)
1) 분석(A) > 비모수검정(N) > 일표본(O)
2) 이때 나오는 창의 첫 페이지인 "목적"은 건들지 않는다.
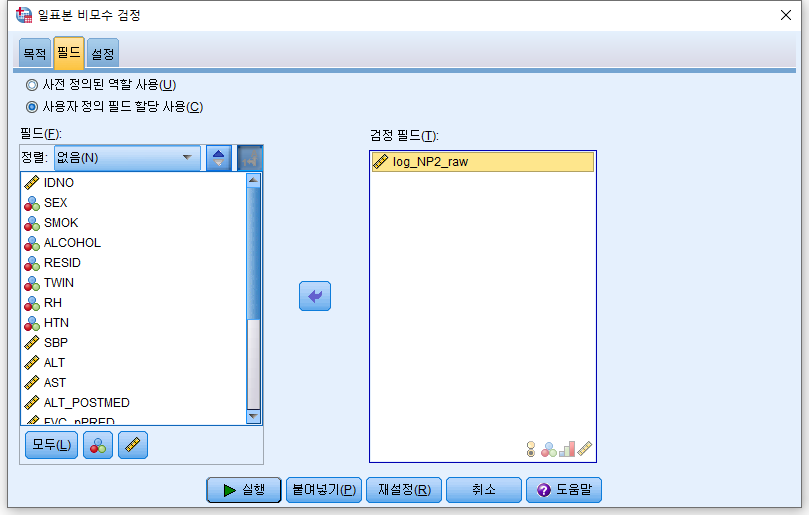
3) "필드"를 누르고 분석하고자 하는 NP1_raw를 오른쪽으로 넘긴다.
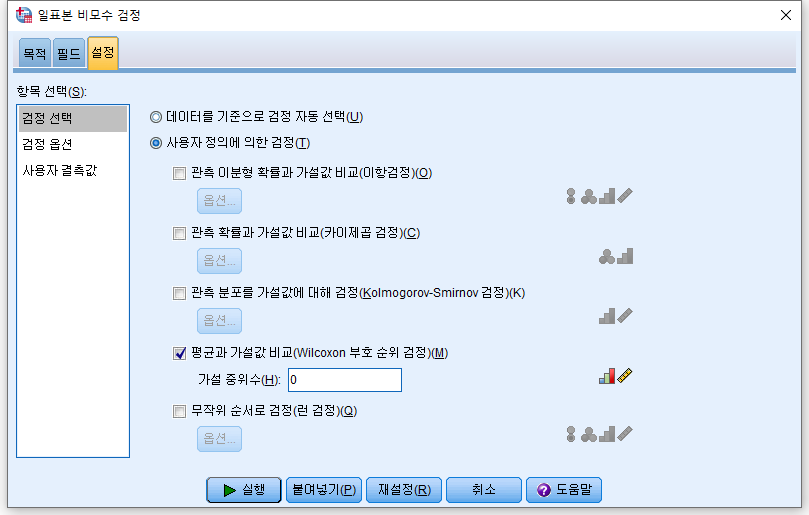
4) "사용자 정의에 의한 검정(T)"를 누르고 "평균과 가설값 비교(Wilcoxon 부호 순위 검정)"을 체크하고, 가설 중위수에는 검정하고자 하는 값인 55를 적는다. 그리고 "실행"을 누른다.
결과
p-value=0.000으로 이는 0.001보다 작다는 뜻이며, 0.05보다 작으므로 귀무가설을 기각하고 대립 가설을 받아들인다. 대립 가설은 중위수가 55가 아니라고 설정했었으므로 적어도 중위수가 55는 아니라고 이야기할 수 있다. 그렇다면 중위수가 얼마였길래 그럴까?
중위수 확인
1) 분석(A) > 기술통계량(E) > 데이터 탐색 (E)
2) 분석하고자 하는 변수인 NP1_raw을 "종속변수"에 넣어준다. 그 뒤 "확인"을 누른다.
결과
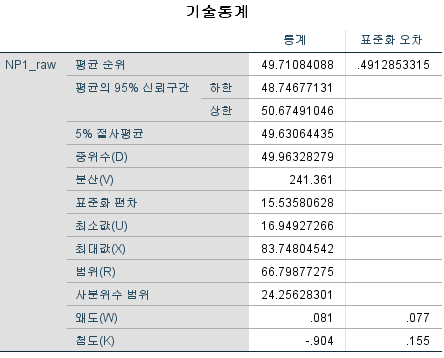
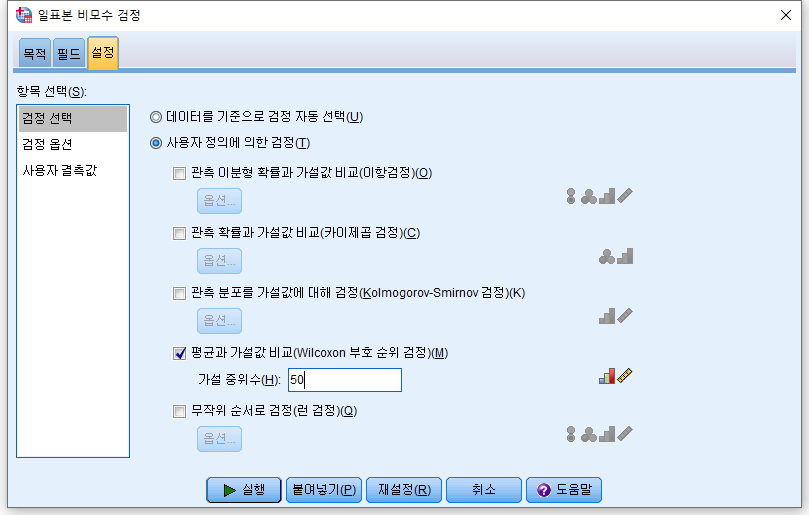
중위수는 49.96328279로 거의 50에 가깝다. 그렇다면 Wilcoxon 부호 순위 검정을 50에 대해 시행하면 어떻게 될까? 가설 중위수에 50을 넣고 실행을 눌러보자
결과
p-value>0.05이므로 귀무가설을 채택하여 50과 다르다고 할 수 없다는 결론을 얻는다.
중요한 가정: 대칭성
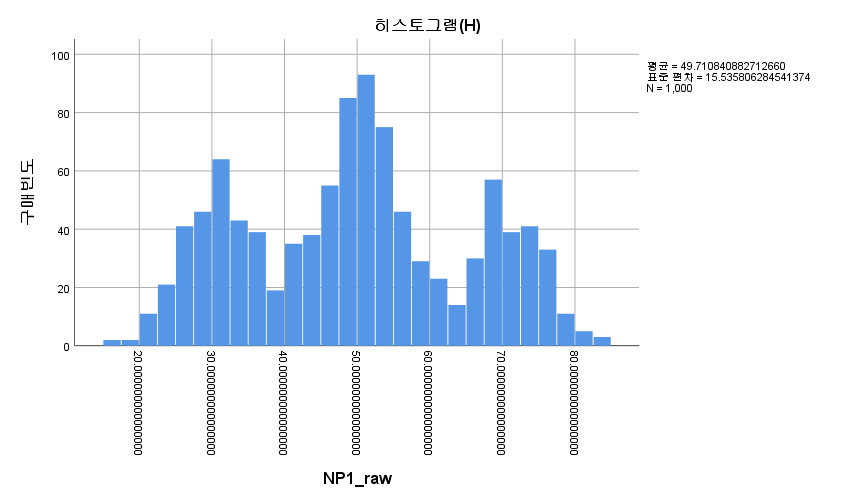
위 논의에서 빠진 정말 중요한 가정이 하나 있다. 신경심리검사 1 원점수 (NP1_raw)의 분포가 어떤 점수를 기점으로 좌우대칭이라는 것이다. 윌콕슨 부호 순위 검정은 좌우대칭일 때 그 검정력이 극대화되며, 좌우대칭이 아니면 정확도가 떨어진다. 신경심리검사 1 원점수 (NP1_raw)의 분포를 히스토그램을 통해 알아보고자 하며 이는 위에 구해놓았다.
봉우리가 세 개인 Trimodal shape을 하고 있고, 중앙값인 50을 기준으로 대칭인 것처럼 보인다. 따라서 위 분석에는 문제가 없는 듯하다.
가정이 성립하지 않는다면?
우리가 궁금하고, 문제가 되는 상황은 가정이 성립하지 않는 상황이다. 실제로 이럴 때가 많기 때문이다. 신경심리검사 2 원점수인 NP2_raw데이터의 분포를 확인해보자.
1) 분석(A) > 기술통계량(E) > 데이터 탐색 (E)
2) 분석하고자 하는 변수인 NP2_raw을 "종속변수"에 넣어준다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
결과
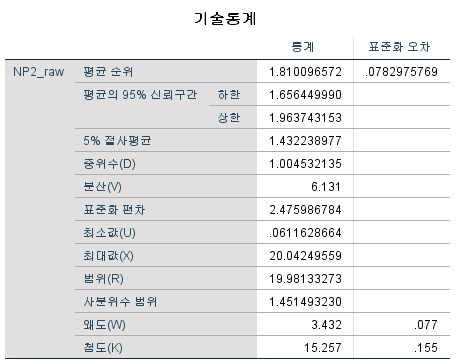
분포는 오른쪽으로 꼬리가 긴 right skewed 모양을 하고 있으며, 중위수는 1.004532153이다. 이 값에 대해 일표본 윌콕슨 부호 순위 검정을 해보자. 보통 우리는 "정규성을 만족하지 않으므로 윌콕슨 부호 순위 검정으로 모집단의 중위수를 검정하자."라고 생각한다. 만약 이런 논리에 따른다면 1.004532135에 대해 일표본 윌콕슨 부호 순위 검정을 시행한다면 당연히 유의하지 않은 결과가 나와야 한다.
1) 분석(A) > 비모수검정(N) > 일표본(O)
2) 이때 나오는 창의 첫 페이지인 "목적"은 건들지 않는다.
3) "필드"를 누르고 분석하고자 하는 NP2_raw를 오른쪽으로 넘긴다.
4) "사용자 정의에 의한 검정(T)"를 누르고 "평균과 가설값 비교(Wilcoxon 부호 순위 검정)"을 체크하고, 가설 중위수에는 검정하고자 하는 값인 1.004532135를 적는다. 그리고 "실행"을 누른다.
결과
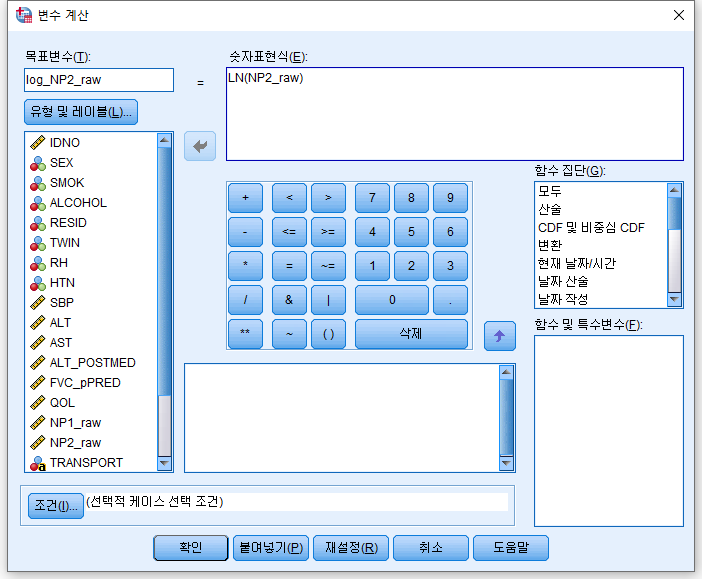
p-value가 0.001보다도 작다는 결론에 도달한다. 참 중앙값으로 "NP2_raw의 중앙값이 참 중앙값과 같니?"라고 물어보았는데 "아니요"라고 대답하는 참사가 벌어진다. 이렇게 '잘못된' 결론을 내는 이유는 사실 우리가 윌콕슨 부호 순위 검정에 대해 '잘못된' 지식이자 선입견을 갖고 있기 때문이다. 윌콕슨 부호 순위 검정을 좌우 대칭인 데이터에만 사용할 수 있고, 그럴 때에만 중위수에 대한 검정을 의미한다. 이럴 때 선택할 수 있는 옵션이 많지 않긴 한데, 그중 하나는 변환 (transformation)이다. 이런 right skewed data는 로그 변환 (log-transformation)을 하면 대칭성이 갖추어지는 경우가 많다. 로그 변환을 하고 히스토그램을 그려 분포를 확인해보자. (로그 변환에 관한 글은 다음 링크에서 확인할 수 있다. 2022.11.30 - [통계 프로그램 사용 방법/SPSS] - [SPSS] 변수 계산 (산술 연산))
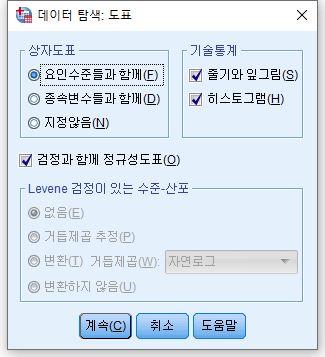
2) 분석하고자 하는 변수인 NP2_raw을 "종속변수"에 넣어준다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
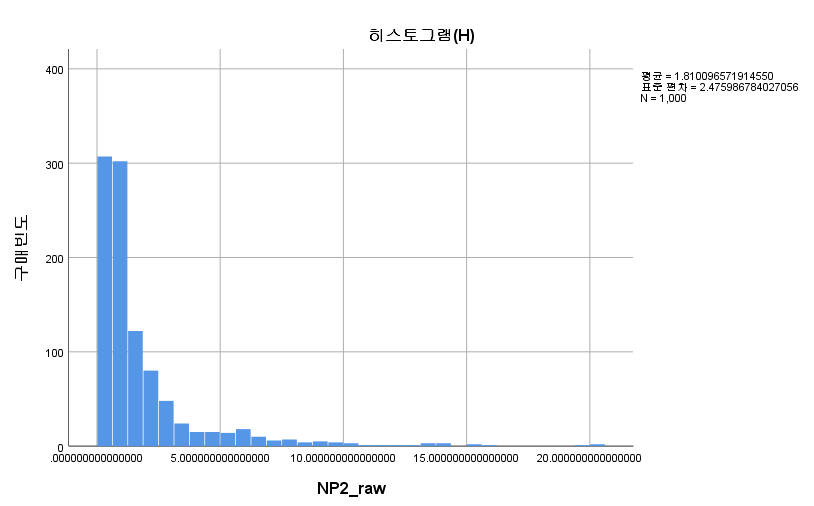
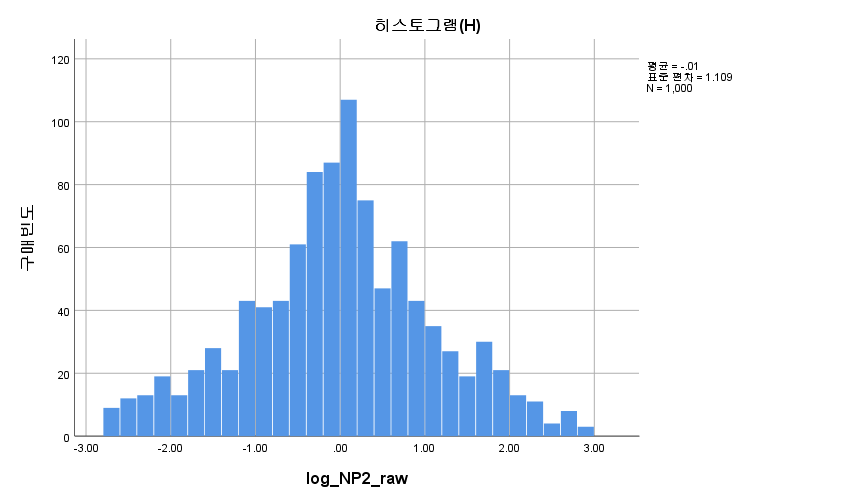
결과
대칭성을 띠는 듯 하지만 정규성을 따르지는 않는다. 따라서 일표본 윌콕슨 부호 순위 검정을 시행하도록 한다.
