*O'Brien;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=OBRIEN(W=0.5);
RUN;
QUIT;
*Brown and Forsythe;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=BF;
RUN;
QUIT;
*Bartlett;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=BARTLETT;
RUN;
QUIT;
PROC GLM DATA=hong.df; : 등분산 검정은 PROC GLM이라는 명령문으로 할 수 있다. PROC GLM을 시행하고, 데이터는 hong 라이브러리에 있는 df를 이용한다. CLASS HTN; : 고혈압 여부(HTN)에 따라 분산이 같은지 검정할 것이다. MODEL SBP = HTN; : 고혈압 여부(HTN)에 따라 수축기 혈압(SBP)의 분산이 같은지 검정할 것이다. MEANS HTN / HOVTEST=OBRIEN(W=0.5); : 고혈압의 평균을 구해주어라. 등분산성 검정 (HOmogeneity of Variance TEST)은 O'Brien방법을 사용한다. O'Brien 방법의 parameter는 W가 있는데 원하는 값을 넣어주면 된다. 기본 값은 0.5로 설정되어 있으며, 기본값 그대로 사용하고자 할 때에는 "(W=0.5)"를 통째로 쓰지 않아도 괜찮다. RUN; : 코드를 실행한다. QUIT; : GLM코드는 QUIT구문을 실행하거나, 다른 코드를 실행해야만 끝나므로 QUIT을 실행한다.
Brown and Forsythe, Bartlett 방법은 각각 "OBRIEN"을 "BF", "BARTLETT"으로 바꾸어 구한 것이다.
결과
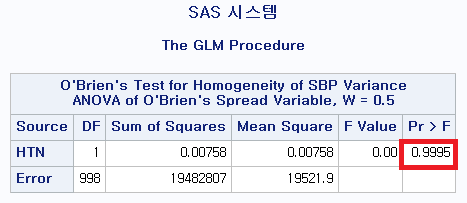
1) O'Brien 검정 결과
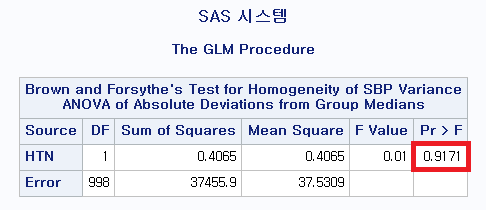
2) Brown and Forsythe 검정 결과
3) Bartlett 검정 결과
약간의 차이들은 있지만 모두 p-value가 0.05 이상으로 귀무가설을 기각하지 못해 모분산이 서로 같다고 결론 내릴 수 있다.
코드 정리
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*데이터 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
*O'Brien;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=OBRIEN(W=0.5);
RUN;
QUIT;
*Brown and Forsythe;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=BF;
RUN;
QUIT;
*Bartlett;
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=BARTLETT;
RUN;
QUIT;
[SAS] 독립 표본 T검정 (Independent samples T-test) - PROC TTEST
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
CLASS HTN;
VAR SBP;
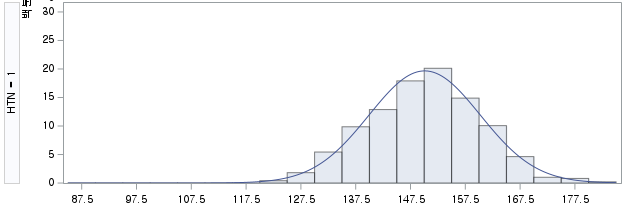
HISTOGRAM SBP/ NORMAL (MU=EST SIGMA=EST);
RUN;
PROC UNIVARIATE : 변수에 대해 알아보는 코드를 작성하겠다.
DATA=hong.df : 데이터는 hong이라는 라이브러리 내에 있는 df를 사용하겠다.
NORMAL : 정규성 검정을 시행해라.
PLOT : 히스토그램과 QQ plot을 그려라
CLASS HTN : VAR SBP : 분석할 변수는 SBP다 HISTOGRAM SBP : SBP의 히스토그램도 그려라
/ NORMAL (MU=EST SIGMA=EST) : 히스토그램에 정규분포 곡선도 덧붙여 그리는데, 정규분포 곡선의 평균은 SBP 데이터로부터 계산한 평균이고, 표준편차도 SBP 데이터의 표준편차다.
정규성 검정 - 결과
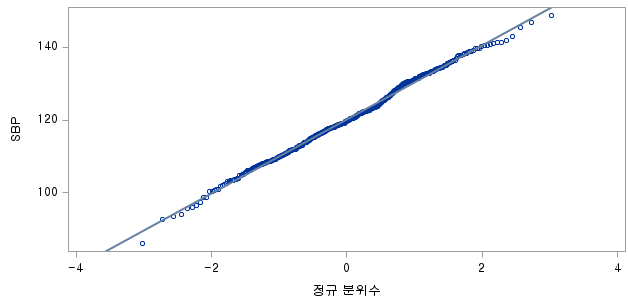
1) HTN=0 (고혈압을 앓지 않는 정상인 군)
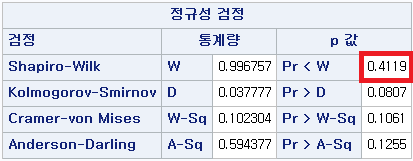
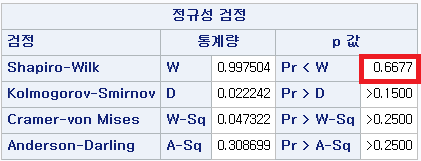
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다.
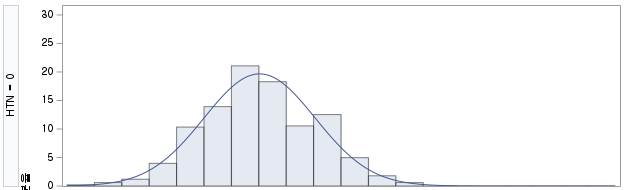
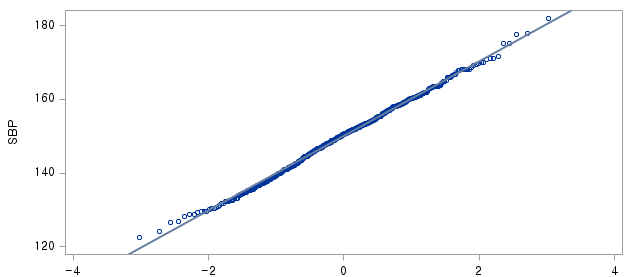
1) HTN=1 (고혈압을 앓는 환자군)
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다.
전제조건이 성립한다. 즉, 고혈압 유병 여부에 따른 수축기 혈압 (SBP)의 분포가 정규성을 따른다고 할 수 있다. 따라서 독립 표본 T 검정 (Independent samples T test, Two samples T test)을 시행할 수 있다.
T-Test 코드
PROC TTEST DATA=hong.df;
CLASS HTN;
VAR SBP;
RUN;
PROC TTEST DATA=hong.df; : T-test를 시행하겠다. 데이터는 hong 라이브러리의 df데이터를 이용한다. CLASS HTN; : 고혈압 여부에 따라 평균의 차이를 검정하겠다. VAR SBP; : 검정하고자 하는변수는 수축기 혈압 (SBP)이다.
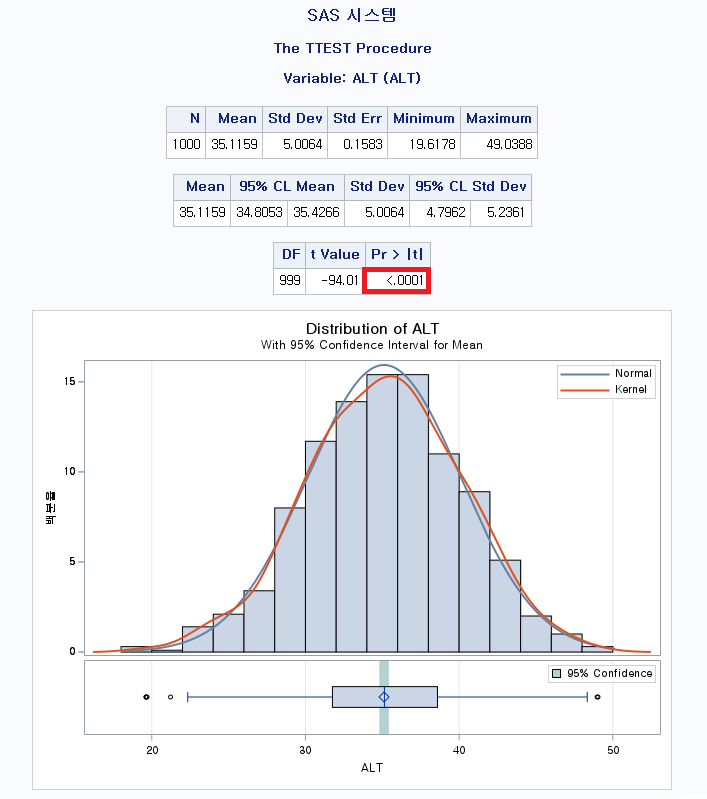
결과
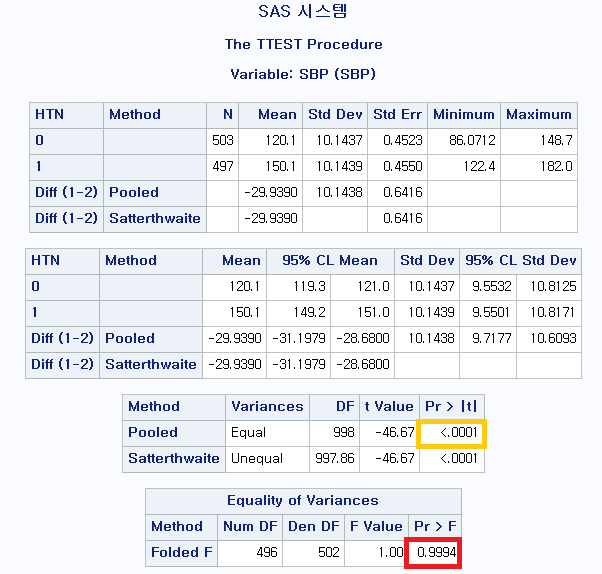
독립 표본 T 검정(Independent samples T-test, Two samples T-test)의 검정 결과는 두 단계에 걸쳐 확인해야 한다.
