
[SAS] 일표본 T검정 (One-sample T-test) - PROC TTEST
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
1) 일표본 T검정 (One sample T-test)
: 모집단의 평균이 특정 값이라고 할 수 있는가?
예) 모집단의 ALT 평균이 50이라고 할 수 있는가?
2) 독립 표본 T검정 (Independent samples T-test): 2022.10.04 - [모평균 검정/SAS] - [SAS] 독립 표본 T검정 (Independent samples T-test) - PROC TTEST
: 두 모집단의 평균이 다르다고 할 수 있는가?
예) 고혈압 환자와 일반인의 수축기 혈압 평균이 서로 다르다고 할 수 있는가?
3) 대응표본 T검정 (Paired samples T-test):2022.10.07 - [반복 측정 자료 분석/SAS] - [SAS] 대응 표본 T검정 (Paired samples T-test) - PROC TTEST
: 모집단의 짝지어진 변수들의 평균이 다르다고 할 수 있는가?
예) 간기능 개선제 복용 전 ALT 평균은 간기는 개선제 복용 후 ALT 평균과 다르다고 할 수 있는가?
이번 포스팅에서는 일표본 T검정 (One sample T-test)에 대해 알아볼 것이다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.29)
분석용 데이터 (update 22.08.29)
2022년 08월 29일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법 1) 엑셀 파일 2) CSV 파일 3) 코드북
medistat.tistory.com
시작하기 위해 라이브러리를 만들고, 파일을 불러온다.
라이브러리 만드는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 라이브러리 만들기 - LIBNAME
파일 불러오는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 데이터 불러오기 및 저장하기 - PROC IMPORT, PROC EXPORT
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
목표: 모집단의 ALT 평균이 50이라고 할 수 있는가?
이번 포스팅의 목적은 1000명의 데이터를 가지고, 이 1000명이 기원한 모집단의 ALT평균이 50이라고 할 수 있는지 판단하는 것이다.
전제조건 (정규성) - 코드
일표본 (One sample) T 검정의 전제조건은 해당 분포가 정규성을 따른다는 것이다. 정규성 검정을 하도록 하겠다. 정규성 검정에 관한 분석 내용은 다음 글에서 살펴볼 수 있다. 2022.08.12 - [기술 통계/SAS] - [SAS] 정규성 검정 - PROC UNIVARIATE
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
VAR ALT;
HISTOGRAM ALT/ NORMAL (MU=EST SIGMA=EST);
RUN;
정규성 검정 - 결과
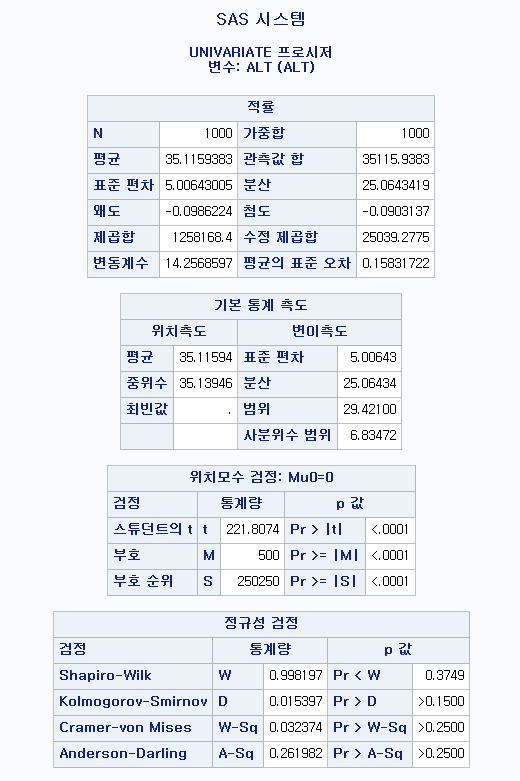
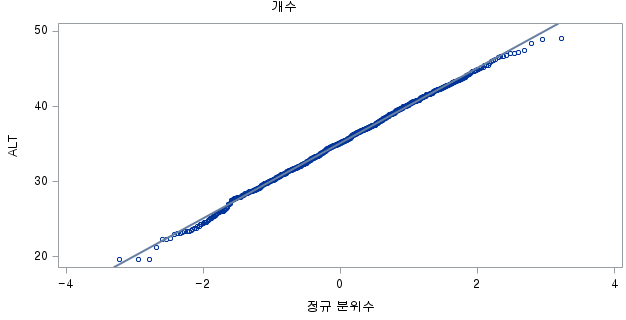
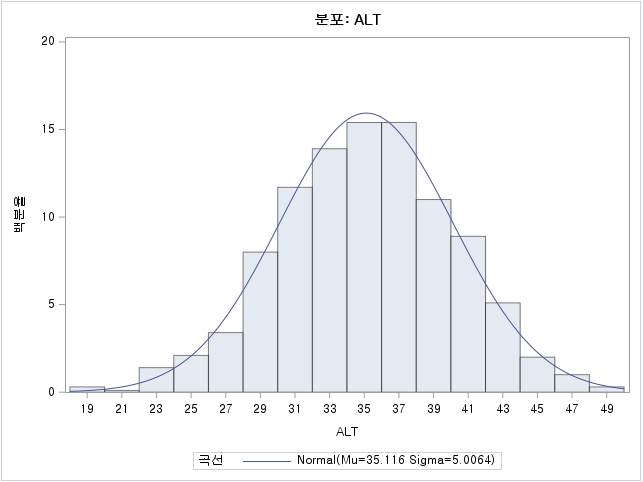
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다. 따라서 ALT로는 일표본 T검정 (One-sample T-test)를 시행할 수 있다.