1) 분석(A) > 비모수검정(N) > 일표본(O)
2) 이때 나오는 창의 첫 페이지인 "목적"은 건들지 않는다.
3) "필드"를 누르고 분석하고자 하는 NP2_raw를 오른쪽으로 넘긴다.
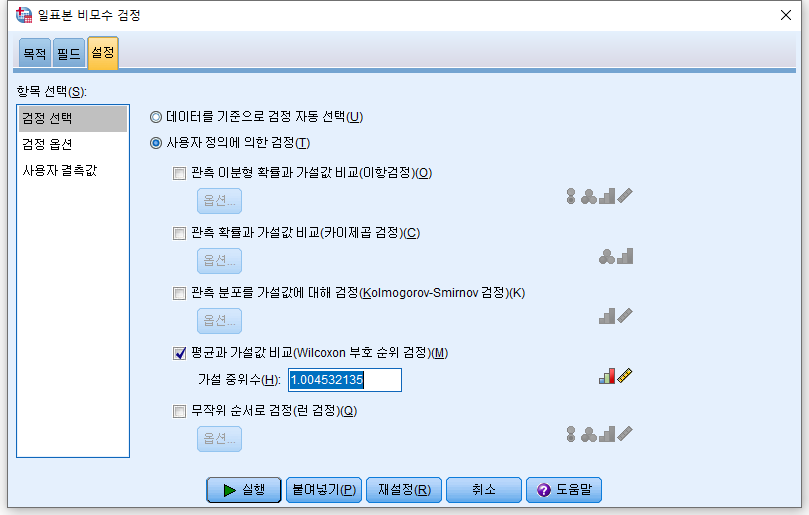
4) "사용자 정의에 의한 검정(T)"를 누르고 "평균과 가설값 비교(Wilcoxon 부호 순위 검정)"을 체크하고, 가설 중위수에는 검정하고자 하는 값을 넣는데, 원래 중위수가 1.004532135이었으므로 로그 변환을 하면 0과 가까우니 0을 적는다. 그리고 "실행"을 누른다.
결과
이제야 유의하지 않다는 결론을 맞게 잘 내준다.
그 외 다룰 내용 1: 정규성을 안 따르면 꼭 Wilcoxon test를 시행해야 하나?
T-test의 전제조건은 표본 평균이 정규분포를 따르는 것이다. 그런데 중심 극한 정리에 따라 표본의 수 (우리 데이터에서는 n=1,000)가 커질수록 표본 평균의 분포는 정규성을 띠게 된다. 따라서 n수가 적당히 크기만 하면 표본이 정규분포를 따르는지와 관계없이 표본 평균은 정규성을 따른다고 할 수 있다. 이런 이유로 정규성과 관계없이 n수가 크기만 하면 t-test의 이용이 정당화되기도 한다. 합리적인 말이다.
그런데 왜 정규분포를 따르는지 왜 다들 확인할까? 만약 모분포가 정규분포였다면 표본도 정규분포를 따를 확률이 높아진다. 물론 꼭 그런 건 아니지만 말이다. 따라서 표본이 정규분포를 따른다면, 모분포를 정규분포를 따른다고 할 수 있고, 그렇다면 n수가 작아도 표본 평균의 분포도 정규성을 따르니 t-test를 사용해도 되는 안전한 환경이 구축된다. 이런 이유로 정규성을 확인하게 된다.
그 외 다룰 내용 2: Wilcoxon signed rank test는 짝지어진 자료의 검정방법 아닌가?
그런데, 여기에는 각각의 분포가 정규성을 따른다는 중요한 가정이 필요하다. 하지만 정규성을 따르지 않는다면 어떻게 해야 할까? 그럴 때 사용하는 것이 크루스칼-왈리스 검정(Kruskal-Wallis Test)이다. 이번 포스팅에서는 크루스칼 왈리스 검정과 그 사후 분석 (post hoc analysis)까지 알아보고자 한다.
Shapiro-Wilk normality test
data: dfne$NICOT_ADDICT
W = 0.88076, p-value < 2.2e-16
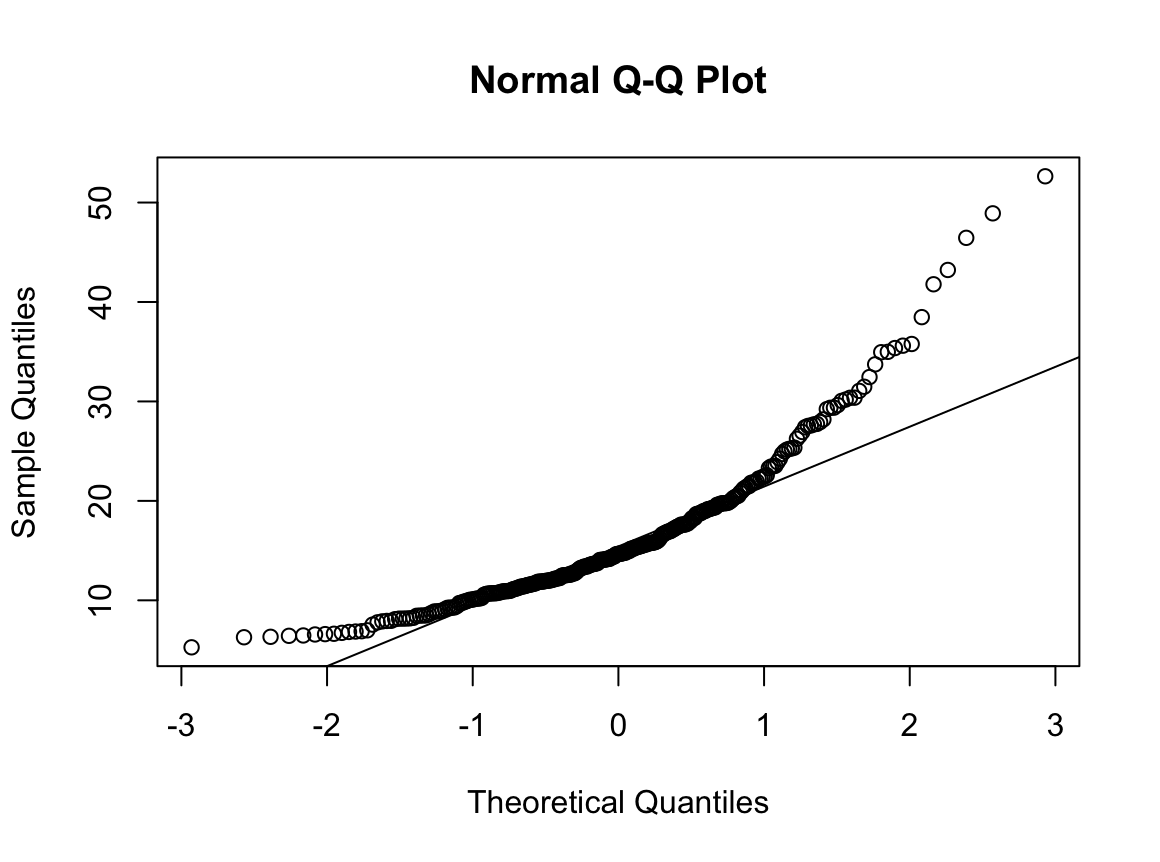
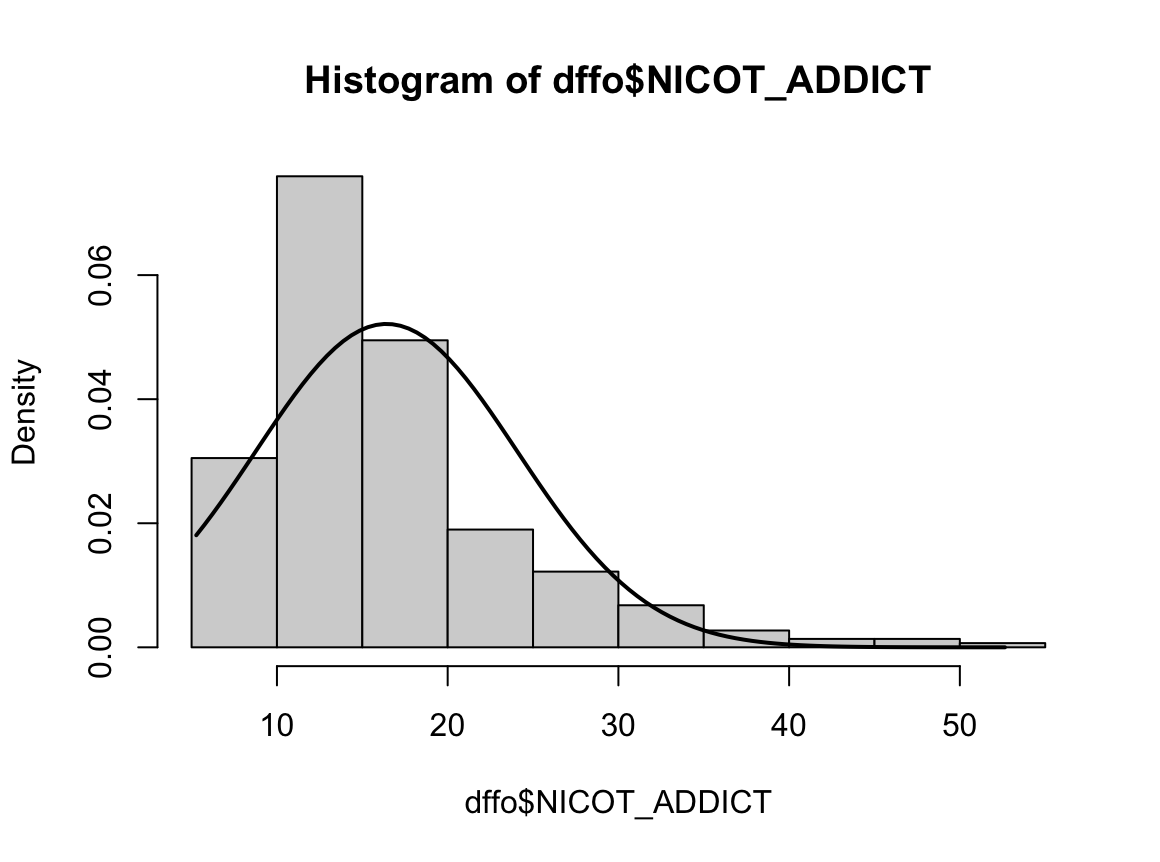
2) 과거 흡연자
Shapiro-Wilk normality test
data: dffo$NICOT_ADDICT
W = 0.87644, p-value = 1.122e-14
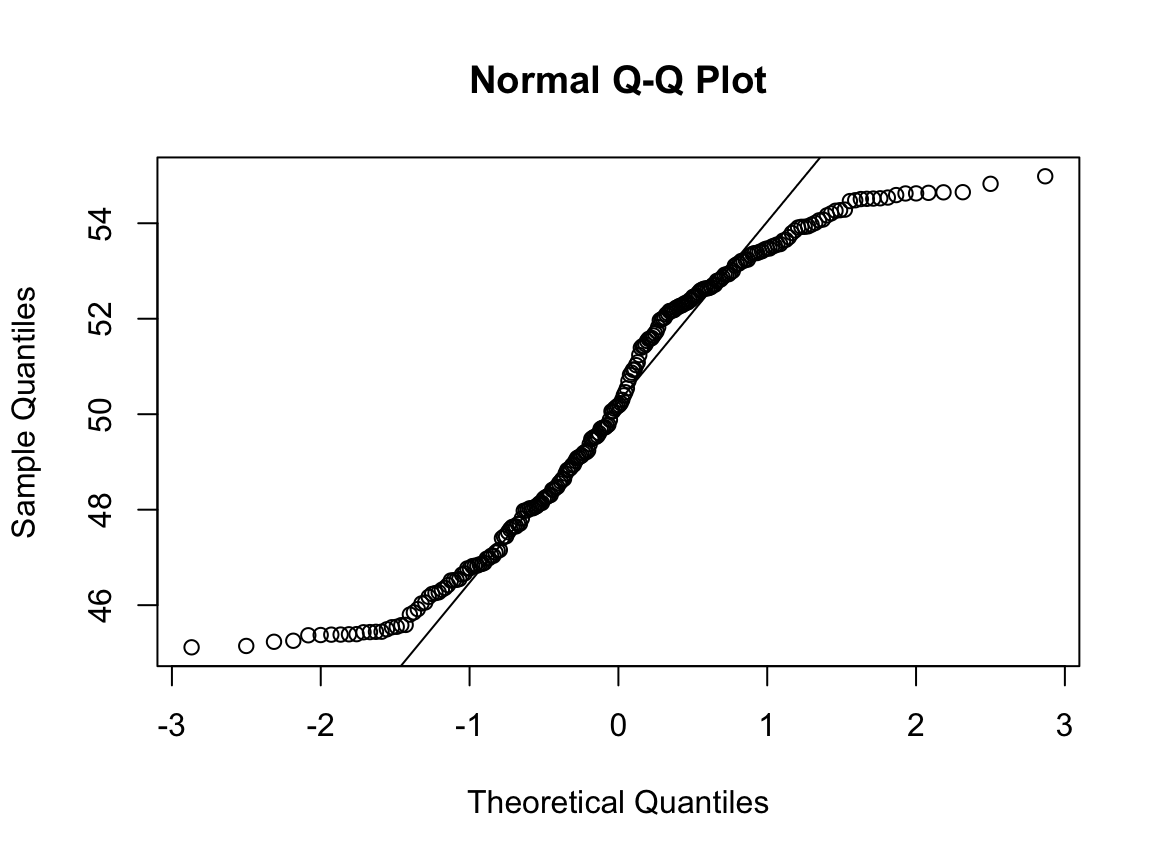
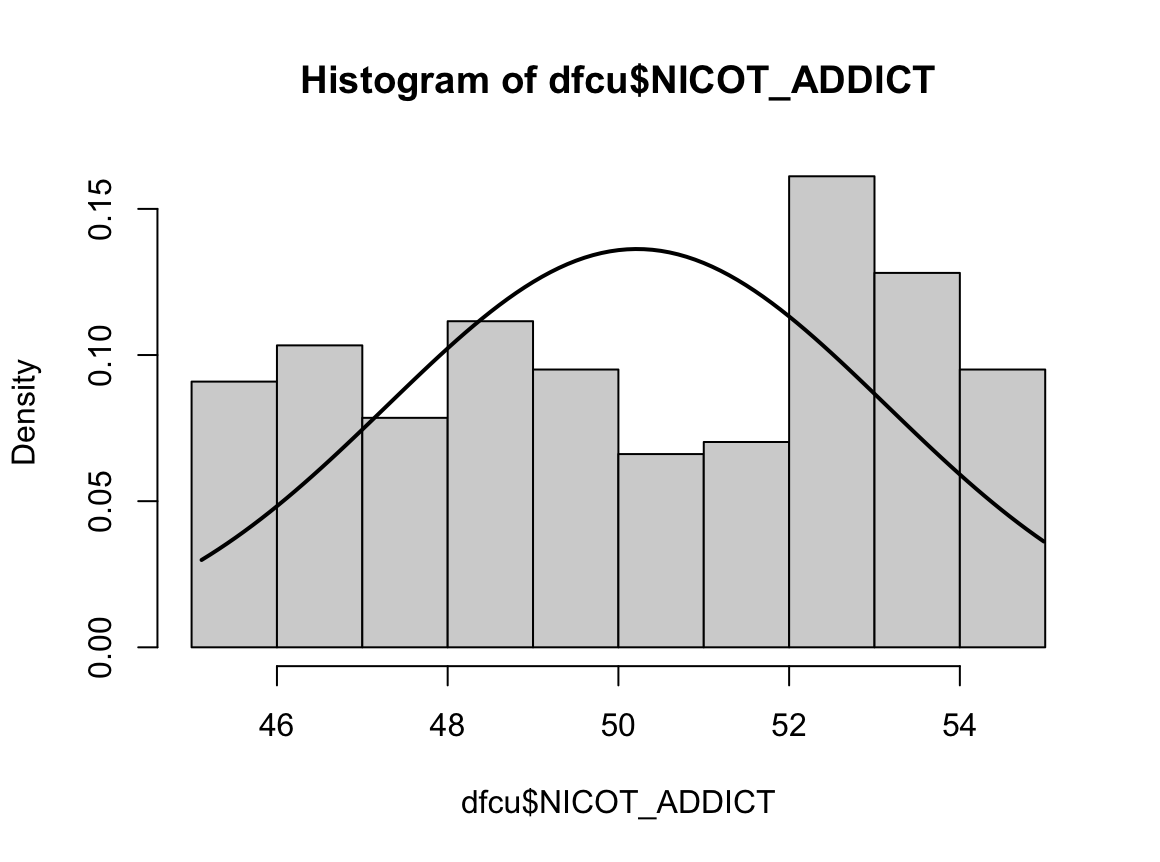
3) 현재 흡연자
Shapiro-Wilk normality test
data: dfcu$NICOT_ADDICT
W = 0.93791, p-value = 1.364e-08
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않고, 히스토그램에서도 정규성을 따르지 않는 것처럼 보인다. 따라서 일원 배치 분산 분석 (ANOVA)을 시행할 수 없고, 크루스칼 왈리스 분석 (Kruskal-Wallis Test)을 시행해야 한다.