1) 등분산성 검정
등분산성 (Equality of Variances)을 확인해야 한다. 즉 두 분포의 분산이 같다고 할 수 있는지 확인해야 한다. 빨간색 박스의 p-value는 0.9994이다. 그러면 귀무가설을 기각할 수 없다. 그러면 귀무가설은 무엇이었는가?
귀무가설: $H_0=$ 두 집단의 모분산은 동일하다.
대립가설: $H_1=$ 두 집단의 모분산은 동일하지 않다.
귀무가설을 기각할 수 없으므로 모분산은 같다고 생각하기로 한다.
2) 평균 차이 검정
PROC TTEST는 평균 차이 검정 결과를 두 가지 제공한다. 분산이 같다고 할 수 있을 때 사용하는 Pooled method, 분산이 다르다고 할 수 있을 때 사용하는 Satterthwaite method이다. 위에서 모분산이 같다고 생각하기로 했으므로 Poold method의 p-value를 보면 <0.0001으로 귀무가설을 기각할 수 있다. 그러면 귀무가설은 무엇이었는가?
귀무가설: $H_0=$ 두 집단의 평균 SBP는 동일하다.
대립가설: $H_1=$ 두 집단의 평균 SBP는 동일하지 않다.
고혈압이 있는 군의 평균 SBP는 150.1, 고혈압이 없는 군의 평균 SBP는 120.1이었으므로 고혈압이 있는 환자의 수축기 혈압이 정상군에 비해 유의미하게 높다고 결론지을 수 있다.
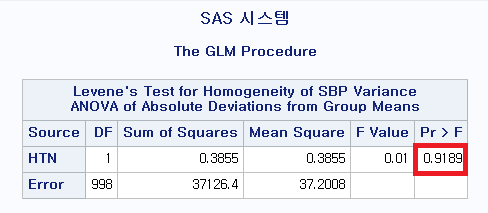
바로, 등분산성 검정 결과가 다르다. SAS에서는 "Fooled F"를 사용하고, SPSS에서는 "Levene의 등분산 검정"을 사용하기 때문이다. 다행히도 SPSS에서도, SAS에서도 모분산이 동일하다는 결론이 났지만, 간혹 서로 다른 결론을 내리기도 한다. 따라서 어떤 등분산성 검정 방법을 사용했는지 알고 있어야 한다.
당연히, SAS에서도 SPSS처럼 Levene의 등분산 검정을 시행할 수 있는데 코드는 다음과 같다.
코드 - Levene의 등분산 검정
PROC GLM DATA=hong.df;
CLASS HTN;
MODEL SBP = HTN;
MEANS HTN / HOVTEST=LEVENE(TYPE=ABS);
RUN;
QUIT;
PROC GLM DATA=hong.df; : Levene의 등분산 검정은 PROC GLM이라는 명령문으로 할 수 있다. PROC GLM을 시행하고, 데이터는 hong 라이브러리에 있는 df를 이용한다. CLASS HTN; : 고혈압 여부(HTN)에 따라 분산이 같은지 검정할 것이다. MODEL SBP = HTN; : 고혈압 여부(HTN)에 따라 수축기 혈압(SBP)의 분산이 같은지 검정할 것이다. MEANS HTN / HOVTEST=LEVENE(TYPE=ABS); : 고혈압의 평균을 구해주어라. 등분산성 검정 (HOmogeneity of Variance TEST)은 Levene방법을 사용 한다. Levene의 등분산 검정은 제곱한 값을 사용하는 SQUARE, 차이를 사용하는 ABS가 있는데 차이를 사용한다. RUN; : 코드를 실행한다. QUIT; : GLM코드는 QUIT구문을 실행하거나, 다른 코드를 실행해야만 끝나므로 QUIT을 실행한다.
이 방법 이외의 등분산성 검정 방법 (O'Brien, Brwon and Forsythe, Bartlett)에 대한 내용은 다음 링크에서 확인할 수 있다.
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
VAR ALT;
HISTOGRAM ALT/ NORMAL (MU=EST SIGMA=EST);
RUN;
정규성 검정 - 결과
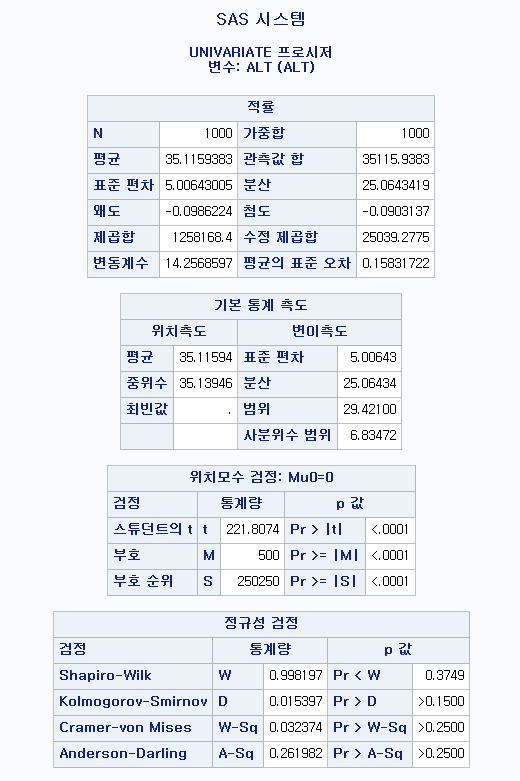
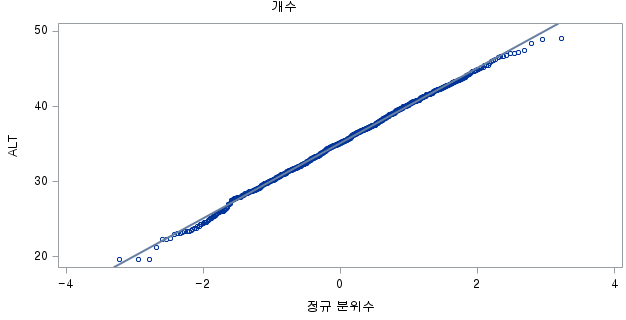
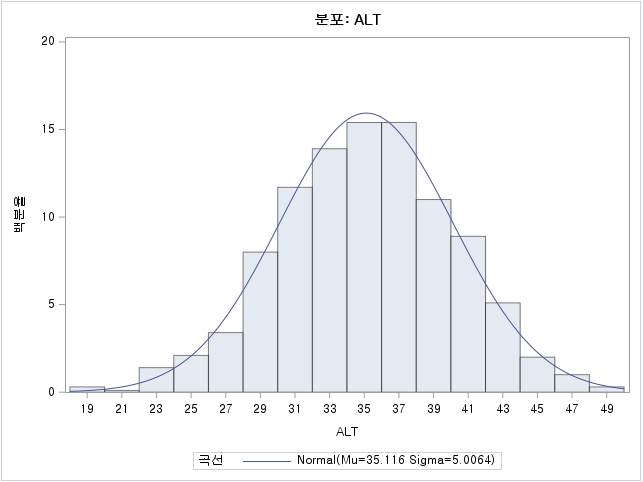
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다. 따라서 ALT로는 일표본 T검정 (One-sample T-test)를 시행할 수 있다.
일표본 T검정 (One sample T test)의 귀무가설과 대립 가설
이번 일표본 T검정 (One sample T test)의 귀무가설은 하나다.
귀무가설: $H_0=$ 모집단의 ALT 평균은 50이다.
하지만 대립 가설은 3개가 된다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
3) $H_1=$ 모집단의 평균은 50보다 크거나 작다. (양측 검정)
대립 가설 별로 코드를 보고자 한다.
