#4) 나누기 df$LIVER_RATIO=df$AST/df$ALT : AST를 ALT로 나누어 그 값을 LIVER_RAIO라는 변수에 저장해라
#5) 거듭제곱 (승) df$SBP_SQ=df$SBP**2 : SPB를 제곱하여 SBP_SQ에 저장해라. 만약 세제곱을 원한다면 "SBP**3"을 사용하면 된다.
#6) 로그 (log) df$LOG_ALT=log(df$ALT) : ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 $e$다. df$LOG10_ALT=log(df$ALT, base=10): ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 10이다. df$LOG7_ALT=log(df$ALT)/log(7): ALT에 로그를 씌워 LOG_ALT에 저장해라. 이때 로그의 밑은 7이다. 원하는 숫자를 밑으로 하고 싶으면 7이 아닌 원하는 숫자를 적으면 된다.
#7) 지수 df$EXP_ALT=exp(df$ALT): $e$의 ALT승($e^{ALT}$)을 EXP_ALT에 저장해라. df$EXP10_ALT=exp(df$ALT*log(10)): 10의 ALT승($10^{ALT}$)을 EXP10_ALT에 저장해라. 만약 10이 아닌 5의 ALT승($5^{ALT}$)를원하면 "log(5)"를 사용하면 된다.
[이론] 로지스틱 회귀분석에서 회귀 계수를 구하는 방법 - Maximum likelihood estimation
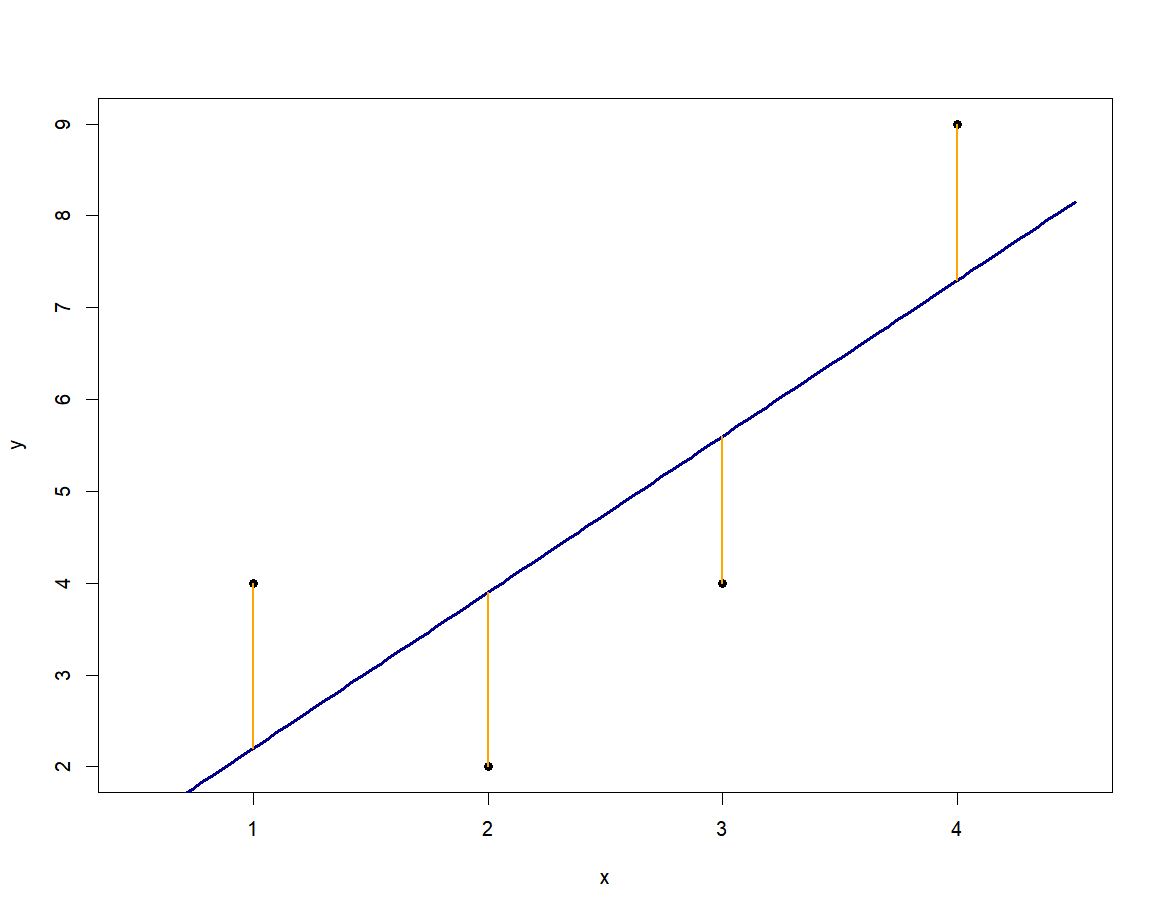
선형 회귀 분석에서 회귀 계수를 구하는 방법은 최소 제곱법으로 비교적 직관적이다. 데이터를 가장 잘 설명할 수 있는 직선을 잘 그리면 되는 것이다. 즉 아래 그림에서 오렌지색 선분 길이 제곱의 합이 최소화되는 직선을 찾는 것이다.