지금까지 많은 분석을 할 때 분산이 같은지 여부 (등분산성)을 중요하게 여겼었다. 하지만 크루스칼 왈리스 분석은 분산이 달라도 어느 정도 괜찮다. 물론 분산에 아주 큰 차이가 나면 위험해지지만, 어느 정도는 robust 하므로 웬만하면 그냥 써도 괜찮다.
크루스칼 왈리스 (Kruskal Wallis) 검정 코드
kruskal.test(NICOT_ADDICT~SMOK, data=df)
kruskal.test(NICOT_ADDICT~SMOK, data=df) : 데이터 df의 SMOK에 따라 NICOT_ADDICT의 중앙값에 차이가 있는지 Kruskal-Wallis 검정을 시행하라.
결과
Kruskal-Wallis rank sum test
data: NICOT_ADDICT by SMOK
Kruskal-Wallis chi-squared = 560.98, df = 2, p-value < 2.2e-16
p-value가 0.05보다 작으므로 귀무가설을 기각하고 대립 가설을 채택한다. 그렇다면 여기에서 귀무가설 및 대립 가설은 무엇이었는가?
귀무가설: $H_0=$세 집단의 모집단 수준에서 중앙값은 "모두" 동일하다.
대립가설: $H_1=$ 세 집단의 모집단 수준에서 중앙값이 모두 동일한 것은 아니다.
우리는 대립 가설을 채택해야 하므로 "세 집단의 모집단 수준에서 중앙값이 모두 동일한 것은 아니다."라고 결론 내릴 것이다.
사후 분석
그런데, 세 집단의 중앙값이 모두 동일하지 않다는 말은 세 집단 중 두 개씩 골라 비교했을 때, 적어도 한 쌍에서는 차이가 난다는 것이다. 따라서 세 집단 중 두 개씩 골라 비교를 해보아야 하며, 이를 사후 분석 (post hoc analysis)이라고 한다. 세 집단에서 두 개씩 고르므로 가능한 경우의 수 $_3C_2=3$이다.
(1) 비흡연자 vs 과거 흡연자
(2) 비흡연자 vs 현재 흡연자
(3) 과거 흡연자 vs 현재 흡연자
비모수 검정인 Kruskal Wallis 검정의 사후 분석으로 쓰이는 방법은 다음 네 가지가 있다.
1) Pairwise Wilcoxon Test
2) Conover Test
3) Dunn Test
4) Nemenyi Test
코드
#1) Pairwise Wilcoxon Test
pairwise.wilcox.test(df$NICOT_ADDICT, df$SMOK, p.adjust.method="bonferroni", correct=FALSE)
#2) Conover Test
install.packages("DescTools")
library("DescTools")
ConoverTest(NICOT_ADDICT~SMOK, data=df)
#3) Dunn Test
DunnTest(NICOT_ADDICT~SMOK, data=df)
#4) Nemenyi Test
NemenyiTest(NICOT_ADDICT~SMOK, data=df)
ConoverTest(NICOT_ADDICT~SMOK, data=df) : df데이터의 SMOK에 따라 NICOT_ADDICT의 중앙값에 차이가 있는지 Conover test를 시행하라. Conover test, Dunn test, Nemenyi test모두 구조는 같다. 이 세 개의 함수는 "DescTools"라는 패키지에 포함되어 있으므로 설치를 먼저 해야 한다. 패키지 설치에 관한 내용은 다음 링크를 확인하길 바란다. 2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 패키지 설치하기 - install.packages(), library()
각각의 pairwise로 robust rank order test를 시행하고, 각각의 p-value를 모아 보정을 하는 것이다.
p<-c(p1, p2, p3) : p1, p2, p3을 묶어 하나의 p에 저장하라 p.adjust(p, "bonferroni") : p에 있는 값들을 보정하되, bonferroni adjustment를 사용하라.
Bonferroni 외에도, holm, hochberg, hommel, BH, BY, fdr을 넣어 각각의 방법으로 보정을 시도할 수 있다.
어떤 사후 분석을 쓸 것인가
이 논의에 대해 정답이 따로 있는 것은 아니다. 적절한 방법을 사용하여 논문에 제시하면 되고, 어떤 것이 정답이라고 콕 집어 이야기할 수는 없다. 다만, 사후 분석 방법이 여러 가지가 있다는 것은 '사후 분석 방법에 따라 산출되는 결과가 달라질 수 있다.'는 것을 의미하고, 심지어는 '어떤 사후 분석 방법을 채택하냐에 따라 유의성 여부가 달라질 수도 있다.'는 것을 의미한다. 심지어, Kruskal-Wallis test에서는 유의한 결과가 나왔는데, 사후 분석을 해보니 유의한 차이를 보이는 경우가 없을 수도 있다. 따라서 어떤 사후 분석 방법 결과에 따른 결과인지 유의하여 해석할 필요가 있다.
왜 굳이 Kruskal Wallis test를 쓰는 것인가?
이 시점에서 이런 의문이 들 수 있다.
"각각의 그룹별로 평균을 비교하면 되지, 굳이 왜 Kruskal Wallis test라는 방법까지 사용하는 것인가?"
아주 논리적인 의문점이다. 하지만, 반드시 Kruskal-Wallis test를 사용해야 한다. 그 이유는 다음과 같다. 본 사례는 흡연 상태에 따른 조합 가능한 경우의 수가 3인데, 각각 유의성의 기준을 $\alpha=0.05$로 잡아보자. 이때 세 번의 비교에서 모두 귀무가설이 학문적인 진실인데(평균에 차이가 없다.), 세 번 모두 귀무가설을 선택할 확률은 $\left( 1-0.05 \right)^3 \approx 0.86$이다. (이해가 어려우면 p-value에 대한 설명 글을 읽고 오길 바란다. 2022.09.05 - [통계 이론] - [이론] p-value에 관한 고찰)
그런데, Kruskal-Wallis test의 귀무가설은 "모든 집단의 중앙값이 같다."이다. 따라서 모든 집단의 중앙값이 같은 것이 학문적 진실일 때, 적어도 한 번이라도 대립 가설을 선택하게 될 확률은 $1-0.86=0.14$가 된다. 즉, 유의성의 기준이 올라가게 되어, 덜 보수적인 결정을 내리게 되고, 다시 말하면 대립 가설을 잘 선택하는 쪽으로 편향되게 된다. 학문적으로는 '다중 검정 (multiple testing)을 시행하면 1종 오류가 발생할 확률이 증가하게 된다.'라고 표현한다.
따라서, 각각을 비교해보는 것이 아니라 한꺼번에 비교하는 Kruskal-Wallis test를 시행해야 함이 마땅하다.
여기에서 한 번 더 의문이 들 수 있다.