1) $H_1=$ 모집단의 평균은 50보다 크다. (단측 검정)
PROC TTEST DATA=hong.df SIDES=U H0=50;
VAR ALT;
RUN;
PROC TTEST DATA=hong.df SIDES=U H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 큰 쪽이며, 검정하고자 하는 모집단의 평균은 50이다. VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
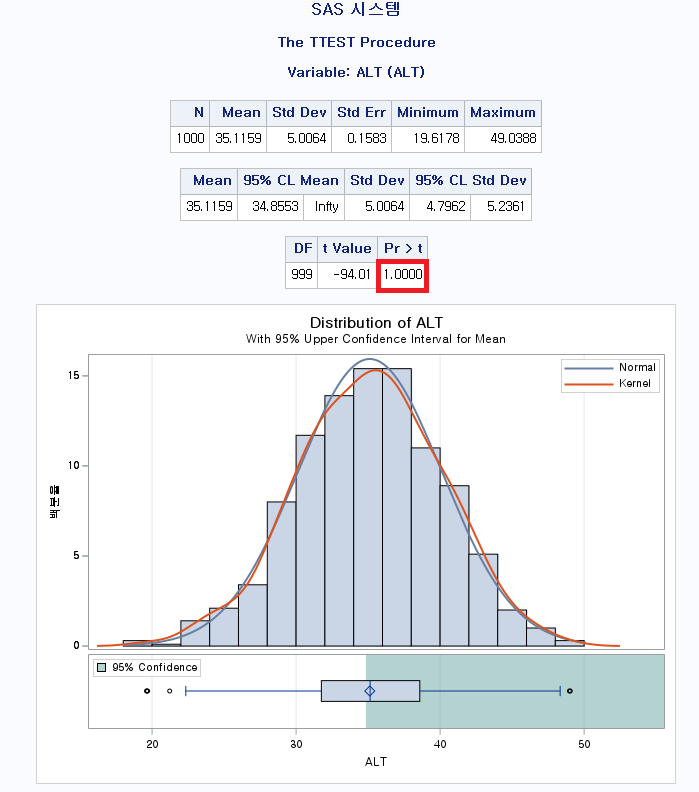
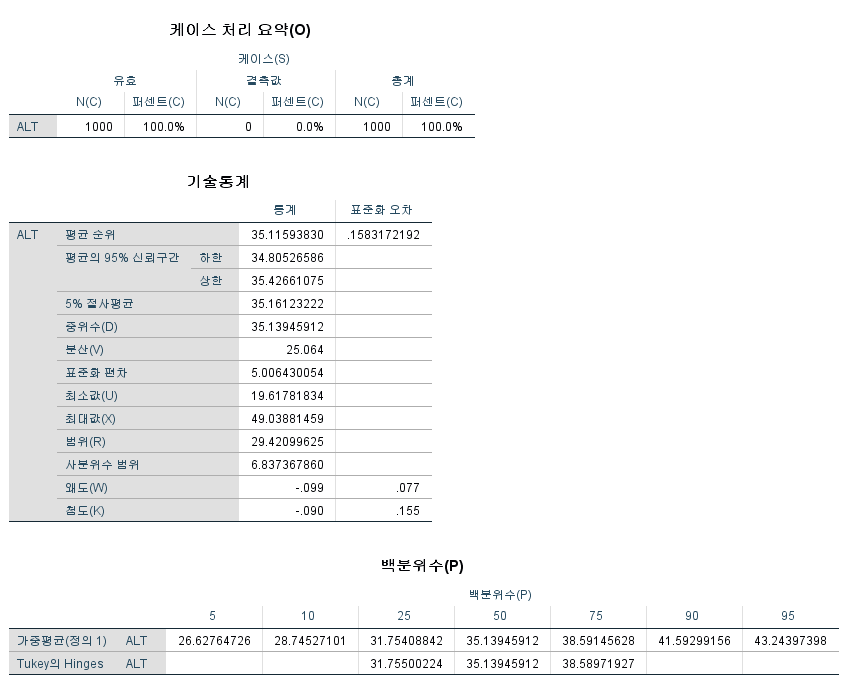
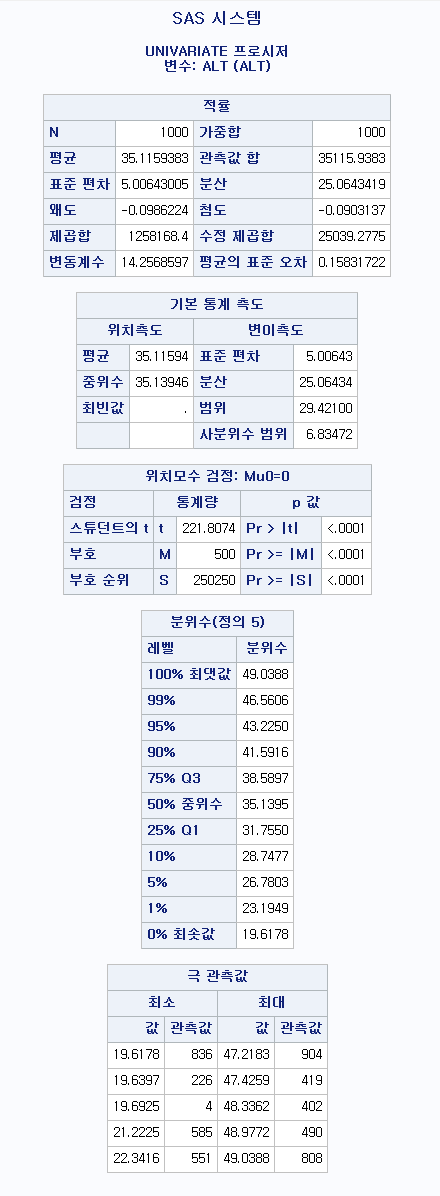
P-value는 1.0000이다. 즉, 대립 가설을 선택하는 것이 말이 안 된다는 것이다. 평균이 50보다 크다고 보는 것보다는 50이라고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
2) $H_1=$ 모집단의 평균은 50보다 작다. (단측 검정)
PROC TTEST DATA=hong.df SIDES=L H0=50;
VAR ALT;
RUN;
PROC TTEST DATA=hong.df SIDES=L H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 작은 쪽이며, 검정하고자 하는 모집단의 평균은 50이다. VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
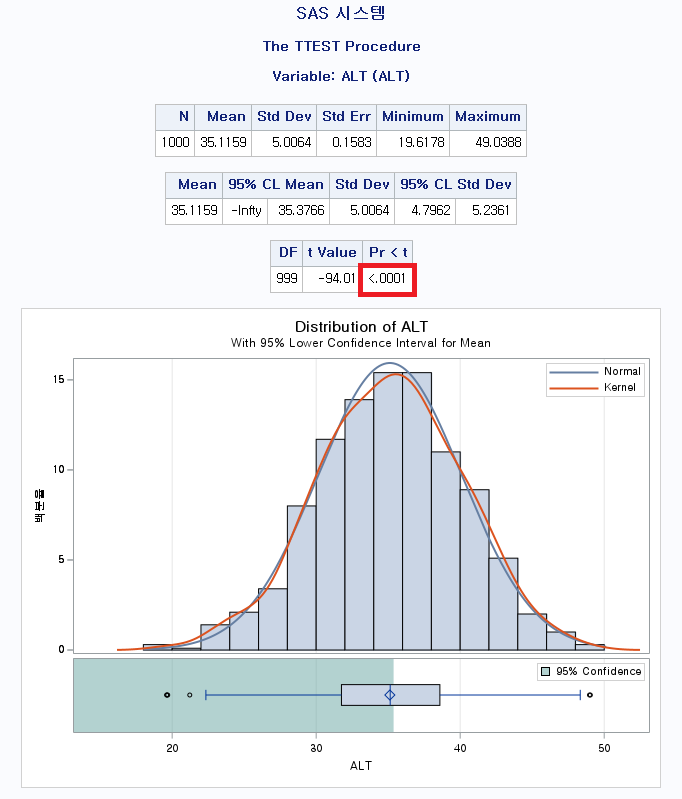
P-value는 <0.0001이다. 즉, 대립 가설을 선택하는 것이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
3) $H_1=$ 모집단의 평균은 50보다 작거나 크다. (양측 검정)
가장 많이 사용하는 양측 검정이다.
PROC TTEST DATA=hong.df SIDES=2 H0=50;
VAR ALT;
RUN;
PROC TTEST DATA=hong.df H0=50;
VAR ALT;
RUN;
위 두 개의 코드는 같은 결과를 내준다. 왜냐하면 양측 검정 (SIDES=2)가 기본 값이어서 SIDES옵션을 지정해주지 않으면 SIDES=2라고 인식하고 코드가 돌아가기 때문이다.
PROC TTEST DATA=hong.df SIDES=2 H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 양쪽이며, 검정하고자 하는 모집단의 평균은 50이다. VAR ALT; : 검정하고자 하는 변수는 ALT다.
PROC TTEST DATA=hong.df H0=50; : T-TEST를 실행할 것이다. 데이터는 hong 라이브러리에 있는 df를 사용할 것이고, 대립 가설은 양쪽이며, 검정하고자 하는 모집단의 평균은 50이다. VAR ALT; : 검정하고자 하는 변수는 ALT다.
결과
P-value는 <0.0001이다. 즉, 대립 가설을 선택하는 것이 합리적이라는 말이다. 평균이 50이라고 보는 것보다는 50보다 작거나 크다고 보는 것이 더 합리적이라는 뜻이다. 실제로 평균은 35.1159라고 적혀있으므로 합당한 통계분석임을 알 수 있다.
주로 양측 검정이 이용되나, 사실 일표본 T검정은 거의 시행되지 않고 다음 글로 나올 독립 표본 T검정이 더 많이 사용된다.