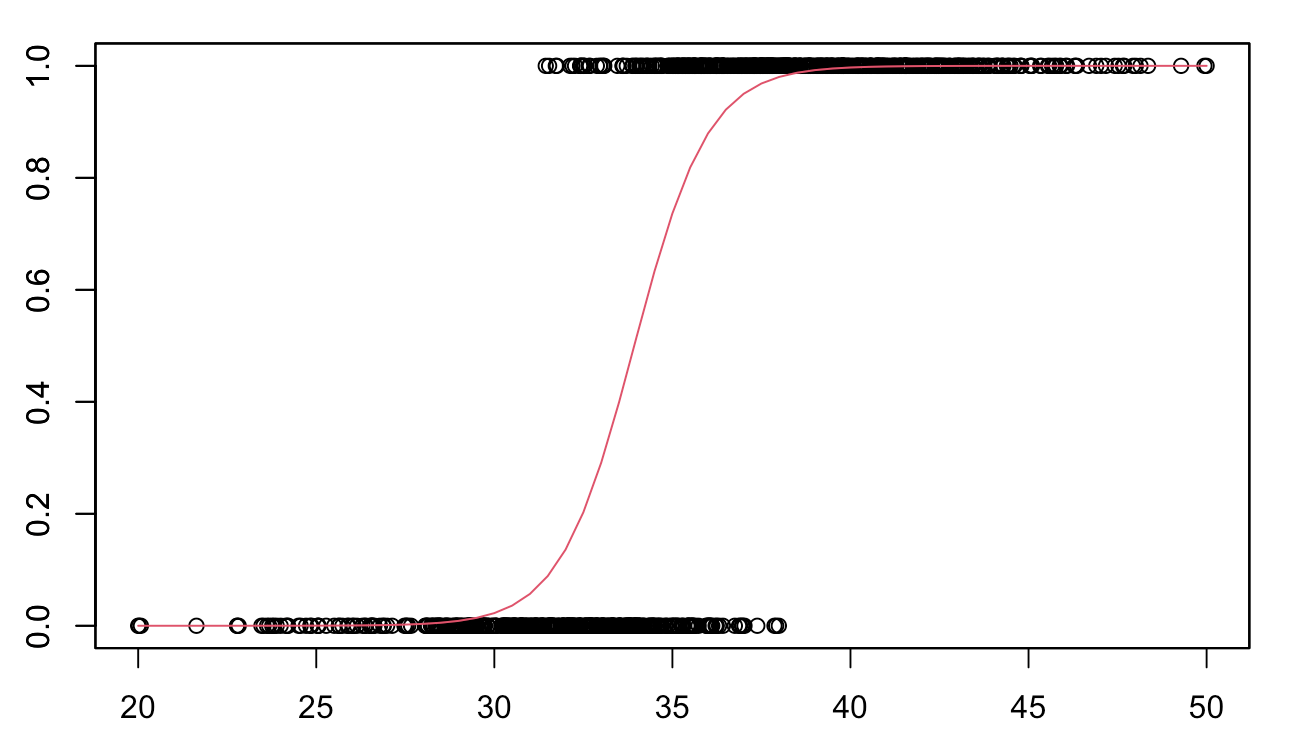
하지만 로지스틱 회귀분석 (logistic regression)에서 회귀 계수를 같은 방법으로 구하는 것은 적절하지 않다. 예를 들어 혈중 ALT에 따른 고혈압 여부에 대한 로지스틱 회귀분석을 실시한다고 하자. 이때 로지스틱 회귀분석에서 결과변수는 이분형 (예시: 고혈압 or 정상)이므로 그래프를 그리면 두 개의 선으로 나타나게 된다. 이런 데이터를 가장 잘 설명하는 하나의 선을 구하는 것은 적절하지 않아 보인다. 따라서 로지스틱 회귀분석에는 maximum likelihood estimation (MLE)라는 방법으로 회귀 계수를 구한다.
1. Maximum likelihood estimation이란 무엇인가?
상황 A: 앞면이 나올 확률이 $p$인 동전을 10회 던졌는데 6회 앞면이 나왔다고 하자.