"사후 분석을 할 때에는 1종 오류가 발생하지 않는가?"
그렇다. 1종 오류가 발생할 확률이 있으므로, p-value의 기준을 더 엄격하게 (0.05보다 더 작게) 잡아야 한다. P-value를 보정하는 방법은 일반적으로는 Bonferroni, holm, hochberg, hommel, BH, BY, FDR 등이 있고, Kruskal-Wallis test의 사후 분석 방법으로는 특별히 Pairwise Wilcoxon Test, Conover Test, Dunn Test, Nemenyi Test을 사용하고 있다.
Shapiro-Wilk normality test
data: df_whtn$NP5_raw
W = 0.95661, p-value = 6.406e-11
2) 정상인
Shapiro-Wilk normality test
data: df_wohtn$NP5_raw
W = 0.9426, p-value = 4.956e-13
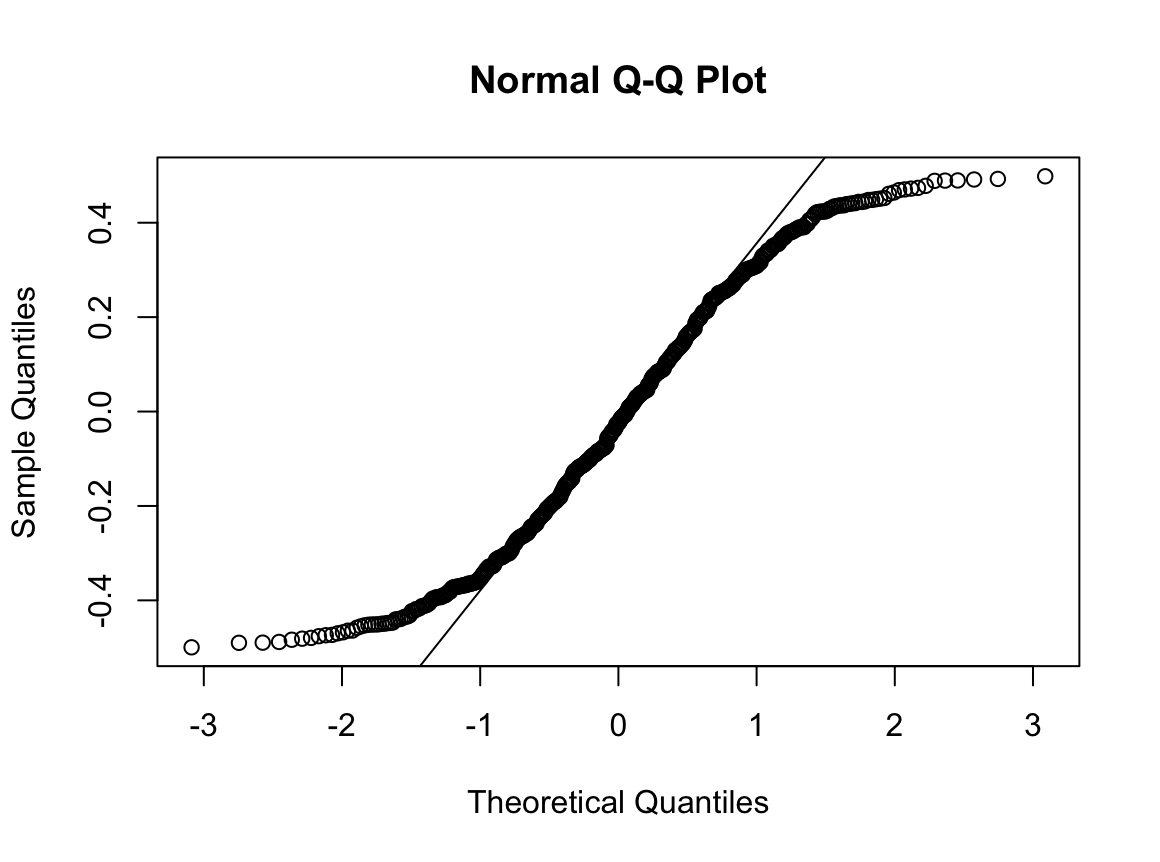
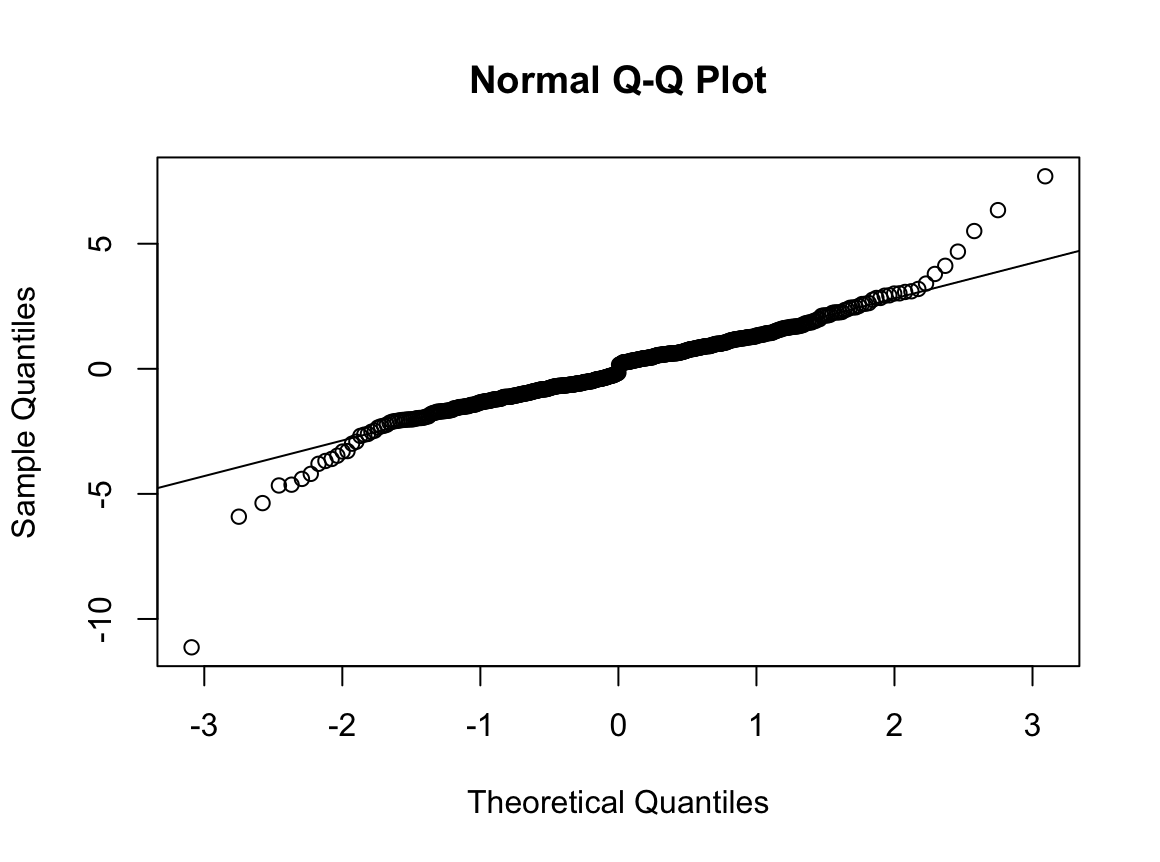
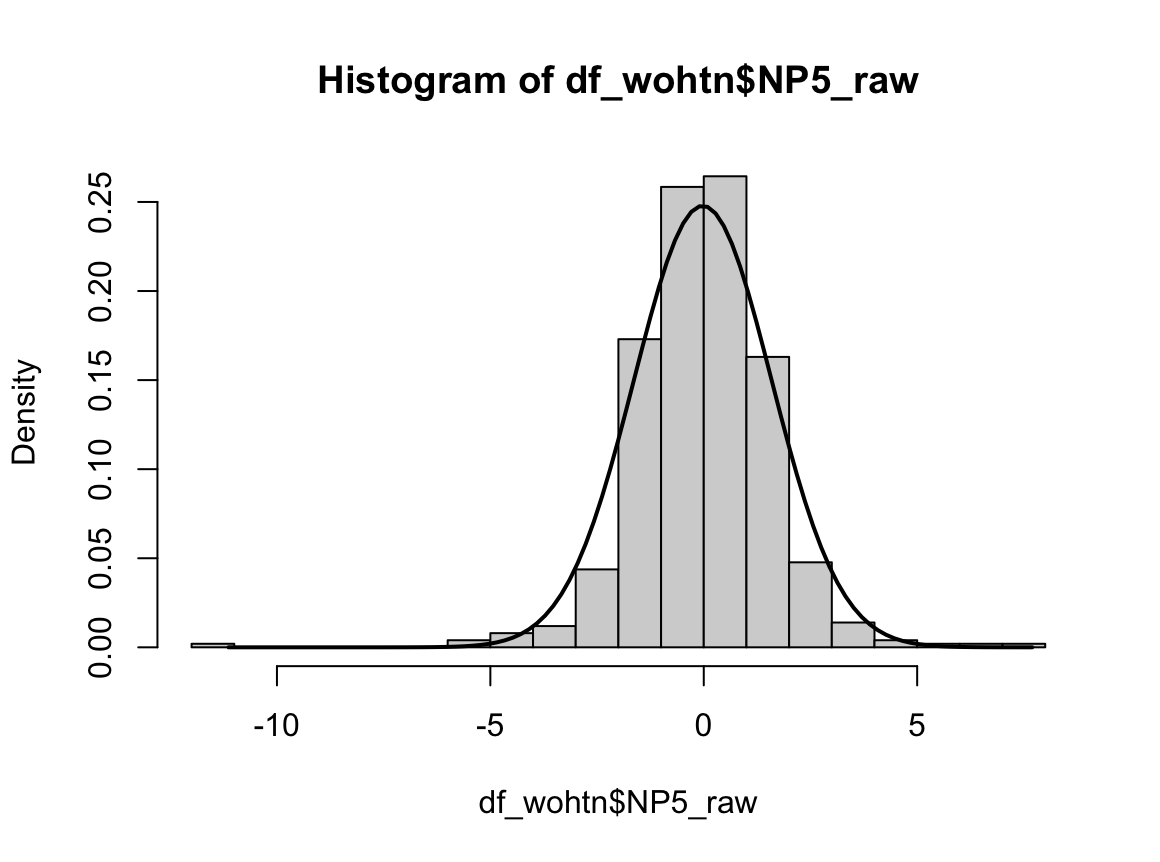
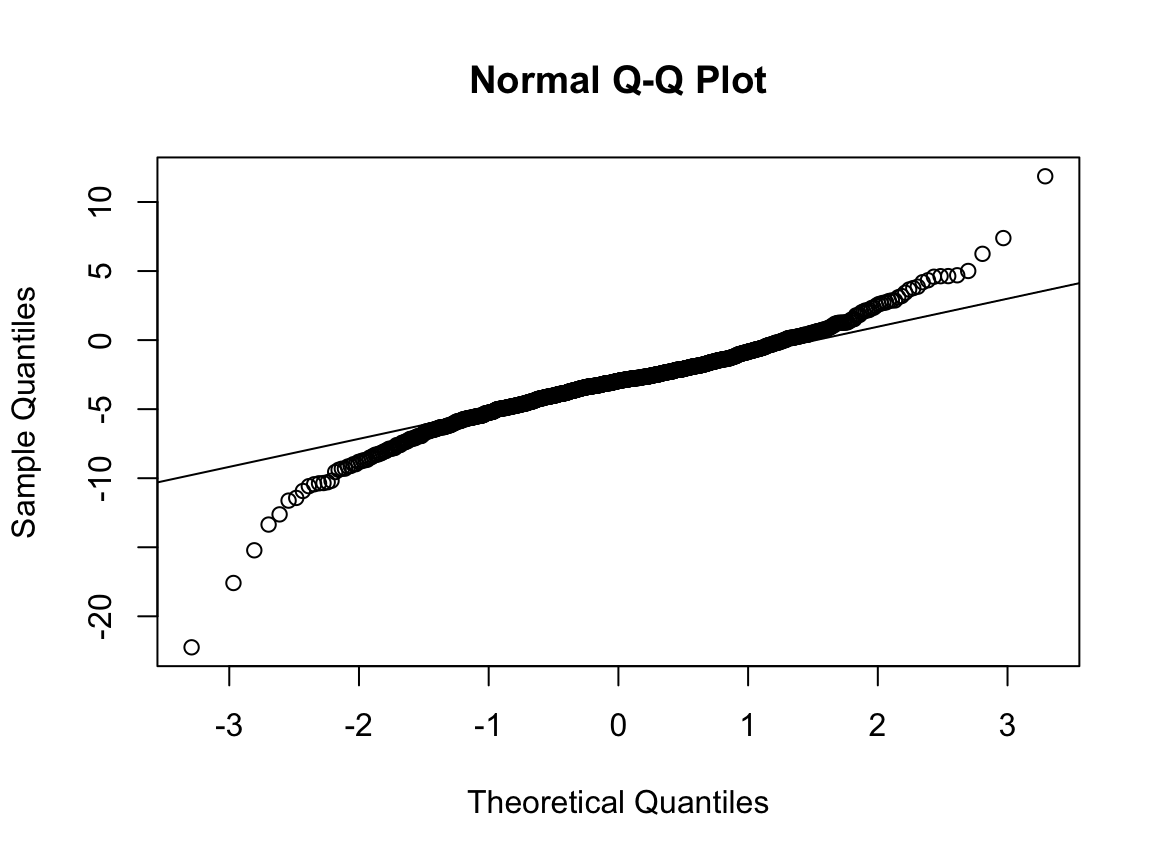
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않고, 히스토그램에서도 정규성을 따르지 않는 것처럼 보인다. 따라서 독립 표본 T검정 (Two-sample T-test)를 시행할 수 없고, 두 분포는 비슷하게 생기지 않았으므로 맨 휘트니 U 검정 (Mann-Whitney U test)도 시행할 수 없다. 그런데 다행히도 각각의 분포는 중앙을 기점으로 대칭성을 이루고 있는 듯하다. 따라서 Robust rank order test를 시행할 수 있겠다.
Robust Rank-Order Distributional Test
data: NP5_raw by HTN
z = -0.090036, p-value = 0.9283
alternative hypothesis: true location shift is not equal to 0
Robust Rank-Order Distributional Test
data: NP5_raw by HTN
z = -0.090036, p-value = 0.9283
alternative hypothesis: true location shift is not equal to 0
p-value를 보면 0.9283으로 0.05보다 크므로 귀무가설을 택한다. 즉, 중앙값에 차이가 없다고 결론 내린다.
로버스트 순위 순서 검정은 대칭성에 대한 전제만 요구할 뿐, 분포의 모양에 대해서는 어떠한 가정도 하지 않는다. 따라서 이런 경우에 아주 유용하다. 그러면 대칭성을 만족하지 못해 로버스트 순위 순서 검정도 하지 못할 때에는 어떻게 해야 할까? 적절한 변환을 통해 모양을 비슷하게 만들어주면 된다. 흔히 알려져 있는 대수적 변환 외에도 변환 함수를 커스터마이징하면 웬만한 분포는 대칭으로 만들 수 있다.
코드 정리
##작업 디렉토리 지정
setwd("C:/Users/user/Documents/Tistory_blog")
##데이터 불러오기
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
##데이터 나누기
df_whtn<-df[df$HTN==1,]
df_wohtn<-df[df$HTN==0,]
##정규성 검정
#고혈압 환자
# 1) Q-Q plot 그리기
qqnorm(df_whtn$NP5_raw)
qqline(df_whtn$NP5_raw)
# 2) 히스토그램 그리기
hist(df_whtn$NP5_raw, prob=TRUE, breaks=20) #자세하게 보기 위해 breaks=20을 추가함
NP5_rawrange<-seq(min(df_whtn$NP5_raw),max(df_whtn$NP5_raw),length=max(max(df_whtn$NP5_raw)-min(df_whtn$NP5_raw),100))
ND<-dnorm(NP5_rawrange,mean=mean(df_whtn$NP5_raw),sd=sd(df_whtn$NP5_raw))
lines(NP5_rawrange, ND, lwd=2)
# 3) Shapiro-Wilk test 시행하기
shapiro.test(df_whtn$NP5_raw)
# 1) Q-Q plot 그리기
qqnorm(df_wohtn$NP5_raw)
qqline(df_wohtn$NP5_raw)
# 2) 히스토그램 그리기
hist(df_wohtn$NP5_raw, prob=TRUE, breaks=20) #자세하게 보기 위해 breaks=20을 추가함
NP5_rawrange<-seq(min(df_wohtn$NP5_raw),max(df_wohtn$NP5_raw),length=max(max(df_wohtn$NP5_raw)-min(df_wohtn$NP5_raw),100))
ND<-dnorm(NP5_rawrange,mean=mean(df_wohtn$NP5_raw),sd=sd(df_wohtn$NP5_raw))
lines(NP5_rawrange, ND, lwd=2)
# 3) Shapiro-Wilk test 시행하기
shapiro.test(df_wohtn$NP5_raw)
#필요 패키지 설치
install.packages("trend")
library("trend")
#로버스트 순위 순서 검정
rrod.test(df_whtn$NP5_raw, df_wohtn$NP5_raw)
rrod.test(NP5_raw~HTN, data=df)
[R] 로버스트 순위 순서 검정 (비모수 독립 표본 중앙값 검정: Robust rank order test, Flinger-Pollicello test) 정복 완료!
Shapiro-Wilk normality test
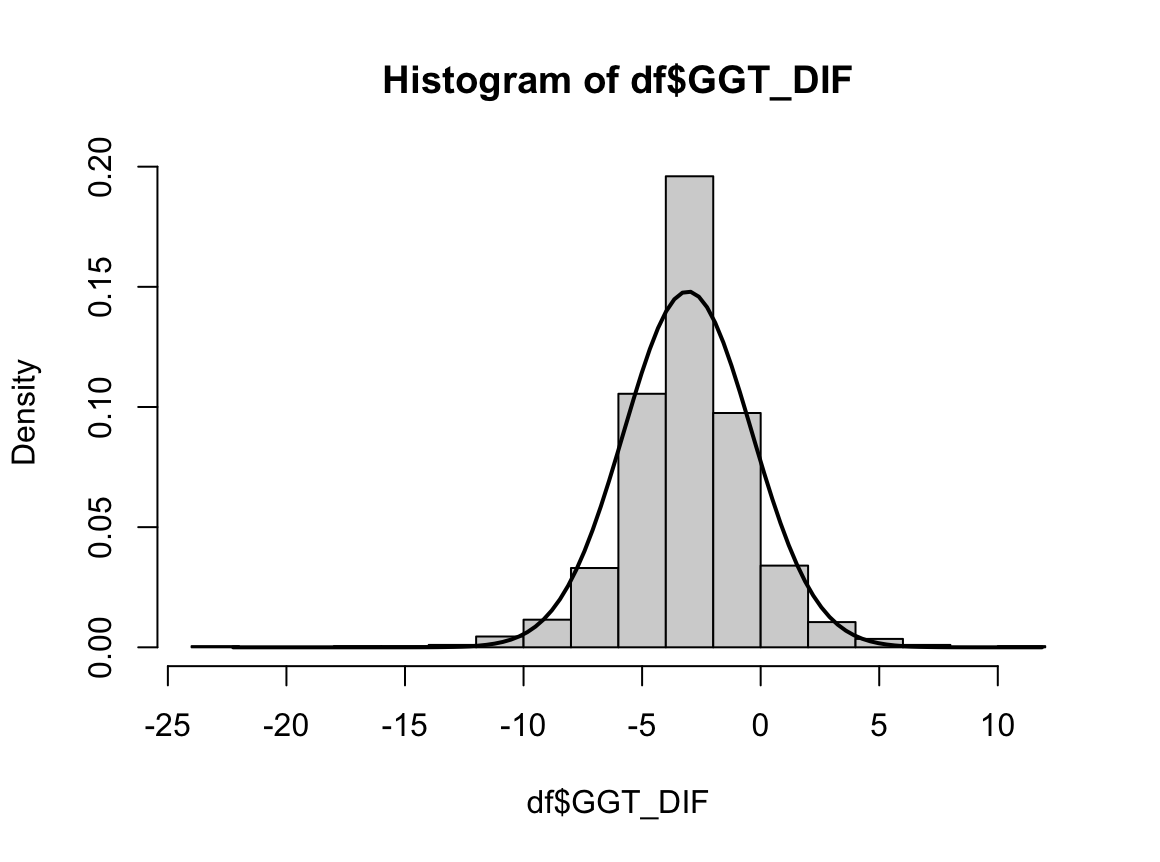
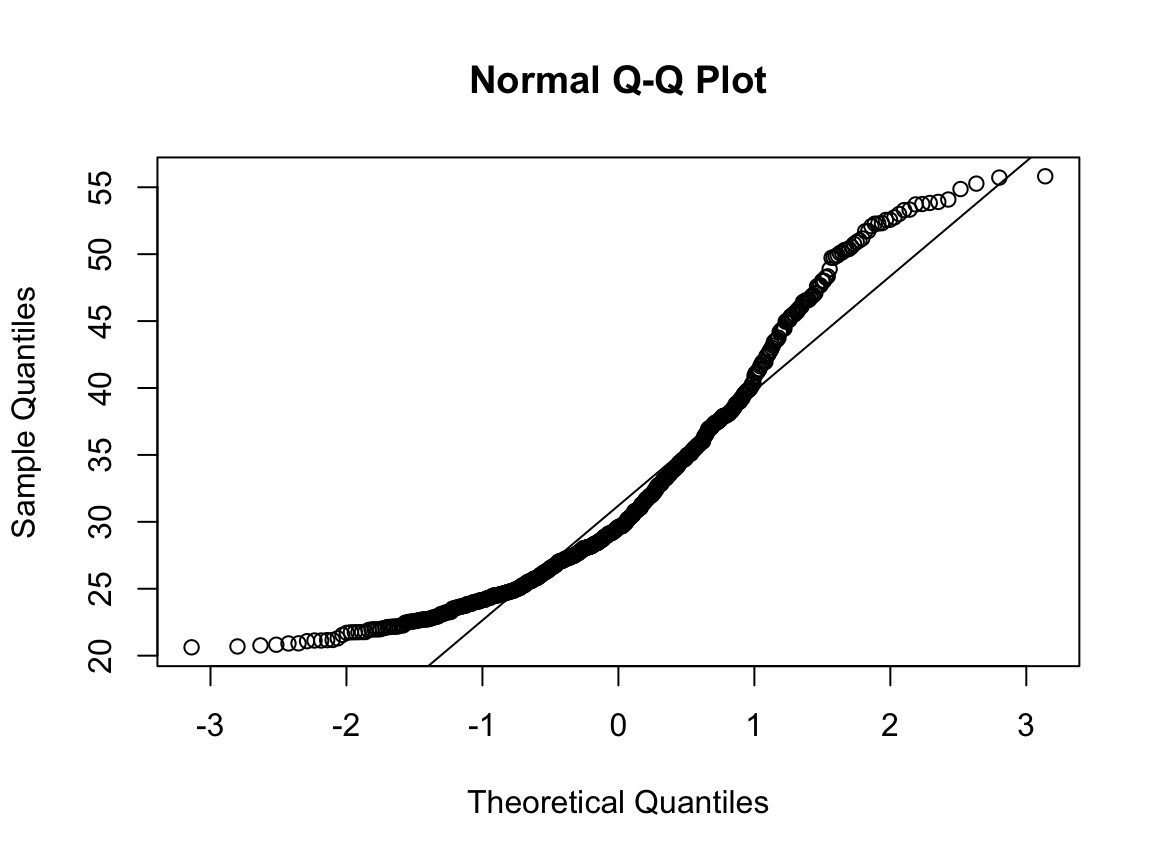
data: df$GGT_DIF
W = 0.94868, p-value < 2.2e-16
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않다. 히스토그램에서는 정규성을 따르는 것처럼 보이지만 이는 개인의 느낌이므로 정확한 것은 아니다. 따라서 대응 표본 T검정 (Paired sample T-test)를 시행할 수 없고, 윌콕슨 부호 순위 검정 (Wilcoxon Signed Rank Test)을 시행해야 한다.