일표본 T검정 (One sample T test)의 귀무가설과 대립 가설
이번 일표본 T검정 (One sample T test)의 귀무가설은 하나다.
귀무가설: $H_0=$ 모집단의 ALT 평균은 50이다.
하지만 대립 가설은 3개가 된다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
3) $H_1=$ 모집단의 평균은 50보다 크거나 작다. (양측 검정)
대립 가설 별로 코드를 보고자 한다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
PROC TTEST DATA=hong.df SIDES=U H0=50;
VAR ALT;
RUN;PROC TTEST DATA=hong.df SIDES=U H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 큰 쪽이며, 검정하고자 하는 모집단의 평균은 50이다.
VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
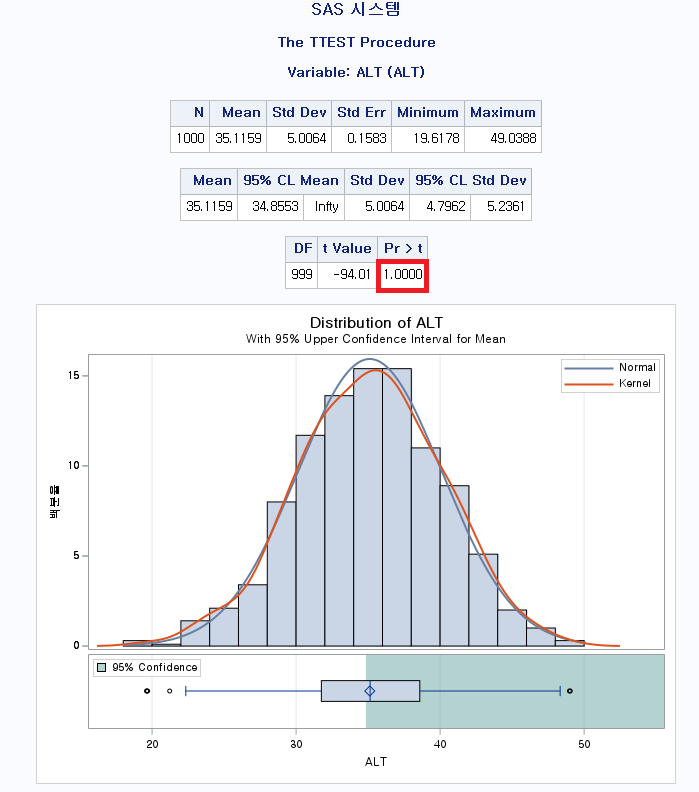
P-value는 1.0000이다. 즉, 대립 가설을 선택하는 것이 말이 안 된다는 것이다. 평균이 50보다 크다고 보는 것보다는 50이라고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
PROC TTEST DATA=hong.df SIDES=L H0=50;
VAR ALT;
RUN;PROC TTEST DATA=hong.df SIDES=L H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 작은 쪽이며, 검정하고자 하는 모집단의 평균은 50이다.
VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
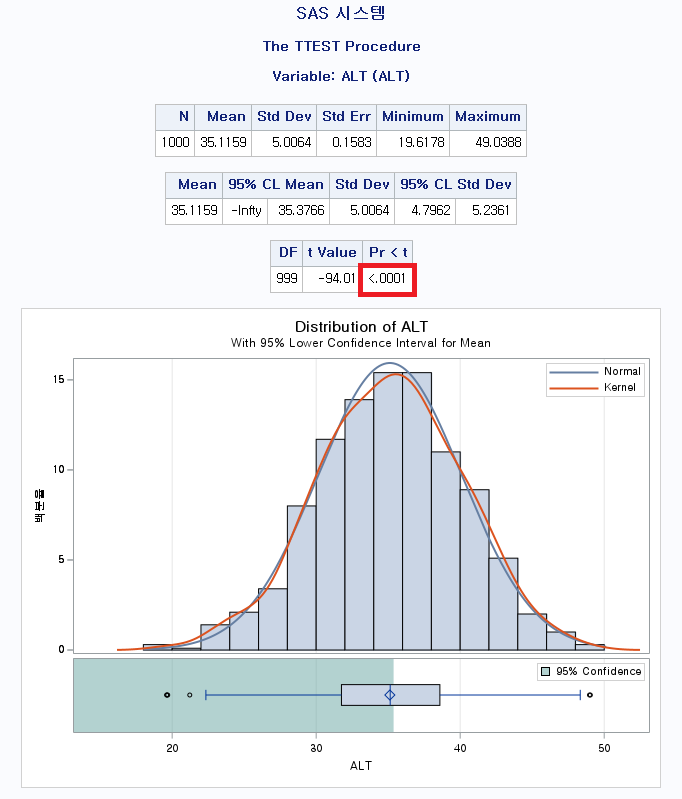
P-value는 <0.0001이다. 즉, 대립 가설을 선택하는 것이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
3) $H_1=$ 모집단의 평균은 50보다 작거나 크다. (양측 검정)
가장 많이 사용하는 양측 검정이다.
PROC TTEST DATA=hong.df SIDES=2 H0=50;
VAR ALT;
RUN;
PROC TTEST DATA=hong.df H0=50;
VAR ALT;
RUN;위 두 개의 코드는 같은 결과를 내준다. 왜냐하면 양측 검정 (SIDES=2)가 기본 값이어서 SIDES옵션을 지정해주지 않으면 SIDES=2라고 인식하고 코드가 돌아가기 때문이다.
PROC TTEST DATA=hong.df SIDES=2 H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 양쪽이며, 검정하고자 하는 모집단의 평균은 50이다.
VAR ALT; : 검정하고자 하는 변수는 ALT다.
PROC TTEST DATA=hong.df H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 양쪽이며, 검정하고자 하는 모집단의 평균은 50이다.
VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
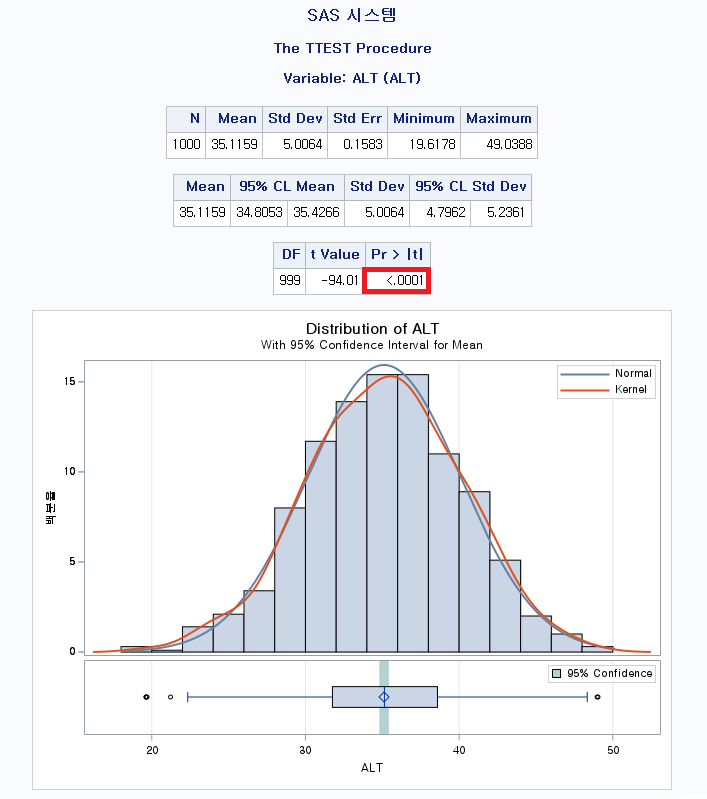
P-value는 <0.0001이다. 즉, 대립 가설을 선택하는 것이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작거나 크다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
주로 양측 검정이 이용되나, 사실 일표본 T검정은 거의 시행되지 않고 다음 글로 나올 독립 표본 T검정이 더 많이 사용된다.
코드 정리
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
*정규성 검정;
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
VAR ALT;
HISTOGRAM ALT/ NORMAL (MU=EST SIGMA=EST);
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 크다. (단측검정)
PROC TTEST DATA=hong.df SIDES=U H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작다. (단측검정)
PROC TTEST DATA=hong.df SIDES=L H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작거나 크다. (양측검정)
PROC TTEST DATA=hong.df SIDES=2 H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작거나 크다. (양측검정)
PROC TTEST DATA=hong.df H0=50;
VAR ALT;
RUN;
SAS 일표본 T검정 (One-sample T-test) 정복 완료!
작성일: 2022.09.30.
최종 수정일: 2022.11.03.
이용 프로그램: SAS v9.4
운영체제: Windows 10