코드 정리
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
*정규성 검정;
PROC UNIVARIATE DATA=hong.df NORMAL PLOT;
VAR ALT;
HISTOGRAM ALT/ NORMAL (MU=EST SIGMA=EST);
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 크다. (단측검정)
PROC TTEST DATA=hong.df SIDES=U H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작다. (단측검정)
PROC TTEST DATA=hong.df SIDES=L H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작거나 크다. (양측검정)
PROC TTEST DATA=hong.df SIDES=2 H0=50;
VAR ALT;
RUN;
*일표본 T검정 - 모집단의 평균은 50보다 작거나 크다. (양측검정)
PROC TTEST DATA=hong.df H0=50;
VAR ALT;
RUN;
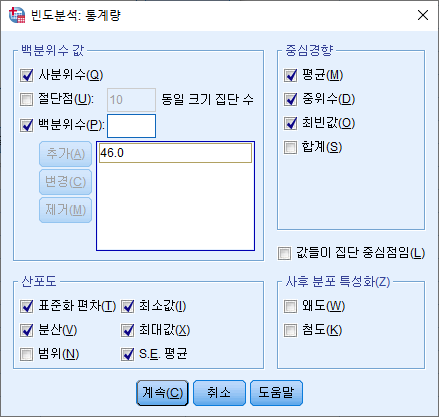
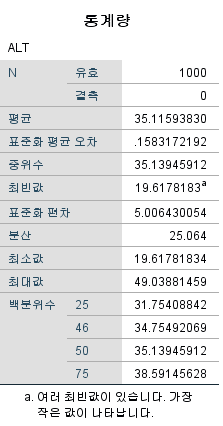
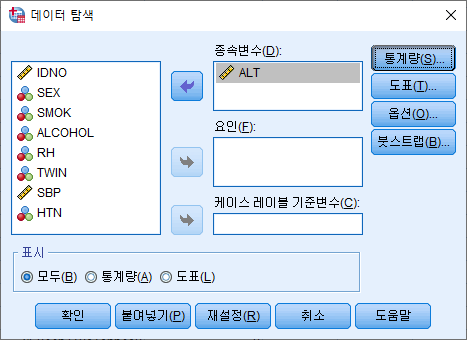
[SPSS] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등)
1,000명으로 어떤 연구를 했다고 하자. 그들의 키, 몸무게 등 지표들은 서로 다를 것이다. 논문의 저자가 이 모든 것을 독자들에게 보여주고자 한다면 행이 1,000인 표를 제시해야 할 것이다. 그렇게 큰 표를 실어줄 저널이 없기도 하거니와, 독자들이 보기에도 한눈에 들어오지 않는다. 그 대신 키의 '평균', 몸무게의 '평균'을 제시하면 한눈에 들어오니 보기가 좋다. 연속 변수는 평균, 표준편차 등으로 요약을 하여 보여주고, 범주형 자료 (흡연 여부, 음주 여부 등)는 도수분포표 혹은 분할표로 제시하게 된다. 분할표를 작성하는 방법은 다음 링크에서 확인할 수 있다.