그런데, 눈치를 챈 독자도 있겠지만, 비모수 일표본 검정도, 대응 표본 검정도 모두 윌콕슨 부호 순위 검정을 실시한다. 이는 모수적인 방법에서 대응 표본 T 검정 (paired T test)가 사실 일표본 T 검정 (One sample T test)와 같다는 것과 일맥상통하는 이야기다. 이 말을 비틀어 생각하면, 일표본 윌콕슨 부호 순위 검정으로 대응표본 윌콕슨 부호 순위 검정을 시행할 수 있다는 말이다. 즉 위에서 만들 DDT_DIF변수로 0에 대해 일표본 윌콕슨 부호 순위 검정을 시행하면 같은 결과를 내는 것을 확인할 수 있다.
코드
wilcox.test(df$GGT_DIF, mu=0, correct=FALSE)
결과
Wilcoxon signed rank test
data: df$GGT_DIF
V = 22907, p-value < 2.2e-16
alternative hypothesis: true location is not equal to 0
코드 정리
##워킹 디렉토리 지정
setwd("C:/Users/user/Documents/Tistory_blog")
##데이터 불러오기
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
##GGT 차이 변수 만들기
df$GGT_DIF<-df$GGT-df$GGT_POSTMED
##GGT_DIF의 정규성 검정
# 1) Q-Q plot 그리기
qqnorm(df$GGT_DIF)
qqline(df$GGT_DIF)
# 2) 히스토그램 그리기
hist(df$GGT_DIF, prob=TRUE, breaks=20)
GGT_DIFrange<-seq(min(df$GGT_DIF),max(df$GGT_DIF),length=max(max(df$GGT_DIF)-min(df$GGT_DIF),100))
ND<-dnorm(GGT_DIFrange,mean=mean(df$GGT_DIF),sd=sd(df$GGT_DIF))
lines(GGT_DIFrange, ND, lwd=2)
# 3) Shapiro-Wilk test 시행하기
shapiro.test(df$GGT_DIF)
##윌콕슨 부호 순위 검정 시행하기
wilcox.test(df$GGT, df$GGT_POSTMED, correct=FALSE, paired=TRUE)
##일표본 윌콕슨 부호 순위 검정 시행하기
wilcox.test(df$GGT_DIF, mu=0, correct=FALSE)
[R] 윌콕슨 부호 순위 검정 (비모수 짝지어진 표본 중앙값 검정: Wilcoxon signed rank test) 정복 완료!
[R] 윌콕슨 순위 합 검정, 맨 휘트니 U 검정 (비모수 독립 표본 중앙값 검정: Wilcoxon rank sum test, Mann-Whitney U test) - wilcox.test()
두 분포의 평균이 다른지 확인하는 방법을 이전에는 독립 표본 T검정 (Two-Sample T test)로 시행했었다. (2022.11.12 - [모평균 검정/R] - [R] 독립 표본 T검정 (Independent samples T-test) - t.test(), var.test(), levene.test()) 하지만 여기에는 중요한 가정이 필요한데, 각각의 분포가 정규성을 따르는 것이다. 하지만 분포가 정규성을 따르지 않는다면 어떻게 해야 할까? 그럴 때 사용하는 것이 Wilcoxon rank sum test (윌콕슨 순위 합 검정)이다. 윌콕슨 순위 합 검정 (Wilcoxon rank sum test)는 이후에 Mann과 Whitney가 개정을 하였고 그때 U 통계량을 사용하므로 맨 휘트니 U 검정(Mann-Whitney U test)이라고도 한다. 또한 세 사람의 이름을 붙여 Wilcoxon-Mann-Whitney Test (WMW test)라고도 한다.
이번 포스팅에서는 윌콕슨 순위 합 검정 (Wilcoxon rank sum test)에 대해 알아볼 것이다.
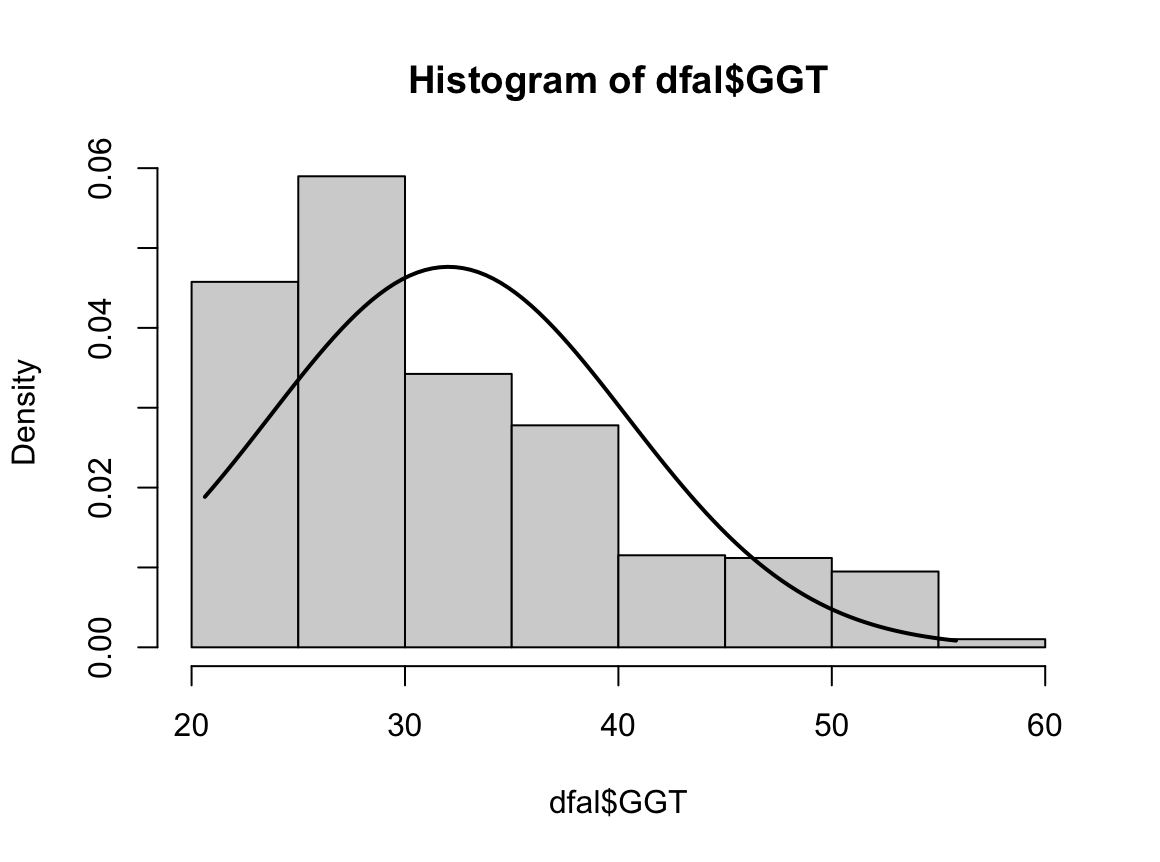
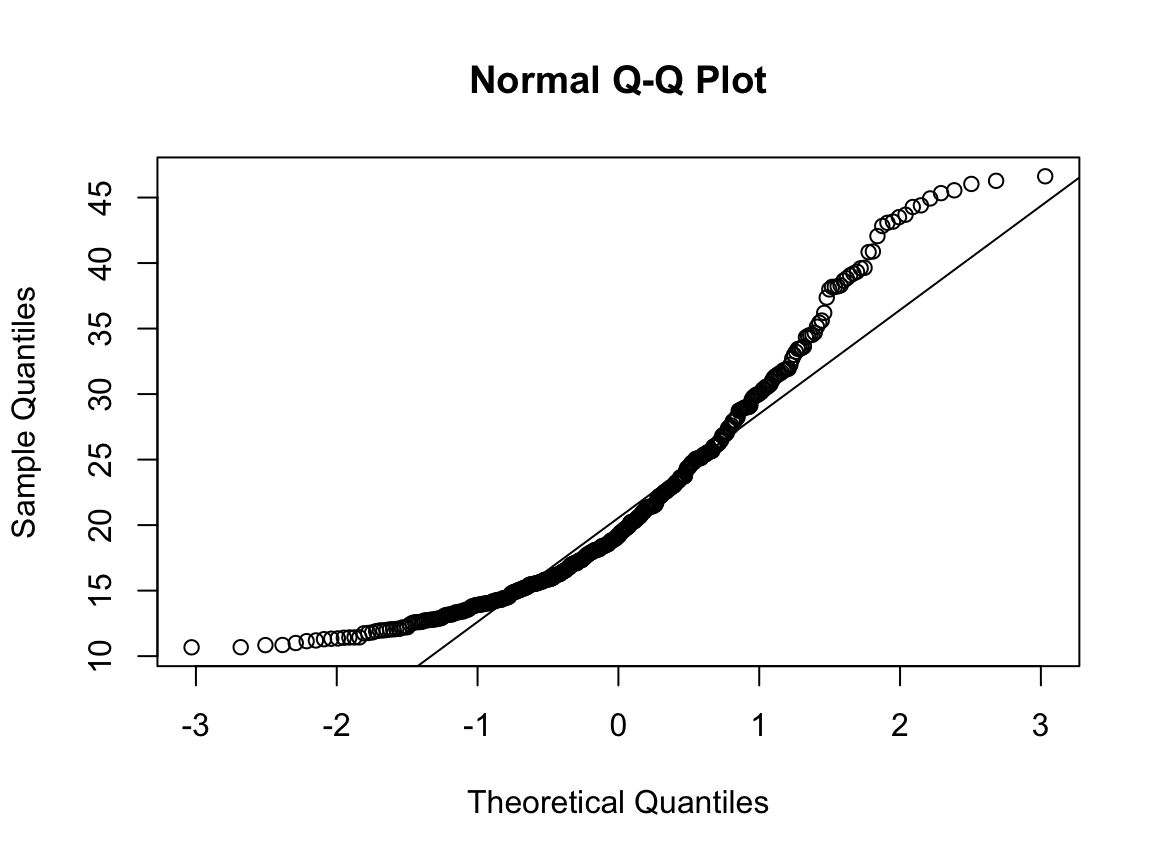
Shapiro-Wilk normality test
data: dfal$GGT
W = 0.91166, p-value < 2.2e-16
2) 비음주자
Shapiro-Wilk normality test
data: dfno$GGT
W = 0.90691, p-value = 3.637e-15
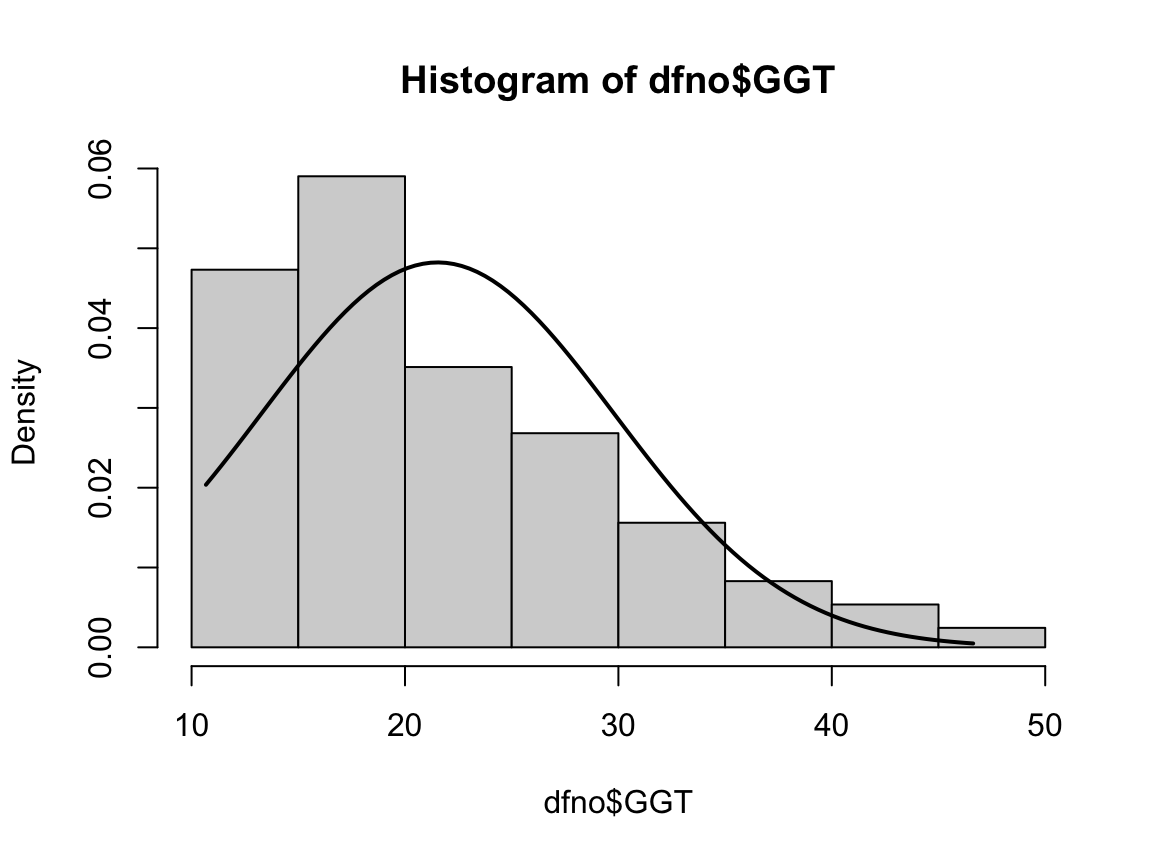
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이하이며, Q-Q Plot은 대부분의 데이터가 선상에 있지 않고, 히스토그램에서도 정규성을 따르지 않는 것처럼 보인다. 따라서 독립 표본 T검정 (Two-sample T-test)를 시행할 수 없고, 맨 휘트니 U 검정 (Mann-Whitney U test)을 시행해야 한다.