이런 상황이 발생했을 확률은 다음과 같이 표현할 수 있다.
$$ L=p^6 (1-p)^4$$
이 식은 상황 A가 발생할 확률이자 가능도 (likelihood)를 의미한다. 우리는 상황 A를 표현한 위 식에서 $p$값을 유추하고자 한다. 어떻게 해야 할까? 만약 특정 $p$값일 때 10번 중 6번 앞면이 나올 확률(가능도)이 최대가 된다면 그 $p$값으로 유추하는 것이 적절할 것이다. 따라서 가능도를 최대화시키는 과정이 필요하다. 따라서 $ p^6 (1-p)^4$값이 최대가 되어야 하며, 이는 $\frac {\partial L} {\partial p}=0$이 되는 $p$를 찾는 것과 동일하다. 따라서 $p= \frac {6} {10}$이 도출된다. 이것이 Maximum likelihood estimation이다.
2. 로지스틱 회귀분석의 회귀식
위 내용을 로지스틱 회귀분석에 적용해볼 것이다. 이전에 로지스틱 회귀분석의 회귀식을 먼저 알아야 한다. 회귀식은 다음과 같이 나타난다.
$$log(odds) = \alpha + \sum_i \beta_i x_i$$
그런데, $odds= \frac {p} {1-p}$이므로 위 식은 다음과 같이 변형될 수 있다.
즉 위 식은 어떤 개인에게 이벤트(고혈압 여부)가 존재할 확률을 $\alpha$, $\beta$, $x$로 표현할 수 있음을 의미한다.
3. 단순한 예시
계산을 단순화하기 위해서 위 $p= \frac {1} {1+ e^{-\alpha-\sum_i \beta_i x_i}}$식에서 $n=1$인 상황을 생각해보자. 즉 독립변수는 한 개만 존재한다고 생각한다. 그리고 그 독립변수는 이분형 변수라고 생각하자. 예를 들면 음주 여부 (음주자 vs 비음주자)가 있을 수 있다. $x_1$는 음주 여부를 의미하고, 0은 비음주자, 1은 음주자를 의미한다고 하자.
비음주자: $x_1 = 0$
음주자: $x_1 = 1$
그리고 $p$는 고혈압일 확률을 의미한다고 하자. 그러면 다음과 같은 분할표를 작성할 수 있고, 각각 해당하는 사람의 수는 $a$, $b$, $c$, $d$라고 하자.
고혈압 환자
정상인
음주자 ($x_1 = 1$)
$a$
$b$
비음주자 ($x_1 = 0$)
$c$
$d$
4. 음주 여부에 따른 고혈압일 확률
어떤 누군가가 고혈압일 확률은 $p= \frac {1} {1+ e^{-\alpha- \beta_1 x_1}}$이다. 비음주자는 $x_1 = 0$, 음주자는 $x_1 = 1$이므로 다음을 구할 수 있다.
(연구대상들이 고혈압에 걸리는 사건들은 모두 독립이라는 가정이 필요하다. 동전이 앞면이 나오면서 주사위에 1이 나올 확률을 구할 때 그저 $\frac{1}{2}$에 $\frac{1}{6}$을 곱할 수 있는 이유는 동전을 던지는 것과 주사위를 던지는 것이 서로 아무런 영향을 주지 않는 '독립'이기 때문이다. 음주자$a$명을 다룰 때에도 $a$번 곱하여 확률을 구할 수 있다는 데에는 고혈압에 걸리는 사건들이 전제조건이 필요하다. 따라서 유전 정보를 공유하는 가족이나 쌍둥이 등이 연구대상에 있다면 가정을 만족하지 않을 수 있다.)
2) 음주자$b$명이고혈압에 걸리지 않을 확률은 $\left( 1- \frac {1} {1+ e^{-\alpha-\beta_1}} \right)$을$b$번 곱한 $\left( 1- \frac {1} {1+ e^{-\alpha-\beta_1}}\right)^b$이다.
선형 회귀분석은 손으로 직접 회귀계수를 구하는 방법들이 많이 언급되어 있던데, 로지스틱 회귀분석의 경우 언급된 경우가 많지 않아 본 포스팅을 작성해 보았다. 본 글에서 확인할 수 있듯이, 여기에서는 변수의 정규성 등을 가정하지 않았다. 따라서 선형 회귀분석과는 달리 로지스틱 회귀분석에서는 잔차의 정규성을 전제하지 않는다.
[이론] 로지스틱 회귀분석에서 회귀 계수를 구하는 방법 - Maximum likelihood estimation 정복 완료!