정규성을 따르지 않는다면 평균과 표준편차를 안다고 해도 전체 분포를 알아낼 수는 없다. 따라서 분포에 대한 직접적인 정보를 주는데, 예를 들어 '하위 25%에 위치하는 사람의 ALT값은 얼마인가?' 등을 제시하는 것이다. 그런 지표로는 중위수, 최댓값, 최솟값, 분 위수, 사분위 범위 등이 있다.
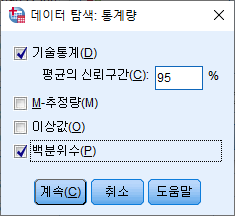
이번 포스팅에서는 이 모든 지표들 (평균, 표준편차, 표준오차, 중위수, 최댓값, 최솟값, 분위수, 사분위 범위 등)을 구하는 법에 대해 소개할 것이다.
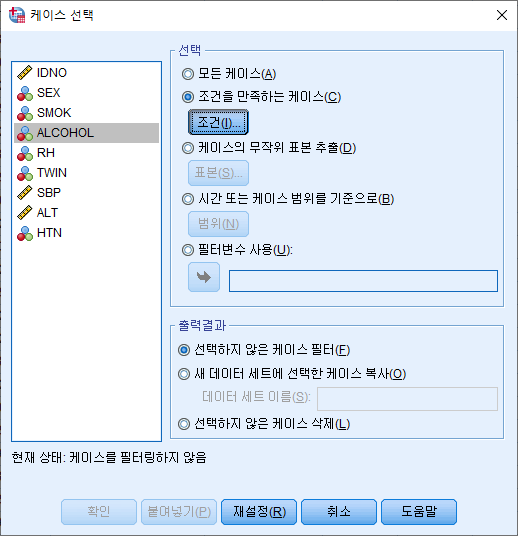
연구를 하다 보면 특정 조건에 맞는 사람들(데이터, 케이스)만을 대상으로 분석하고 싶어질 때가 있다. 즉 하위그룹(subgroup)을 만들어 분석을 하거나, 층화(stratification) 분석을 하고 싶을 때가 있다. 예를 들어, 남성만을 대상으로 하거나, 음주자만을 대상으로 하는 경우가 그렇다. 이렇듯 조건에 맞는 행, 데이터만 추출하는 법에 대해 알아보고자 한다.
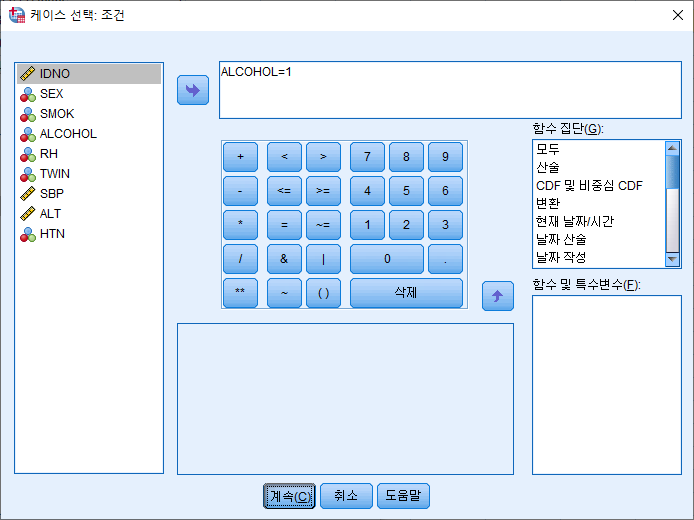
3) 조건을 입력하면 된다. 여기에서는 음주자만 추출해보고자 한다. 음주자는 ALCOHOL 변수가 1로 코딩되어 있으므로 ALCOHOL=1이라고 적는다. "계속(C)"를 누른다.
4) "확인" 버튼을 누른다.
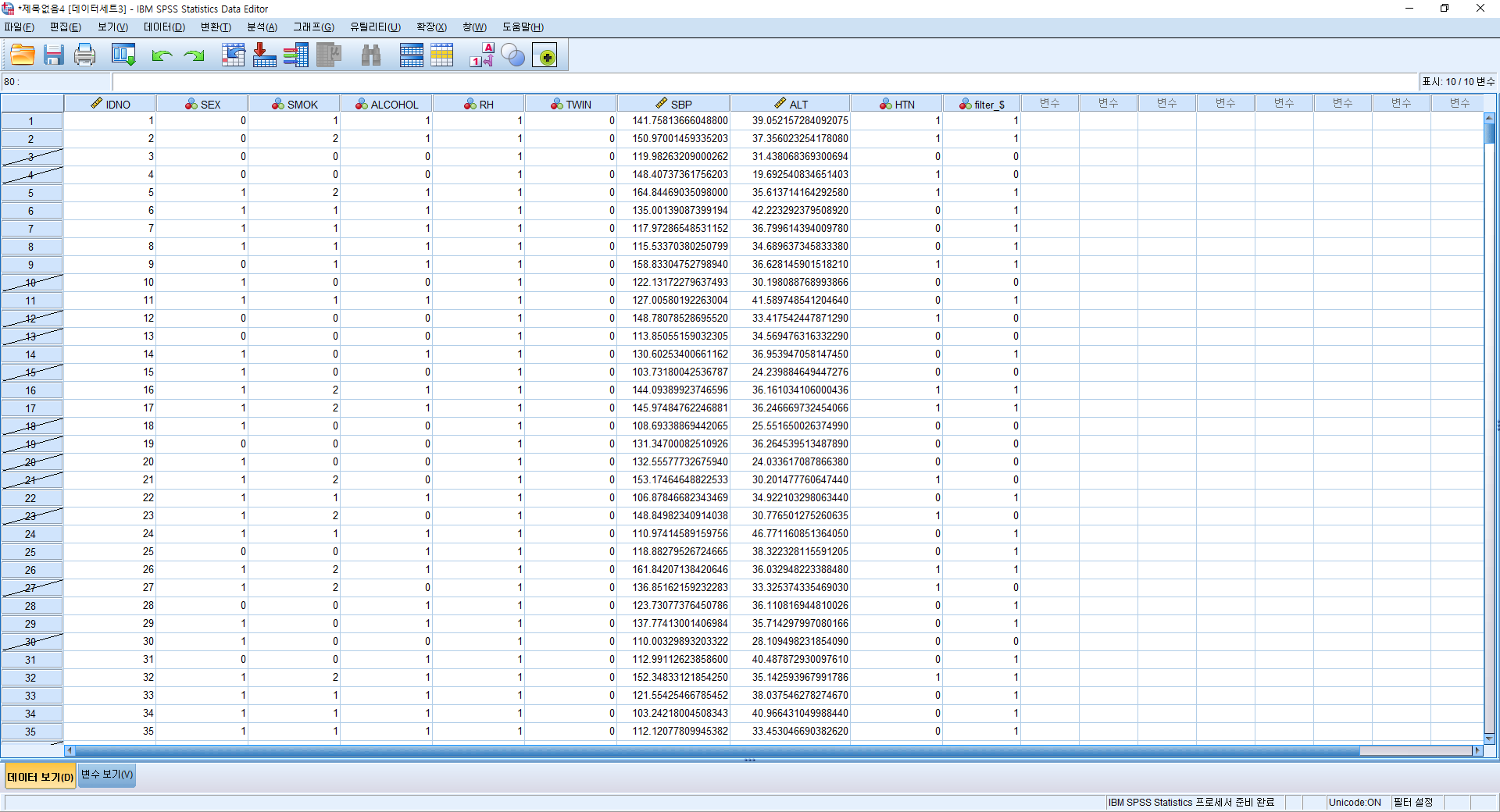
결과
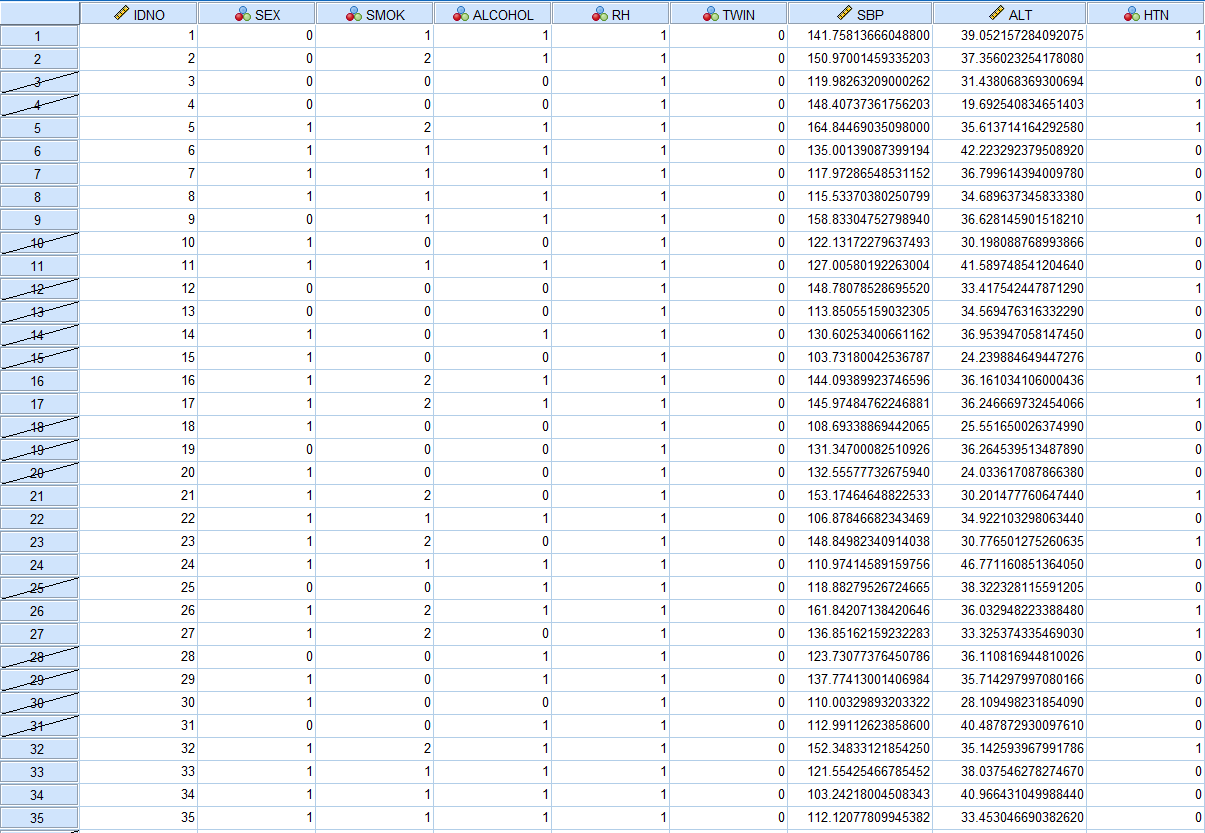
위에서 볼 수 있듯이 ALCOHOL=0인 사람들은 사선 처리되어있는 것을 알 수 있다. 이 상태에서 다른 분석 (평균, 빈도, 회귀분석 등)을 시행하면 사선 처리가 되어있는 비음주자는 분석에 이용되지 않는다.
다중 조건 (AND)
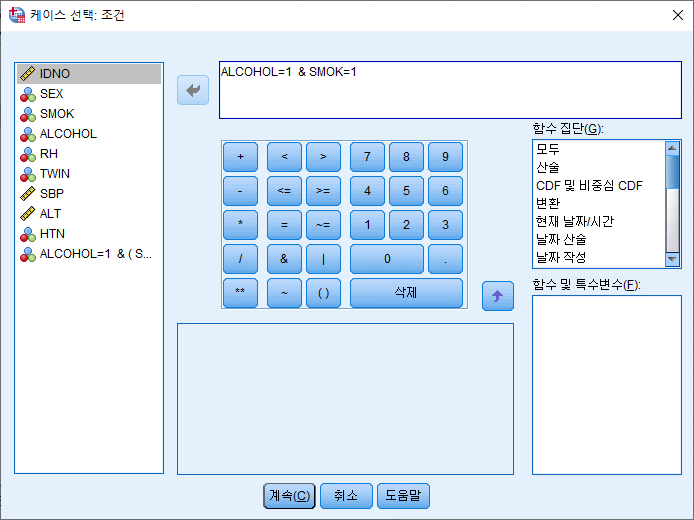
조건이 하나가 아닌 여러 개를 걸고 싶을 때가 있다. 예를 들어 음주자 (ALCOHOL=1)이면서 현재 흡연자 (SMOK=2)인 데이터(행)만 추출하고 싶을 때다. 이럴 때에는 "&"연산자를 사용하여 다음과 같이 적으면 된다.
"ALCOHOL=1 & SMOK=1"
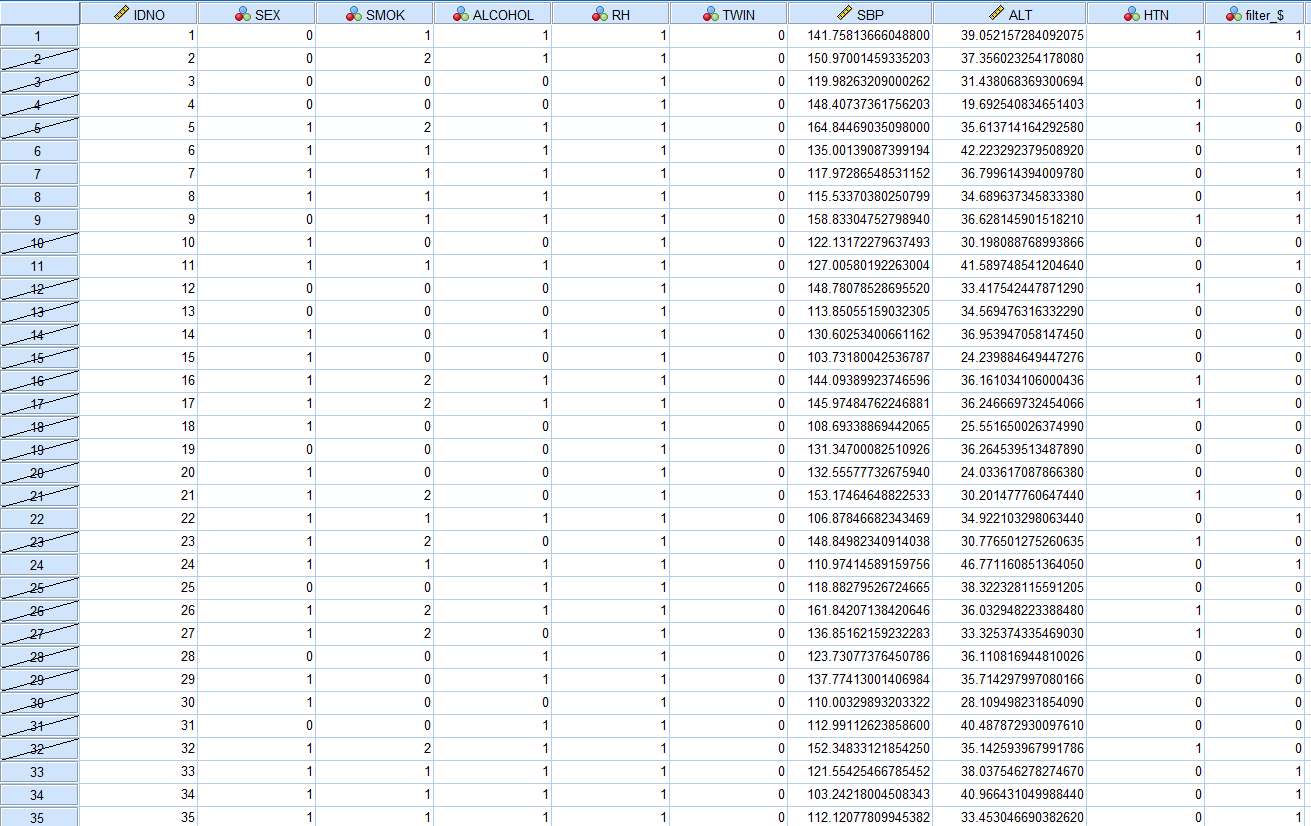
결과
음주자가 아니거나 (ALCOHOL=0) 과거 흡연자(SMOK=1), 비흡연자(SMOK=0)인 경우 모두 사선 처리가 되어있는 것을 확인할 수 있다.