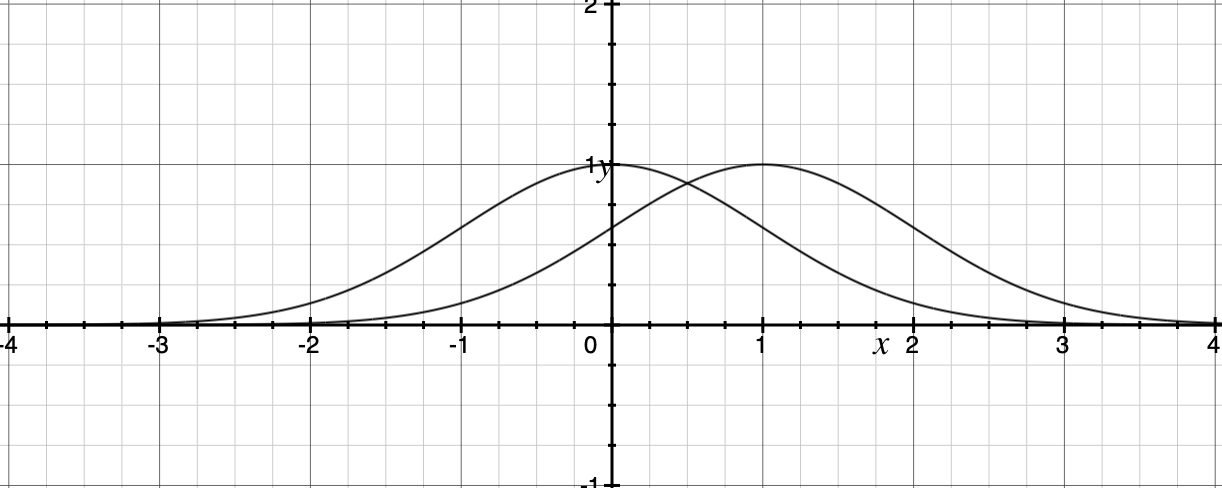
그런데 위 히스토그램을 보면 음주자와 비음주자의 GGT분포는 right skewed 된 분포로 어느 정도 비슷하게 생겼다. 모든 central moment를 조사하는 것은 현실적으로 힘들지만, 2nd cental moment인 분산의 차이를 검정해보면 다음과 같음을 알 수 있다. 등분산성 검정 방법은 다음 링크를 확인하길 바란다.
F test to compare two variances
data: dfal$GGT and dfno$GGT
F = 1.0248, num df = 589, denom df = 409, p-value = 0.7922
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.8559314 1.2234543
sample estimates:
ratio of variances
1.024817
p-value는 0.7922로 분산에 차이가 없다고 결론 내리는 것이 합당하다.
따라서 두 분포의 모양이 같다고 생각하면 본 맨 휘트니 U 검정으로 음주자와 비음주자의 GGT값에는 차이가 있다고 결론 내릴 수 있다.
> median(df$NP3_raw)
[1] 0.9968156
> median(df$NP4_raw)
[1] 0.9968156
> var(df$NP3_raw)
[1] 0.2237356
> var(df$NP4_raw)
[1] 0.2237356
> var.test(df$NP3_raw, df$NP4_raw)
F test to compare two variances
data: df$NP3_raw and df$NP4_raw
F = 1, num df = 999, denom df = 999, p-value = 1
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.8832987 1.1321198
sample estimates:
ratio of variances
1
> wilcox.test(df$NP3_raw, df$NP4_raw, correct=FALSE)
Wilcoxon rank sum test
data: df$NP3_raw and df$NP4_raw
W = 568902, p-value = 9.515e-08
alternative hypothesis: true location shift is not equal to 0
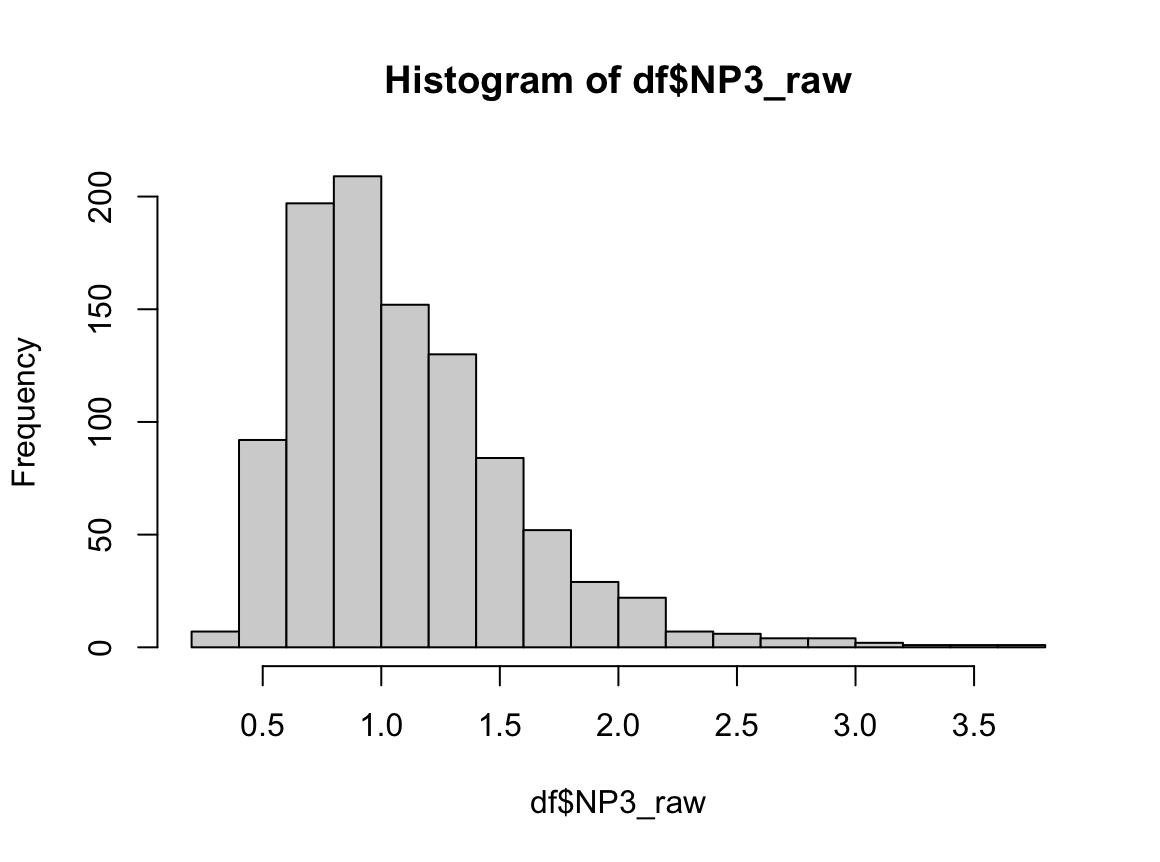
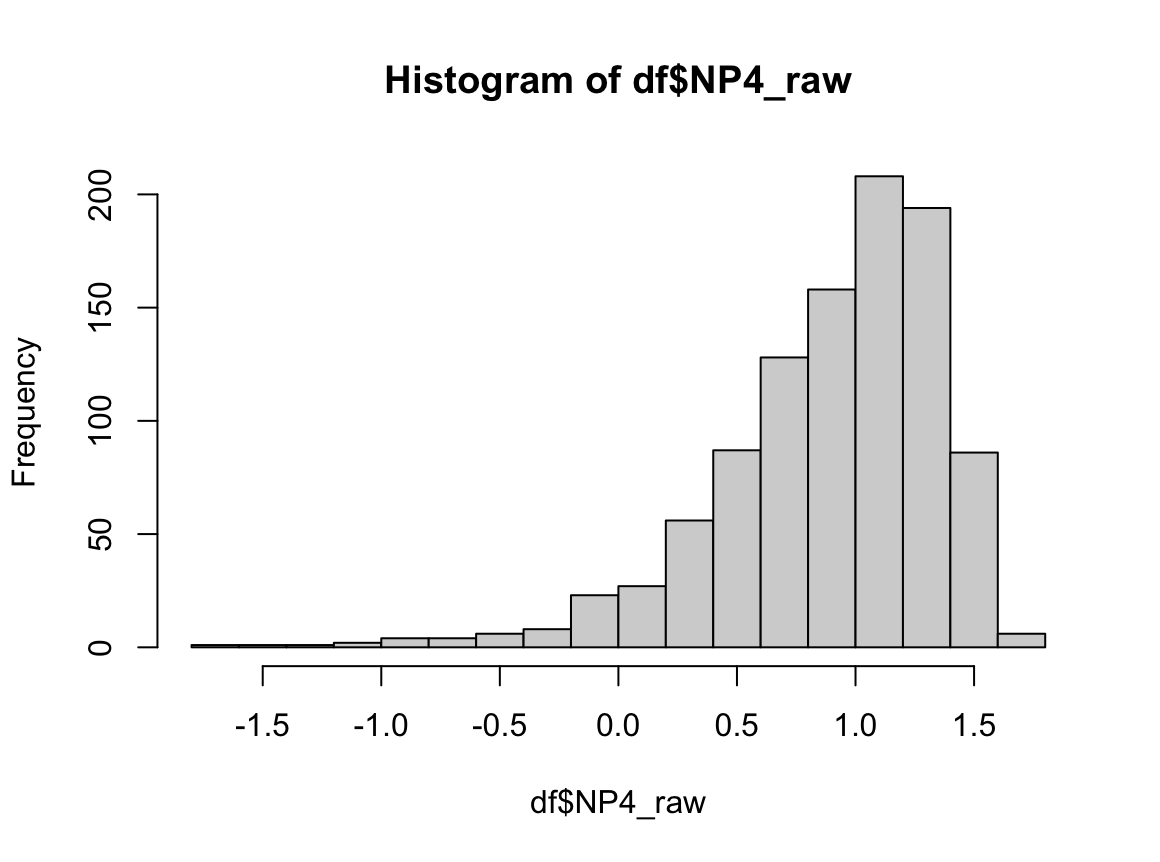
NP3_raw는 right skewed, NP4_raw는 left skewed로 서루 매우 다르게 생겼지만, 분산, 중앙값이 완벽히 일치하며, 등분산성 검정에서도 분산에 차이가 없다고 나온다. 하지만 맨 휘트니 U 검정 결과 p-value는 매우 작게 나온다. 만약 맨 휘트니 U 검정이 "중앙값이 같은지 확인하는 검정"이라고만 알고 있다면 중앙값이 완전히 같은 이런 경우에도 "중앙값에 차이가 있다."라고 결론 내릴 것이다. 하지만 이 경우 귀무가설을 기각하고 "두 분포는 다르게 생겼다."라고 결론 내려야 옳은 결론에 다다른다.
2) 분석하고자 하는 변수인 QOL을 "종속변수"에 넣어준다. 거주 지역 단위에 따라 정규성을 검정할 것이므로 "요인(F)"에 RESID를 넣는다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
결과
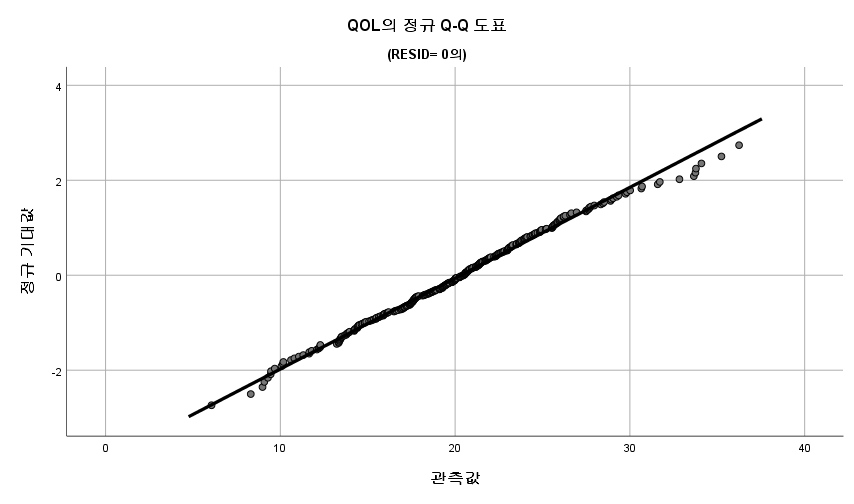
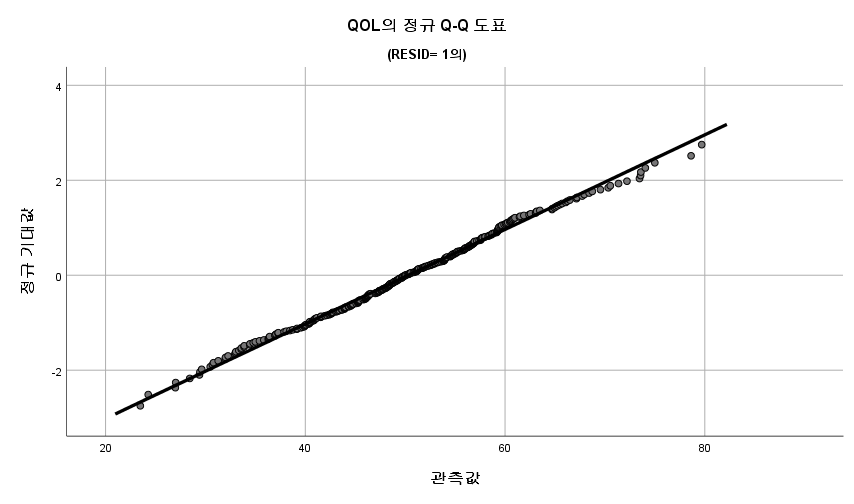
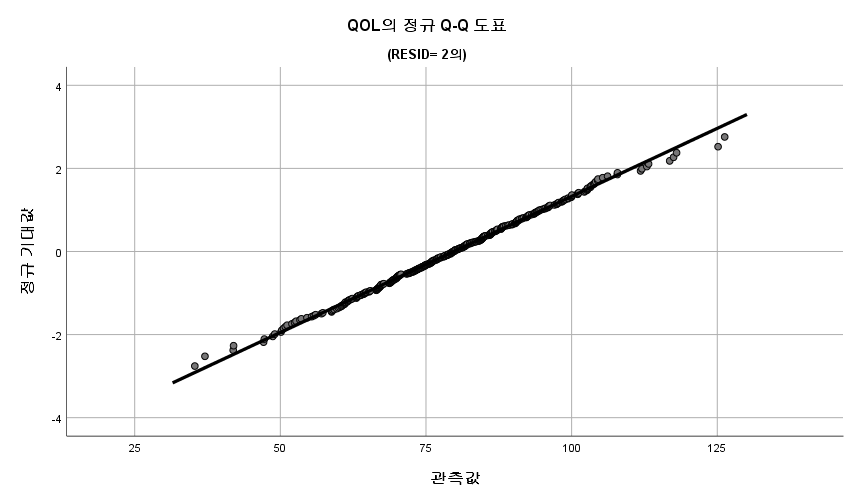
1) Q-Q plot
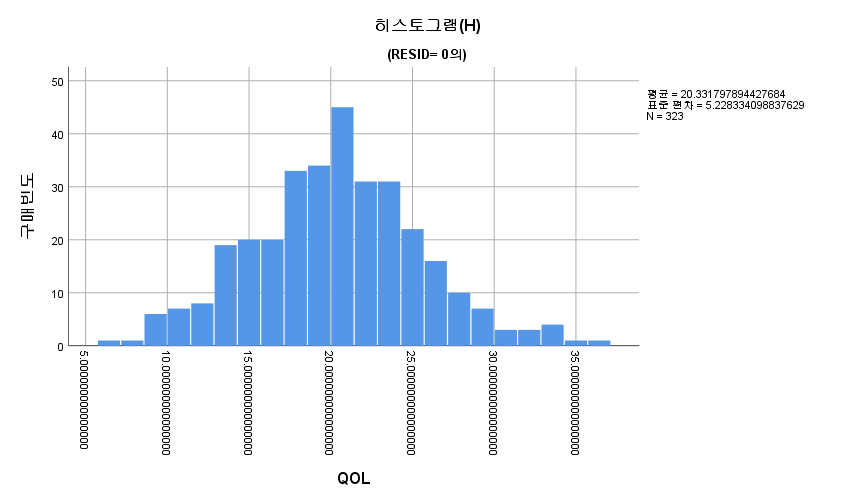
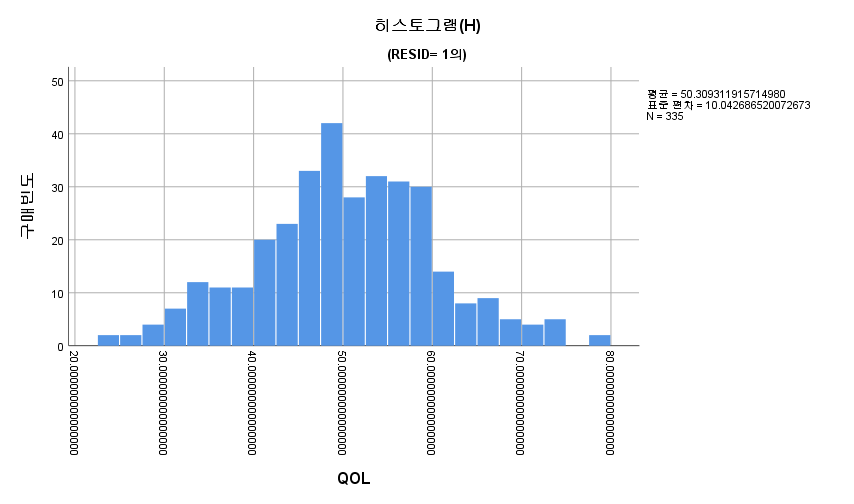
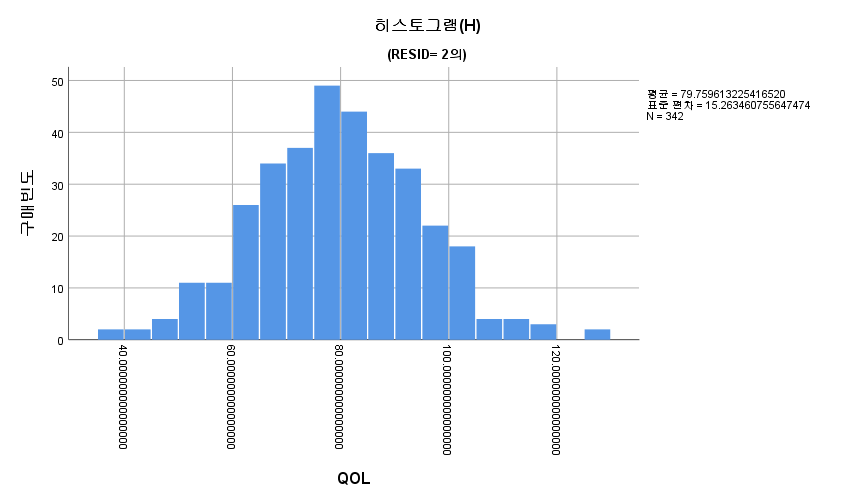
2) 히스토그램
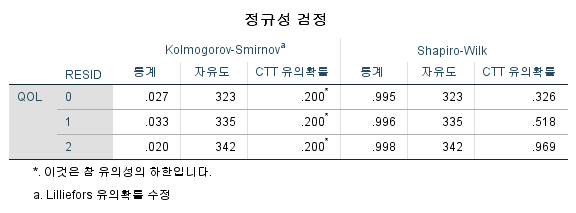
3) Shapiro-Wilk 검정
표본의 수가 2,000이 되지 않으므로 Shapiro-Wilk 통계량의 p-value를 보아야 하고, 이는 0.05보다 크다. Q-Q plot, 히스토그램에서 정규성을 띠지 않는다고 할만한 근거가 없으므로 정규성을 따른다고 결론을 짓는다.