음주 여부는 "1) 음주자", "2) 비음주자"로 나뉘는 이분형 변수다. 즉, 음주자의 ALT 평균과 비음주자의 ALT 평균을 비교한 것이었다.
만약, 두 개 이상의 범주로 나뉘는 변수에 대해 모평균의 검정을 하고자 한다면 어떻게 해야 할까? 예를 들어, 흡연 상태를 "1) 비흡연자", "2) 과거 흡연자", "3) 현재 흡연자"로 나누었고, 각 그룹의 폐기능 검사 중 하나인 FVC (Forced Vital Capacity)의 평균에 차이가 있는지 알아보고자 한다.
이때 사용할 수 있는 방법이 일원 배치 분산 분석인 One-way ANOVA (Analysis of Variance)이며 이번 포스팅에서 다뤄볼 주된 내용이다.
Classical Levene's test based on the absolute deviations
from the mean ( none not applied because the location is
not set to median )
data: df$FVC_pPRED
Test Statistic = 1.3065, p-value = 0.2712
Modified robust Brown-Forsythe Levene-type test based on
the absolute deviations from the median
data: df$FVC_pPRED
Test Statistic = 1.2772, p-value = 0.2793
Bartlett test of homogeneity of variances
data: df$FVC_pPRED and df$SMOK
Bartlett's K-squared = 1.8171, df = 2, p-value = 0.4031
Levene 검정 (p-value: 0.2712), Brown-Forsythe test (p-value: 0.2793), Bartlett test (p-value: 0.4031)로 모두 0.05보다 큰 p-value를 갖는다. 따라서 귀무가설을 기각하지 못하므로, 흡연 상태에 따라 FVC_pPRED의 분산이 동일하다는 귀무가설을 채택한다.
따라서 ANOVA의 두 가지 전제조건 (정규성, 등분산성)이 성립하므로 ANOVA를 실행할 수 있다.
a<-aov(FVC_pPRED~SMOK, data=df) : df 데이터의 SMOK에 따른 FVC_pPRED의 평균이 서로 다른지 ANOVA를 시행하고, 이를 a라는 객체에 저장하라. summary(a) : a를 요약하여 보여달라.
결과
Df Sum Sq Mean Sq F value Pr(>F)
SMOK 2 56791 28396 168.9 <2e-16 ***
Residuals 997 167579 168
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Df Sum Sq Mean Sq F value Pr(>F)
SMOK 2 56791 28396 168.9 <2e-16 ***
Residuals 997 167579 168
결과는 복잡하지만 우리가 볼 곳은 빨간 글씨로 칠해놓은 단 하나의 값, p-value다. 값은 $2\times 10^{-16}$보다 작으므로 이는 0.05보다 한참 작은 값이므로 귀무가설을 기각하고 대립 가설을 채택한다. 그렇다면 여기에서 귀무가설 및 대립 가설은 무엇이었는가?
귀무가설: $H0=$ 세 집단의 모평균은 "모두" 동일하다.
대립 가설: $H1=$ 세 집단의 모평균이 모두 동일한 것은 아니다.
우리는 대립 가설을 채택해야 하므로 "세 집단의 모평균이 모두 동일한 것은 아니다."라고 결론 내릴 것이다.
이 말은, 세 집단 중 두 개씩 골라 비교했을 때, 적어도 한 쌍에서는 차이가 난다는 것이다. 따라서 세 집단 중 두 개씩 골라 비교를 해보아야 하며, 이를 사후 분석 (post hoc analysis)이라고 한다. 세 집단에서 두 개씩 고르므로 가능한 경우의 수는 $_3 C_2=3$이다.
pairwise.t.test(df$FVC_pPRED, df$SMOK, p.adj="bonferroni") :df 데이터의 FVC_pPRED를 SMOK변수값에 따라 각각 t-test를 시행하는데, p-value는 Bonferroni방식으로 보정하라.
결과
Pairwise comparisons using t tests with pooled SD
data: df$FVC_pPRED and df$SMOK
0 1
1 < 2e-16 -
2 < 2e-16 8.7e-15
P value adjustment method: bonferroni
Pairwise comparisons using t tests with pooled SD data: df$FVC_pPRED and df$SMOK
0
1
1
<2e-16
-
2
<2e-16
8.7e-15
P value adjustment method: bonferroni
결과가 복잡해 보일지라도 우리는 표만 잘 보면 된다.
SMOK에는 3가지 값 (비흡연자:0, 과거 흡연자:1, 현재 흡연자:2)이 들어있고, 이 중 둘을 뽑아 t-test를 시행할 것이다. 따라서 3개 중 2개를 뽑는 경우의 수인 3가지 p-value가 존재하게 된다.