다중 조건 (OR)
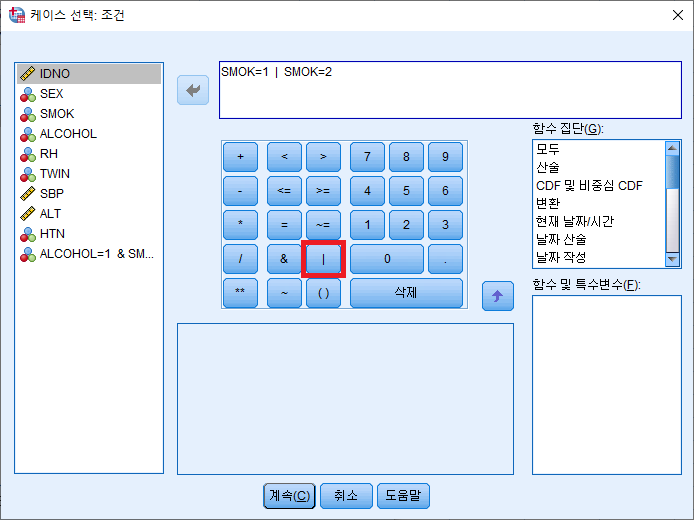
만약 비흡연자를 제외하고 과거 흡연자(SMOK=1)이거나 현재 흡연자(SMOK=2)인 사람만 선택하고 싶다면 어떻게 해야 할까? 위와 같이 &를 사용할 수는 없다. 왜냐하면 SMOK=1이면서 SMOK=2일 수는 없기 때문이다. 이럴 때에는 OR에 해당하는 "|" 연산자를 사용해야 한다.
"|"연산자는 직접 써도 되고, 익숙하지 않은 사람을 위해서 SPSS에서는 빨간 상자 안에 버튼을 만들어 놓았다.
결과
SMOK=0인 사람만 사선 처리되어있는 것을 알 수 있다.
다중 조건 (AND, OR)
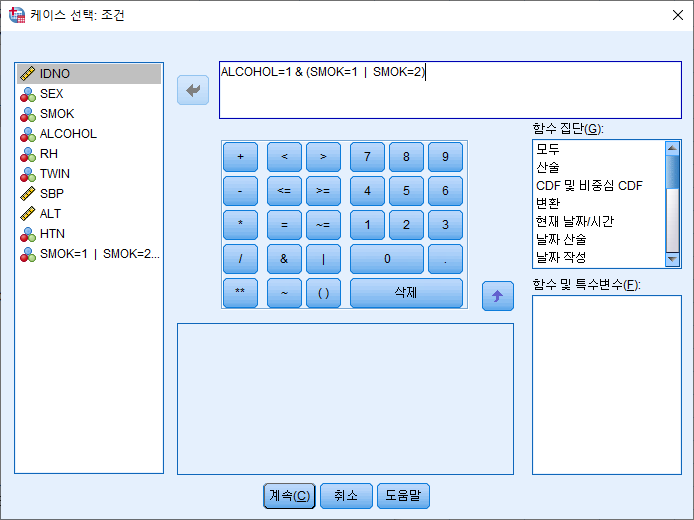
만약, 음주자이면서 비흡연자가 아닌 (현재 흡연자 혹은 과거 흡연자)인 사람을 선택하려면 어떻게 해야 할까?
ALCOHOL=1 & (SMOK=1 | SMOK=2)
AND연산자는 OR에 우선하기 때문에 반드시 괄호 처리를 해주어야 한다. 수학에서 $\times$가 $+$보다 우선하기 때문에 필요한 경우 괄호를 씌우는 것과 동일하다.
1,000명으로 어떤 연구를 했다고 하자. 그들의 키, 몸무게 등 지표들은 서로 다를 것이다. 논문의 저자가 이 모든 것을 독자들에게 보여주고자 한다면 행이 1,000인 표를 제시해야 할 것이다. 그렇게 큰 표를 실어줄 저널이 없기도 하거니와, 독자들이 보기에도 한눈에 들어오지 않는다. 그 대신 키의 '평균', 몸무게의 '평균'을 제시하면 한눈에 들어오니 보기가 좋다. 연속 변수는 평균, 표준편차 등으로 요약을 하여 보여주고, 범주형 자료 (흡연 여부, 음주 여부 등)는 도수분포표 혹은 분할표로 제시하게 된다. 분할표를 작성하는 방법은 다음 링크에서 확인할 수 있다.
정규성을 따르지 않는다면 평균과 표준편차를 안다고 해도 전체 분포를 알아낼 수는 없다. 따라서 분포에 대한 직접적인 정보를 주는데, 예를 들어 '하위 25%에 위치하는 사람의 ALT값은 얼마인가?' 등을 제시하는 것이다. 그런 지표로는 중위수, 최댓값, 최솟값, 분 위수, 사분위 범위 등이 있다.
이번 포스팅에서는 이 모든 지표들 (평균, 표준편차, 표준오차, 중위수, 최댓값, 최솟값, 분위수, 사분위 범위 등)을 구하는 법에 대해 소개할 것이다.
univariate<-function(x){:입력되는 값이 x인 함수를 만들건데 함수의 내용은 { }안에 들어있으니 살펴봐라. 그리고 함수의 이름은 univariate이다. n<-length(x)-sum(is.na(x)): 분석 대상의 수[n]는 전체 개체의 수[length(x)]에서 결측치의 개수 [sum(is.na(x))]를 뺀 값이다. missing<-sum(is.na(x)): 결측된 것을 TRUE로, 결측되지 않은 것을 FALSE로 반환한다 [is.na(x)]. TRUE인 것을 모두 합친다 [sum(is.na(x))]. 그 값이 결측치의 개수이다. mean<-mean(x): 평균은 mean() 함수를 이용한다. sd<-sd(x): 표준편차는 sd() 함수를 이용한다. var<-var(x): 분산은 var() 함수를 이용한다. se<-sqrt(var/n): 표준오차(se)는 분산(var)을 분석 대상의 수(n)로 나눈 뒤 루트를 씌운 값이다.
min<-min(x): 최솟값은 min() 함수를 이용한다. max<-max(x): 최댓값은 max() 함수를 이용한다. median<-median(x): 중앙값은 median() 함수를 이용한다. mode <- function(x) {: 최빈값은 구하는 함수가 R에 내장되어있지 않으므로 함수를 따로 만들어야 한다. 데이터(x)를 입력받아 최빈값을 구하는 함수를 만들 것이고 그 함수의 이름은 mode이다. nodup <- unique(x): 중복되는 값을 모두 삭제하고 한 개씩만 대표적으로 남긴다. 대표들로 이루어진 벡터를 nodup이라고 하자. if (length(which(tabulate(match(x, nodup))==max(tabulate(match(x, nodup)))))>=2 ) {NA} else{nodup[which.max(tabulate(match(x, nodup)))]}
여기까지의 내용이 복잡하니 하나씩 코드를 살펴보기로 한다.
(1) 큰 구성은 if (A) {B} else {C} 이다. A라는 조건이 만족하면 B를 반환하고, A를 만족하지 않으면 C를 반환한다는 것이다.
(2) match(x, nodup): x가 nodup에서 몇 번째 데이터와 일치하는지를 반환하는 함수다.
Example) 예를 들어 x가 (1,5,2,3,3,4,2)라고 하자.
nodup은 중복되는 값을 삭제했을 터이니 (1,5,2,3,4)일 것이다.
그렇다면 match(x,nodup)은 (1,2,3,4,4,5,3)이 된다.
(3) tabulate(match(x,nodup)): tabulate는 각 정수가 나타난 횟수를 세준다. (1,2,3,4,4,5,3)에서 1은 1개, 2는 1개, 3은 2개, 4는 2개, 5는 1개다. 따라서 tabulate(match(x,nodup))은 (1,1,2,2,1)이 된다.
최빈값은 가장 흔한 단 한 개의 값이어야 하는데, 여기에서 3과 4는 2개, 나머지는 1개이므로 이 데이터의 최빈값은 없다. 즉, tabulate(match(x,nodup))인 (1,1,2,2,1)의 최댓값(2)이 tabulate(match(x,nodup))인 (1,1,2,2,1)에 2개 이상 존재한다면 최빈값이 없다고 반환해야 한다.
(5) which(tabulate(match(x, nodup))==max(tabulate(match(x, nodup))))는 TRUE인 위치를 반환하므로 (3,4)를 보여준다.
(6) length(which(tabulate(match(x, nodup))==max(tabulate(match(x, nodup)))))는 (3,4)에 있는 숫자의 개수, 즉 2를 반환한다.
이렇게 함으로써 최빈값'같은' 값이 2개 이상 존재할 때 NA를 반환하도록 하였다.
그렇지 않을 때 (즉, 단 한 개의 최빈값이 존재할 때)는 다음과 같은 로직에 의해 구해진다고 생각하면 된다.