따라서 정규성 전제는 따른다고 할 수 있다.
Welch's & Brown-Forsythe ANOVA 실행 방법
1) 분석(A) > 평균 비교 (M) > 일원배치 분산분석(O)
2) 분석하고자 하는 변수 QOL를 "종속변수(E)"쪽으로 옮기고, RESID을 "요인(F)"쪽으로 옮긴다. 그리고 "옵션"을 누른다.
3) "분산 동질성 검정(H)" 체크박스를 선택한다. 분산이 같지 않을 경우를 대비해 "Brown-Forsythe", "Welch" 체크박스를 클릭한다. 그리고 "계속 (C)"을 누른다.
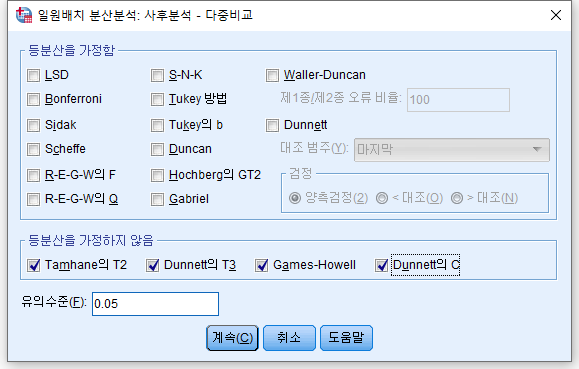
4) "사후분석(H)"을 클릭한다.
분산이 같지 않을 경우에만 대비하여 "Tanhame의 T2", "Dunnett의 T3", "Games-Howell", "Dunnett의 C"를 클릭한다. 분산이 같지 않은 경우 위쪽에 있는 사후 분석 방법은 사용할 수 없고 아래 사후 분석만 사용할 수 있다.
결과
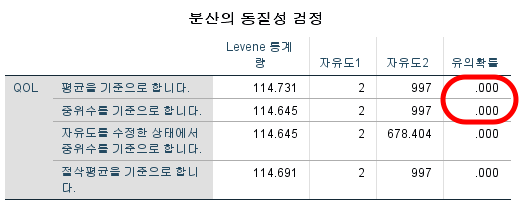
1) 등분산성 검정
맨 위에 평균을 기준으로 한 검정이 일반적인 Levene의 등분산 검정이다.
그다음 중위수를 기준으로 한 검정이 Brown-Forsythe의 등분산성 검정이다.
어떤 것을 선택하는지는 개인의 선택이다. 하지만 이 경우 둘 다 0.05보다 작으므로 귀무가설을 기각하고, 분산에 차이가 있다고 결론 내린다.
2) 일반 ANOVA
.
분산이 다르다고 결론 내렸으므로 이 표는 보면 안 된다.
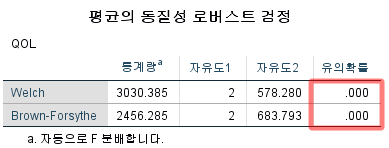
3) Welch, Brown-Forsythe ANOVA
두 가지 방법 모두 p-value가 0.001보다 작다고 이야기하고 있다. 따라서 귀무가설을 기각하고 대립 가설을 채택한다. 그렇다면 여기에서 귀무가설 및 대립 가설은 무엇이었는가?
귀무가설: $H_0 =$세 집단의 모평균은 "모두" 동일하다.
대립 가설: $H_1 =$세 집단의 모평균이 모두 동일한 것은 아니다.
우리는 대립 가설을 채택해야 하므로 "세 집단의 모평균이 모두 동일한 것은 아니다."라고 결론 내릴 것이다.
그런데, 세 집단의 모평균이 모두 동일하지 않다는 말은 세 집단 중 두 개씩 골라 비교했을 때, 적어도 한 쌍에서는 차이가 난다는 것이다. 따라서 세 집단 중 두 개씩 골라 비교를 해보아야 하며, 이를 사후 분석 (post hoc analysis)이라고 한다. 세 집단에서 두 개씩 고르므로 가능한 경우의 수는$_3C_2=3$이다.
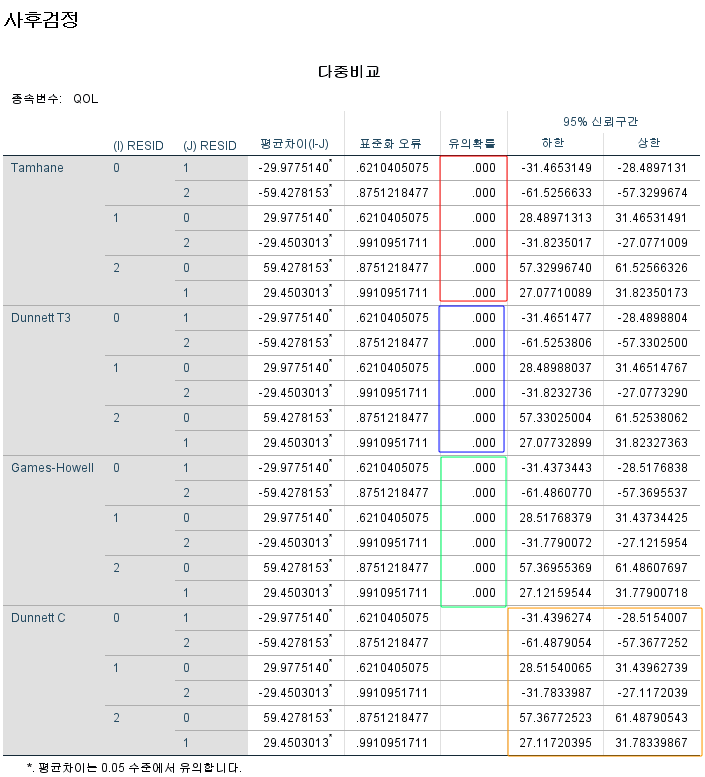
Dunnett C를 제외하고, 어떤 방법을 사용하든, 모든 비교에서 p-value는 0.001보다 작아 매우 유의하다. 그리고 Dunnett C는 신뢰구간에 0이 포함되지 않으면 유의한 것인데, 0을 포함하는 구간이 없다. 따라서 모든 비교에서 유의미한 FVC의 차이가 있다고 할 수 있다.
어떤 사후 분석을 쓸 것인가
이 논의에 대해 정답이 따로 있는 것은 아니다. 적절한 방법을 사용하여 논문에 제시하면 되고, 어떤 것이 정답이라고 콕 집어 이야기할 수는 없다. 다만, 사후 분석 방법이 여러 가지가 있다는 것은 '사후 분석 방법에 따라 산출되는 결과가 달라질 수 있다.'는 것을 의미하고, 심지어는 '어떤 사후 분석 방법을 채택하냐에 따라 유의성 여부가 달라질 수도 있다.'는 것을 의미한다. 심지어, Welch's or Brown-Forsythe's ANOVA에서는 유의한 결과가 나왔는데, 사후 분석을 해보니 유의한 차이를 보이는 경우가 없을 수도 있다. 따라서 어떤 사후 분석 방법 결과에 따른 결과인지 유의하여 해석할 필요가 있다.
[SPSS] 등분산 가정이 성립하지 않는 일원 배치 분산 분석 (Welch's ANOVA, Brown-Forsythe ANOVA) 정복 완료
음주 여부는 "1) 음주자", "2) 비음주자"로 나뉘는 이분형 변수다. 즉, 음주자의 ALT 평균과 비음주자의 ALT 평균을 비교한 것이었다.
만약, 두 개 이상의 범주로 나뉘는 변수에 대해 모평균의 검정을 하고자 한다면 어떻게 해야 할까? 예를 들어, 흡연 상태를 "1) 비흡연자", "2) 과거 흡연자", "3) 현재 흡연자"로 나누었고, 각 그룹의 폐기능 검사 중 하나인 FVC (Forced Vital Capacity)의 평균에 차이가 있는지 알아보고자 한다.
이때 사용할 수 있는 방법이 일원 배치 분산 분석인 One-way ANOVA (Analysis of Variance)이며 이번 포스팅에서 다뤄볼 주된 내용이다.
2) 분석하고자 하는 변수인 FVC_pPRED을 "종속변수"에 넣어준다. 흡연 상태에 따라 분석할 것이므로 "요인(F)"에 SMOK을 넣는다. 그 뒤 "도표(T)..."를 선택한다.
3) "히스토그램(H)", "검정과 함께 정규성 도표(O)" 체크박스를 클릭하고 "계속(C)"를 누르고, 돌아가 "확인"을 누른다.
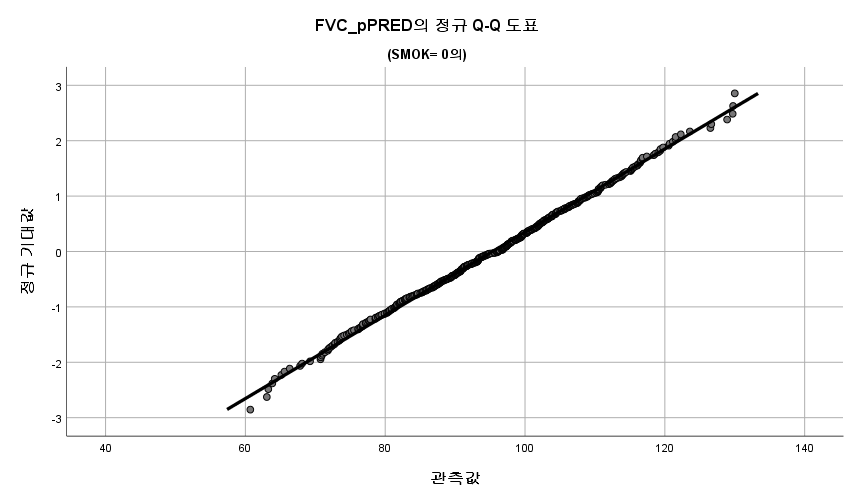
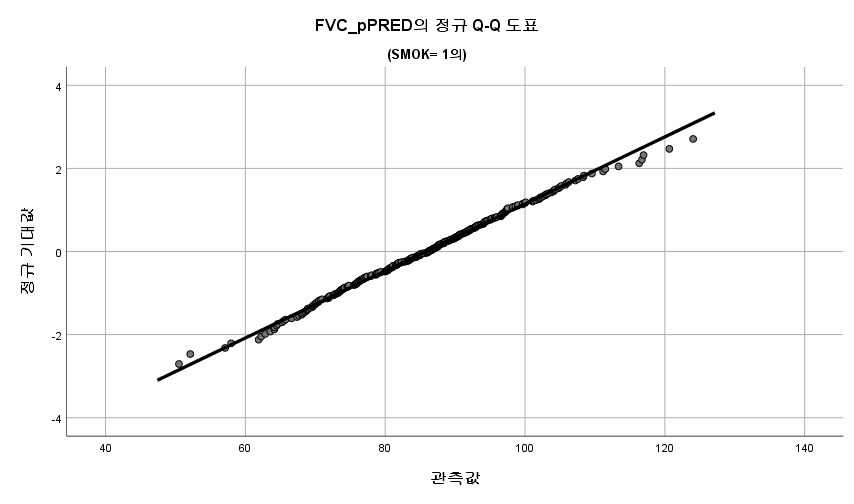
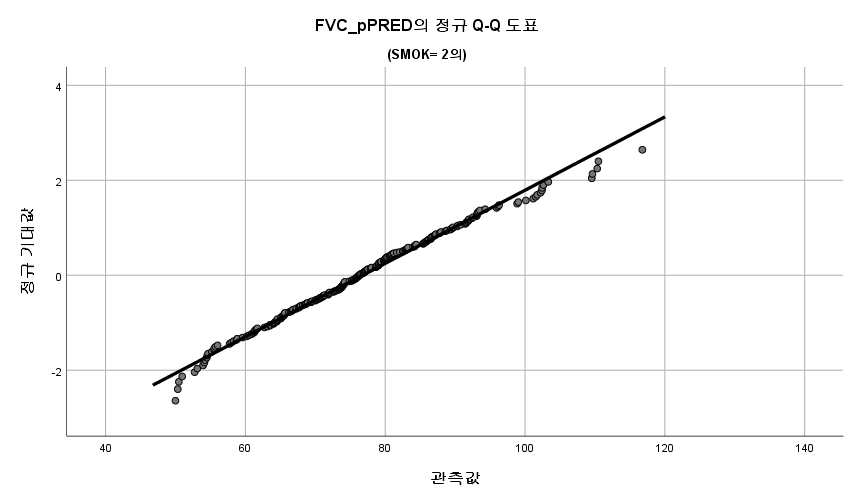
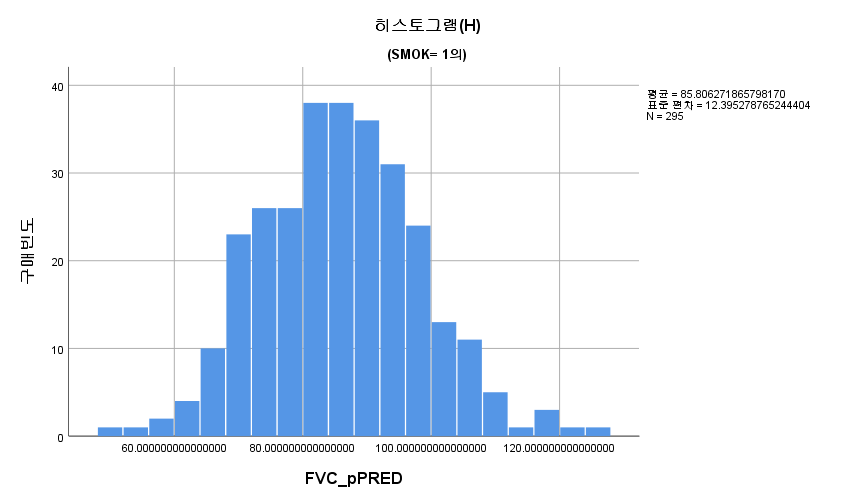
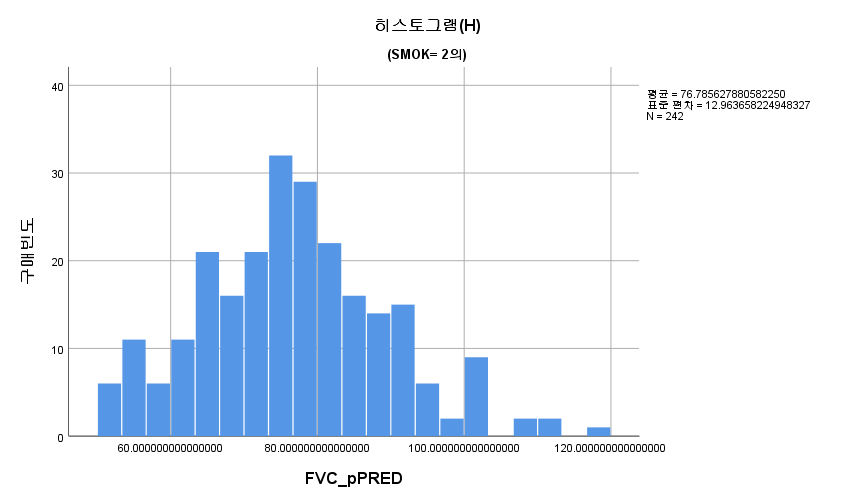
결과 1) Q-Q plot
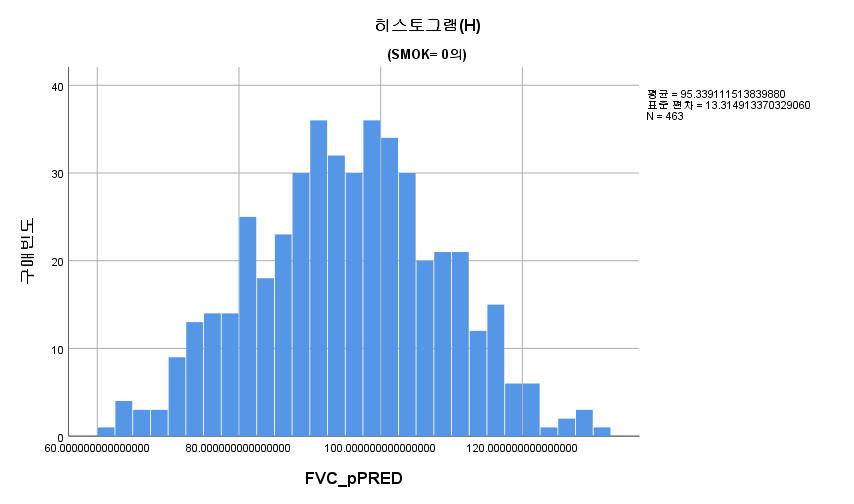
2) 히스토그램
3) Shapiro-Wilk 검정
표본의 수가 2,000이 되지 않으므로 Shapiro-Wilk 통계량의 p-value를 보아야 하고, 이는 0.05보다 크다. Q-Q plot, 히스토그램에서 정규성을 띠지 않는다고 할만한 근거가 없으므로 정규성을 따른다고 결론을 짓는다.
따라서 정규성 전제조건은 만족한다고 할 수 있다.
일원 배치 분산 분석 (ANOVA) 방법
1) 분석(A) > 평균 비교 (M) > 일원배치 분산분석(O)
2) 분석하고자 하는 변수 FVC_pPRED를 "종속변수(E)"쪽으로 옮기고, SMOK을 "요인(F)"쪽으로 옮긴다. 그리고 "옵션"을 누른다.
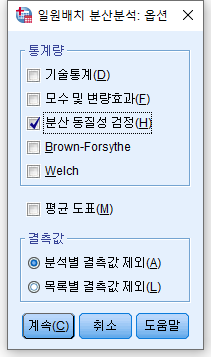
3) "분산 동질성 검정(H)" 체크박스를 선택한다. 그리고 "계속 (C)"을 누른다.
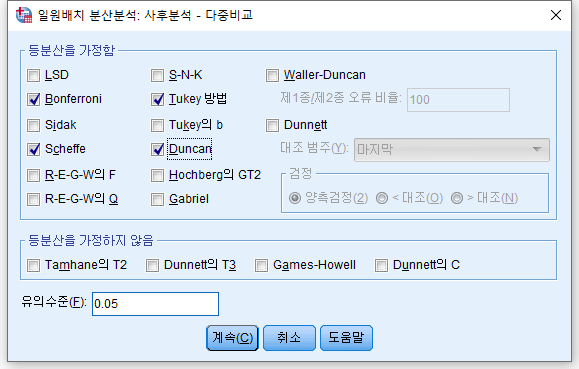
4) "사후분석(H)"을 클릭한다.
많은 사후분석 방법이 있지만 우리는 Bonferroni, Scheffe, Tukey, Duncan을 확인하도록 한다. 이 네 개를 체크한다.
결과
1) 등분산성 검정
ANOVA의 두 번째 전제조건인 등분산성에 대한 검정이다.
맨 위에 평균을 기준으로 한 검정이 일반적인 Levene의 등분산 검정이다.
그다음 중위수를 기준으로 한 검정이 Brown-Forsythe의 등분산성 검정이다.
어떤 것을 선택하는지는 개인의 선택이다. 하지만 이 경우 둘 다 0.05보다 크므로 귀무가설을 받아들여, 분산에 차이가 없다고 결론 내린다. 따라서 전제조건을 만족함을 알 수 있다.
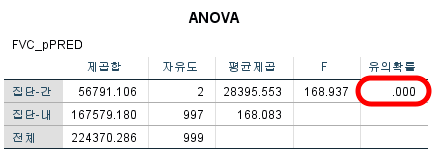
2) ANOVA결과
ANOVA의 결과는 집단-간 유의 확률을 확인하면 된다. p-value<0.001으로 유의하다. 따라서 귀무가설을 기각하고 대립 가설을 선택한다. 그렇다면 여기에서 귀무가설 및 대립 가설은 무엇이었는가?
귀무가설: $H_0 =$ 세 집단의 모평균은 "모두" 동일하다.
대립 가설: $H_1 =$ 세 집단의 모평균이 모두 동일한 것은 아니다.
우리는 대립 가설을 채택해야 하므로 "세 집단의 모평균이 모두 동일한 것은 아니다."라고 결론 내릴 것이다.
이 말은, 세 집단 중 두 개씩 골라 비교했을 때, 적어도 한 쌍에서는 차이가 난다는 것이다. 따라서 세 집단 중 두 개씩 골라 비교를 해보아야 하며, 이를 사후 분석 (post hoc analysis)이라고 한다. 세 집단에서 두 개씩 고르므로 가능한 경우의 수는 $_3C_2 =3$이다.
(1) 비흡연자 vs 과거 흡연자
(2) 비흡연자 vs 현재 흡연자
(3) 과거 흡연자 vs 현재 흡연자
사후 분석 결과 부분을 보겠다.
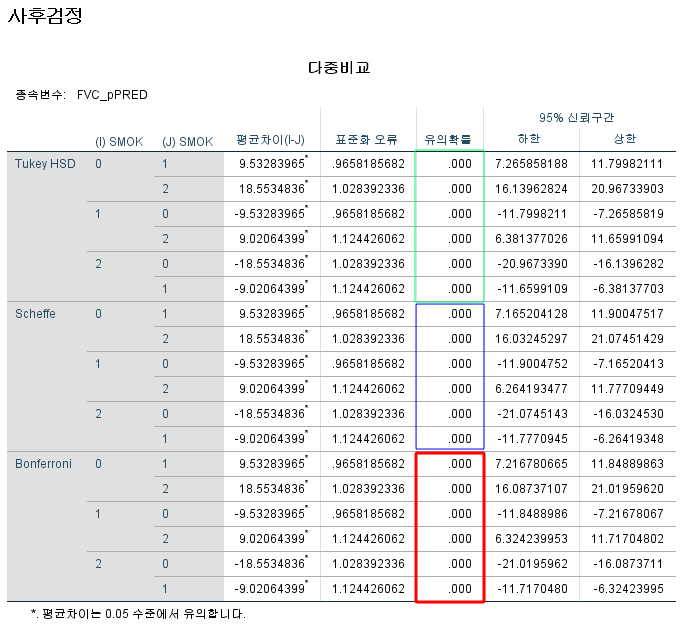
1) 사후검정 1 - Tukey, Scheffe, Bonferroni
Duncan을 제외한 방법은 각 차이에 대한 보정된 p-value를 보여준다. 위 표를 보는 법은 다음과 같다.
0
1
비흡연자 (0)와 과거 흡연자 (1) 사이의 비교
2
비흡연자 (0)와 현재 흡연자 (2) 사이의 비교
1
0
비흡연자 (0)와 과거 흡연자 (1) 사이의 비교
2
과거 흡연자 (1)와 현재 흡연자 (2) 사이의 비교
2
0
비흡연자 (0)와 현재 흡연자 (2) 사이의 비교
1
과거 흡연자 (1)와 현재 흡연자 (2) 사이의 비교
어떤 방법을 사용하든, 모든 비교에서 p-value는 0.001보다 작아 매우 유의하므로 모든 비교에서 유의미한 FVC의 차이가 있다고 할 수 있다.
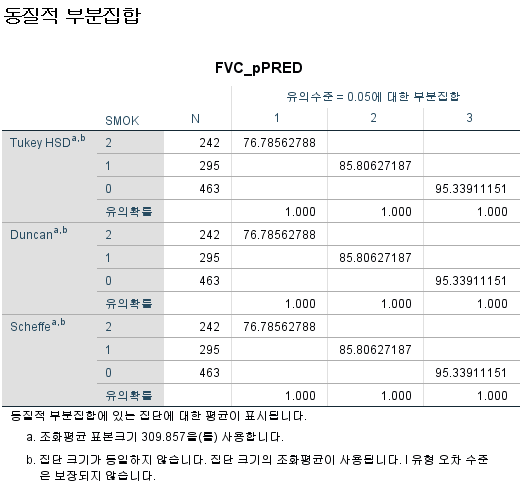
2) 사후검정 2 - Tukey, Duncan, Scheffe
Bonferroni는 동질적 부분집합으로 표현해주지 않으며, Duncan은 동질적 부분집합으로만 표현해준다.
위 세 개 모두 같은 결과를 보여주고 있다. 해석하는 방법은 다음과 같다.
SMOK=2는 평균이 76.78562788이며, 부분집합 1에 속한다.
SMOK=1는 평균이 85.80627187이며, 부분집합 2에 속한다.
SMOK=0는 평균이 95.33911151이며, 부분집합 3에 속한다.
속한 부분집합이 다르면 평균에 유의미한 차이가 있다는 것이다. 부분집합 1, 2, 3은 서로 다른 평균을 가진 모집단에서 유래했다고 볼 수 있으므로 비흡연자, 과거 흡연자, 현재 흡연자는 서로 다른 평균을 갖고 있다고 할 수 있다.
이 시점에서 이런 의문이 들 수 있다.
"각각의 그룹별로 평균을 비교하면 되지, 굳이 왜 ANOVA라는 방법까지 사용하는 것인가?"
아주 논리적인 의문점이다. 하지만, 반드시 ANOVA를 사용해야 한다. 그 이유는 다음과 같다. 본 사례는 흡연 상태에 따른 조합 가능한 경우의 수가 3인데, 각각 유의성의 기준을 $\alpha=0.05$로 잡아보자. 이때 세 번의 비교에서 모두 귀무가설이 학문적인 진실인데(평균에 차이가 없다.), 세 번 모두 귀무가설을 선택할 확률은 $\left(1-0.05 \right)^3 \approx 0.86$이다. (이해가 어려우면 p-value에 대한 설명 글을 읽고 오길 바란다. 2022.09.05 - [통계 이론] - [이론] p-value에 관한 고찰)
그런데, ANOVA의 귀무가설은 "모든 집단의 평균이 같다."이다. 따라서 모든 집단의 평균이 같은 것이 학문적 진실일 때, 적어도 한 번이라도 대립 가설을 선택하게 될 확률은 1−0.86=0.141−0.86=0.14가 된다. 즉, 유의성의 기준이 올라가게 되어, 덜 보수적인 결정을 내리게 되고, 다시 말하면 대립 가설을 잘 선택하는 쪽으로 편향되게 된다. 학문적으로는 '다중 검정 (multiple testing)을 시행하면 1종 오류가 발생할 확률이 증가하게 된다.'라고 표현한다.
따라서, 각각을 비교해보는 것이 아니라 한꺼번에 비교하는 ANOVA를 시행해야 함이 마땅하다.
여기에서 한 번 더 의문이 들 수 있다.
"사후 분석을 할 때에는 1종 오류가 발생하지 않는가?"
그렇다. 1종 오류가 발생할 확률이 있으므로, p-value의 기준을 더 엄격하게 (0.05보다 더 작게) 잡아야 한다. P-value를 보정하는 방법은 여러 가지가 나와있는데, 가장 간단하고 제일 보수적인 방법이 위에 예시에서 사용한 본페로니 방법이다. 그 외에도 굉장히 많은 방법이 있지만, Bonferroni, Duncan, Scheffe, Tukey가 가장 많이 쓰이는 듯하다. 이 중에 Duncan, Tukey는 그룹별로 표본의 수가 같을 때만 사용해야 하므로 유의하도록 한다.
어떤 사후 분석을 쓸 것인가
이 논의에 대해 정답이 따로 있는 것은 아니다. 적절한 방법을 사용하여 논문에 제시하면 되고, 어떤 것이 정답이라고 콕 집어 이야기할 수는 없다. 다만, 사후 분석 방법이 여러 가지가 있다는 것은 '사후 분석 방법에 따라 산출되는 결과가 달라질 수 있다.'는 것을 의미하고, 심지어는 '어떤 사후 분석 방법을 채택하냐에 따라 유의성 여부가 달라질 수도 있다.'는 것을 의미한다. 심지어, ANOVA에서는 유의한 결과가 나왔는데, 사후 분석을 해보니 유의한 차이를 보이는 경우가 없을 수도 있다. 따라서 어떤 사후 분석 방법 결과에 따른 결과인지 유의하여 해석할 필요가 있다.
[SPSS] 일원 배치 분산 분석 (One-way ANOVA, ANalysis Of VAriance) 정복 완료!