Example) x가 (1,5,2,2,3)이라고 하자.
nodup은 (1,5,2,3)이 된다.
match(x,nodup)은 (1,2,3,3,4)이 된다.
tabulate(match(x,nodup))는 (1,1,2,1)이 된다. 여기에서 횟수가 가장 많아 '2'라고 표현된 값의 근원을 찾아가야 한다.
which.max(tabulate(match(x, nodup)))는 (1,1,2,1)에서 최댓값이 존재하는 위치를 반환하므로 3이 된다.
(1,1,2,1)의 2는 match(x,nodup)인 (1,2,3,3,4)에서 온 것이다. 1이 1개, 2가 1개, 3이 2개, 4가 1개. 즉, tabulate는 개수를 세어주므로 중복된 값을 빼는 효과가 있다. 즉 2가 3번째에 위치한 이유는 nodup (1,5,2,3)의 2가 nodup에서 3번째에 위치해있기 때문이다. 따라서 nodup의 3번째 값을 반환해야 최빈값을 구할 수 있다. 그러므로 nodup[which.max(tabulate(match(x, nodup)))]이라는 코드를 쓰게 된다.
} mode<-mode(x)
lclm<-mean-qt(0.975, n-1)*se
uclm<-mean+qt(0.975, n-1)*se
P25<-data.frame(quantile(x)[2])[1,1]
P50<-data.frame(quantile(x)[3])[1,1]
P75<-data.frame(quantile(x)[4])[1,1]
qrange<-data.frame(quantile(x)[4])[1,1]-data.frame(quantile(x)[2])[1,1]
name<-c("N", "N of missing","Mean", "Standard Deviation", "Variation", "Standard Error", "Minimum",
"Maximum", "Median", "Mode", "95% Lower limit of mean (two-sided)", "95% Upper limit of mean(two-sided)", "P25", "P50", "P75", "Quantile Range")
value<-c(n, missing, mean, sd, var, se, min, max, median, mode, lclm, uclm, P25, P50, P75, qrange)
result<-cbind(name, value)
print(result)
}
lclm<-mean-qt(0.975, n-1)*se: t 분포에서 자유도(n-1)에 걸맞게 2.5%에 해당하는 값을 찾고, 표준오차를 곱하여 평균에서 빼면 95% 신뢰구간의 하한이 구해진다. uclm<-mean+qt(0.975, n-1)*se: t 분포에서 자유도(n-1)에 걸맞게 2.5%에 해당하는 값을 찾고, 표준오차를 곱하여 평균에서 더하면 95% 신뢰구간의 상한이 구해진다. P25<-data.frame(quantile(x)[2])[1,1]: quantile() 함수의 2번째 값은 1사분위수를 의미한다. 데이터프레임으로 바꾸고 값만을 취한다. P50<-data.frame(quantile(x)[3])[1,1]: quantile() 함수의 2번째 값은 2사분위수를 의미한다. 데이터프레임으로 바꾸고 값만을 취한다. P75<-data.frame(quantile(x)[4])[1,1]: quantile() 함수의 2번째 값은 3사분위수를 의미한다. 데이터프레임으로 바꾸고 값만을 취한다. qrange<-data.frame(quantile(x)[4])[1,1]-data.frame(quantile(x)[2])[1,1]: 3사분위수에서 1사분위수를 빼어 값을 구한다. name<-c("N", "N of missing","Mean", "Standard Deviation", "Variation", "Standard Error", "Minimum", "Maximum", "Median", "Mode", "95% Lower limit of mean (two-sided)", "95% Upper limit of mean(two-sided)", "P25", "P50", "P75", "Quantile Range"): 각 값의 이름을 지정하여 name이라는 벡터에 저장한다. value<-c(n, missing, mean, sd, var, se, min, max, median, mode, lclm, uclm, P25, P50, P75, qrange): 위에서 구한 값들로 벡터를 만들고 value라는 이름을 붙인다. result<-cbind(name, value): name과 value를 열 별로 합치고 result에 저장한다. print(result): result를 출력한다. }
만약 25%, 50%, 75%가 아닌 임의의 n% 백분위수를 구하고 싶다면 Pn을 사용하면 된다.
64%백분위수를 보고싶다면 P64를 사용하면 된다.
사분위수는 SAS, SPSS, R의 결과가 서로 다를 수 있다. 왜냐하면 각 프로그램에서 사분위수를 구하는 방법이 다를 수 있기 때문이다. 각 프로그램에는 사분위수를 구하는 여러가지 방법이 내장되어 있으며, 골라서 사용할 수도 있다.
[SAS] 기술 통계 (평균, 표준편차, 표준오차, 최댓값, 최솟값, 중위수, 분위수 등) - PROC UNIVARIATE, PROC MEANS
1,000명으로 어떤 연구를 했다고 하자. 그들의 키, 몸무게 등 지표들은 서로 다를 것이다. 논문의 저자가 이 모든 것을 독자들에게 보여주고자 한다면 행이 1,000인 표를 제시해야 할 것이다. 그렇게 큰 표를 실어줄 저널이 없기도 하거니와, 독자들이 보기에도 한눈에 들어오지 않는다. 그 대신 키의 '평균', 몸무게의 '평균'을 제시하면 한눈에 들어오니 보기가 좋다. 연속 변수는 평균, 표준편차 등으로 요약을 하여 보여주고, 범주형 자료 (흡연 여부, 음주 여부 등)는 도수분포표 혹은 분할표로 제시하게 된다. 분할표를 작성하는 방법은 다음 링크에서 확인할 수 있다. 2022.08.18 - [기술 통계/SAS] - [SAS] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - PROC FREQ
정규성을 따르지 않는다면 평균과 표준편차를 안다고 해도 전체 분포를 알아낼 수는 없다. 따라서 분포에 대한 직접적인 정보를 주는데, 예를 들어 '하위 25%에 위치하는 사람의 ALT값은 얼마인가?' 등을 제시하는 것이다. 그런 지표로는 중위수, 최댓값, 최솟값, 분 위수, 사분위 범위 등이 있다.
이번 포스팅에서는 이 모든 지표들 (평균, 표준편차, 표준오차, 중위수, 최댓값, 최솟값, 분위수, 사분위 범위 등)을 구하는 법에 대해 소개할 것이다.
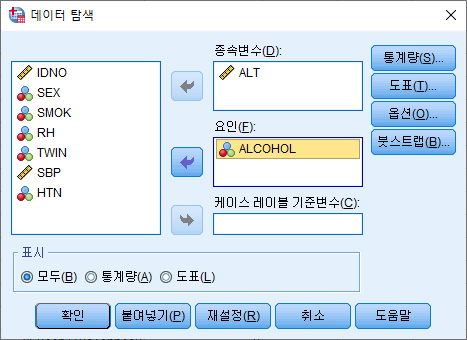
만약, 음주 여부에 따라 기술 통계량을 보고 싶다면 다음과 같이 "CLASS"구문을 추가하면 된다.
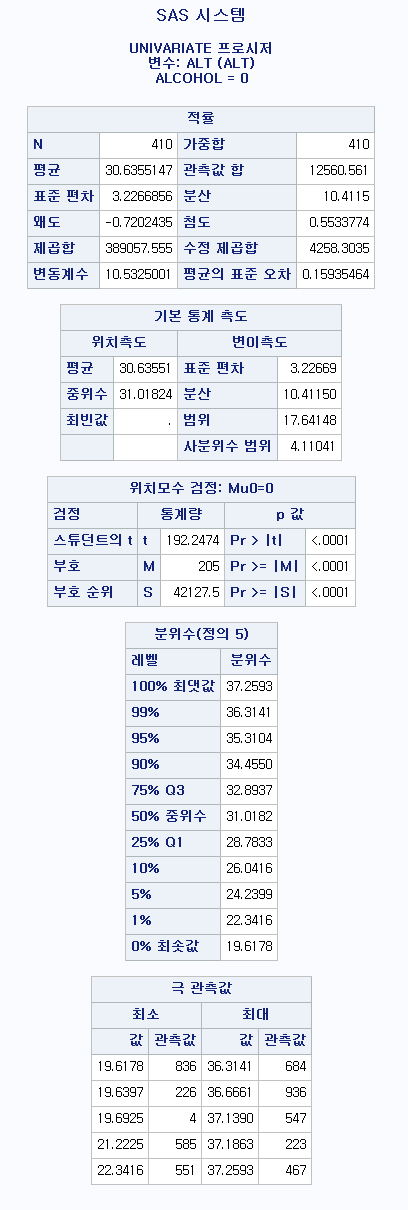
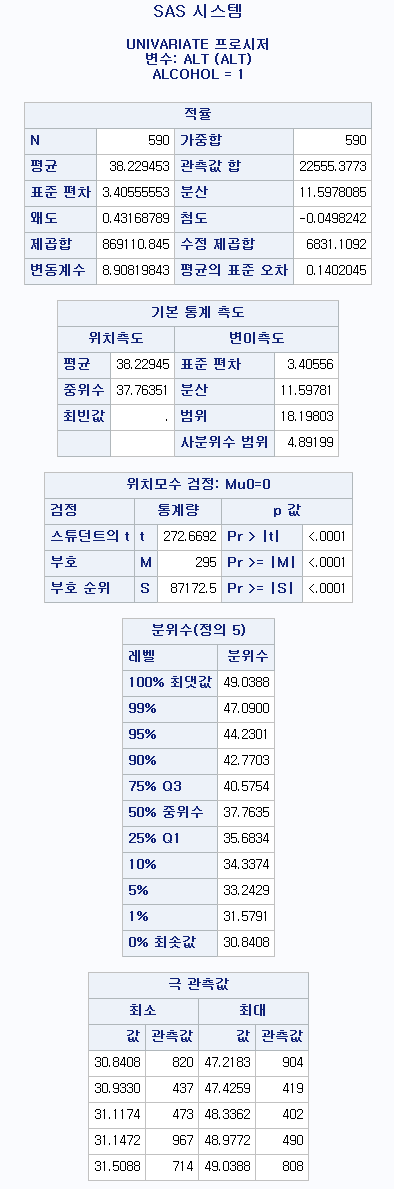
PROC UNIVARIATE DATA=hong.df ;
CLASS ALCOHOL;
VAR ALT ;
PROC UNIVARIATE DATA=hong.df : 기술 통계량을 산출하는 코드를 시작할 것이고, 데이터는 hong 라이브러리에 있는 df를 쓰겠다.
CLASS ALCOHOL : 음주 여부에 따라서 각각 결과를 산출하라 VAR ALT : 변수 "ALT"에 대한 기술 통계량을 보여달라.
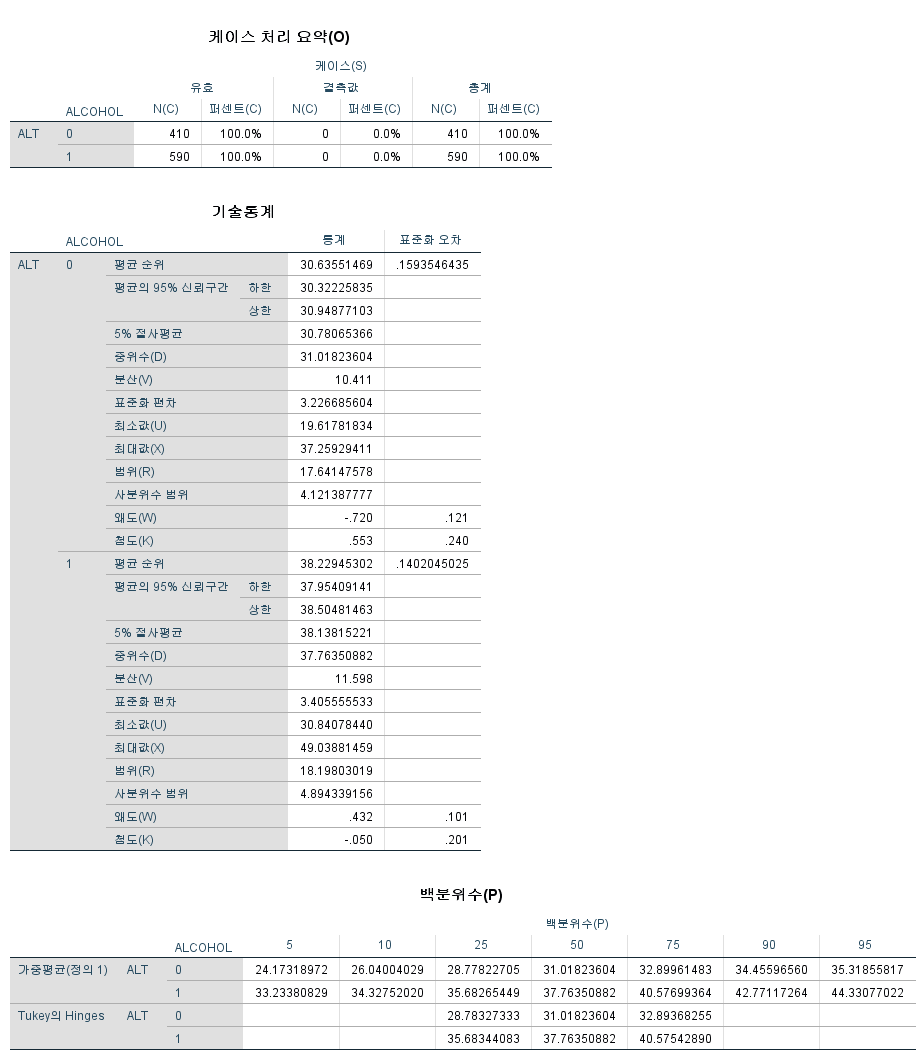
결과
경력자용 (PROC MEANS)
PROC UNIVARIATE은 정말 훌륭한 코드이지만 단점은 출력되는 결괏값이 너무 많다는 것이다. 그중에 필요한 것만 골라서 보고 싶다면 PROC MEANS가 더욱 적절하다. 물론 SAS에 익숙하지 않다면 코드가 복잡하게 느껴질 수도 있다.
기본 코드
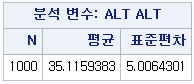
PROC MEANS DATA=hong.df ;
VAR ALT ;
RUN;
PROC MEANS DATA=hong.df : 기술 통계량을 산출하는 코드를 시작할 것이고, 데이터는 hong 라이브러리에 있는 df를 쓰겠다. VAR ALT : 변수 "ALT"에 대한 기술 통계량을 보여달라.
결과
보고 싶은 통계량을 지정해놓지 않으면 표본의 수, 평균, 표준편차, 최솟값, 최댓값을 보여준다.
코드
보고 싶은 통계량이 있다면 데이터 지정 후 모두 다 적어주면 된다.
예를 들어 표본의 수는 N, 평균은 MEAN, 표준편차는 STD인데 이 세 가지를 넣은 코드는 다음과 같다.
PROC MEANS DATA=hong.df N MEAN STD;
VAR ALT ;
RUN;
PROC MEANS DATA=hong.df N MEAN STD : 기술 통계량을 산출하는 코드를 시작할 것이고, 데이터는 hong 라이브러리에 있는 df를 쓰겠다. 통계량은 표본의 수, 평균, 표준편차만 보여달라. VAR ALT : 변수 "ALT"에 대한 기술 통계량을 보여달라.
결과
비교적 자주 쓰는 통계량의 코드는 다음과 같다.
통계량
코드
통계량
코드
표본 수
N
평균의 신뢰구간
CLM
결측 수
NMISS
25백분위수 (1사분위수)
P25 (Q1)
평균
MEAN
75백분위수 (3사분위수)
P75 (Q3)
표준편차
STD
사분위 범위
QRANGE
표준오차
STDERR
1백분위수
P1
최솟값
MIN
5백분위수
P5
최댓값
MAX
n0백분위수
Pn0 (i.e. P10, P20, P30, ...)
중위수
MEDIAN
95백분위수
P95
최빈값
MODE
99백분위수
P99
*CLM은 양측(two-sided) 신뢰구간을 구해준다. 만약 단측 (one-sided)신뢰구간을 구하고자 한다면 신뢰구간의 상한은 UCLM을, 하한은 LCLM을 사용하면 된다.
코드
만약, 음주 여부에 따라 기술 통계량을 보고 싶다면 다음과 같이 "CLASS"구문을 추가하면 된다.
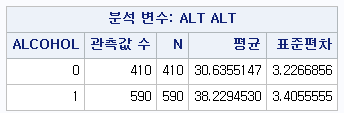
PROC MEANS DATA=hong.df N MEAN STD;
CLASS ALCOHOL;
VAR ALT ;
RUN;
PROC MEANS DATA=hong.df N MEAN STD : 기술 통계량을 산출하는 코드를 시작할 것이고, 데이터는 hong 라이브러리에 있는 df를 쓰겠다. 통계량은 표본의 수, 평균, 표준편차만 보여달라.
CLASS ALCOHOL : 음주 여부에 따라서 각각 결과를 산출하라 VAR ALT : 변수 "ALT"에 대한 기술 통계량을 보여달라.
결과
코드
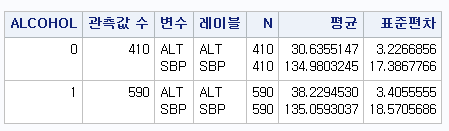
만약, 음주 여부에 따라 ALT와 수축기 혈압을 동시에 보고 싶다면 변수 자리에 수축기 혈압 변수를 같이 쓰면 된다.
PROC MEANS DATA=hong.df N MEAN STD;
CLASS ALCOHOL;
VAR ALT SBP;
RUN;
PROC MEANS DATA=hong.df N MEAN STD : 기술 통계량을 산출하는 코드를 시작할 것이고, 데이터는 hong 라이브러리에 있는 df를 쓰겠다. 통계량은 표본의 수, 평균, 표준편차만 보여달라.
CLASS ALCOHOL : 음주 여부에 따라서 각각 결과를 산출하라 VAR ALT SBP : 변수 "ALT"와 "SBP"에 대한 기술 통계량을 보여달라.
결과
코드 정리
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
*초보자용;
PROC UNIVARIATE DATA=hong.df ;
VAR ALT ;
RUN;
*(초보자용) 음주 여부에 따른 기술 통계량;
PROC UNIVARIATE DATA=hong.df ;
CLASS ALCOHOL;
VAR ALT ;
*경력자용;
PROC MEANS DATA=hong.df ;
VAR ALT ;
RUN;
*(경력자용) 음주 여부에 따른 기술 통계량;
PROC MEANS DATA=hong.df N MEAN STD;
CLASS ALCOHOL;
VAR ALT ;
RUN;