비흡연자(0)와 과거 흡연자(1)를 비교한 p-value는 빨간색으로 표시된 "<2e-16"이다.
비흡연자(0)와 현재 흡연자(2)를 비교한 p-value는 초록색으로 표시된 "<2e-16"이다.
과거 흡연자(1)와 현재 흡연자(2)를 비교한 p-value는 파란색으로 표시된 "8.7e-15"이다.
즉, 모든 조합에서 평균의 차이가 있다고 결론 내릴 수 있다.
따라서, 우리가 채택한 대립 가설 "세 집단의 모평균이 모두 동일한 것은 아니다."을 구체적으로 이야기하면 "비흡연자와 과거 흡연자, 비흡연자와 현재 흡연자, 과거 흡연자와 현재 흡연자 사이의 모평균에 차이가 있다."라고 결론내릴 수 있다.
scheffe.test(a,"SMOK",console=TRUE) : a(ANOVA 시행한 것)에서 "SMOK"변수에 따라 Scheffe test를 시행하고 결과를 보여달라(console=TRUE).
결과
Study: a ~ "SMOK"
Scheffe Test for FVC_pPRED
Mean Square Error : 168.0834
SMOK, means
FVC_pPRED std r Min Max
0 95.33911 13.31491 463 60.70763 130.0000
1 85.80627 12.39528 295 50.49873 124.0448
2 76.78563 12.96366 242 50.00000 116.7888
Alpha: 0.05 ; DF Error: 997
Critical Value of F: 3.004752
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
FVC_pPRED groups
0 95.33911 a
1 85.80627 b
2 76.78563 c
너무나도 복잡해 보이지만, 마지막 결과를 예쁘게 제시해주기 때문에 이 함수를 소개한 것이다.
groups
0
a
1
b
2
c
0은 group a, 1은 group b, 2는 group c에 속한다. 즉 서로 다른 모평균을 갖는다고 결론 내릴 수 있다.
SMOK가 아니라 RESID에 대해 ANOVA를 시행하고, Scheffe test를 시행한 결과다.
Study: b ~ "RESID"
Scheffe Test for FVC_pPRED
Mean Square Error : 219.1342
RESID, means
FVC_pPRED std r Min Max
0 84.73360 14.84186 323 50.32614 129.7551
1 88.59510 15.17535 335 50.00000 129.7026
2 90.61014 14.39179 342 50.47718 130.0000
Alpha: 0.05 ; DF Error: 997
Critical Value of F: 3.004752
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
FVC_pPRED groups
2 90.61014 a
1 88.59510 a
0 84.73360 b
groups
0
a
1
a
2
b
위 표를 보면 비흡연자 (0)과 과거 흡연자 (1)은 모두 group a에 속해있다. 즉 비흡연자와 과거 흡연자 사이에는 유의미한 차이가 발견되지 않은 것이다. 반면 현재 흡연자는 group b에 속해있으므로 비흡연자나 과거 흡연자와는 유의미한 차이가 있었다는 것이다.
3) Duncan's multiple range test - 코드
사실 Tukey나 다음에 나오는 Duncan은 각 그룹별 표본의 수가 같을 때 사용하는 것이므로 이 데이터의 사후 분석으로는 적절하지 않다. 하지만 우선 그냥 시행해보겠다.
"agriocolae"패키지에 있는 duncan.test() 함수를 이용하므로 설치부터 한다.
duncan.test(a,"SMOK",console=TRUE) : a(ANOVA 시행한 것)에서 "SMOK"변수에 따라 Duncan test를 시행하고 결과를 보여달라(console=TRUE).
결과
Study: a ~ "SMOK"
Duncan's new multiple range test
for FVC_pPRED
Mean Square Error: 168.0834
SMOK, means
FVC_pPRED std r Min Max
0 95.33911 13.31491 463 60.70763 130.0000
1 85.80627 12.39528 295 50.49873 124.0448
2 76.78563 12.96366 242 50.00000 116.7888
Groups according to probability of means differences and alpha level( 0.05 )
Means with the same letter are not significantly different.
FVC_pPRED groups
0 95.33911 a
1 85.80627 b
2 76.78563 c
마지막 세 줄을 보면 0은 group a, 1은 group b, 2는 group c에 속한다. 즉 서로 다른 모평균을 갖는다고 결론 내릴 수 있다.
4) Tukey's studentized range test
TukeyHSD(a)
TukeyHSD(a) : a (ANOVA 시행한 것)으로 사후 분석을 시행하되 Tukey test를 사용하라.
결과
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = FVC_pPRED ~ SMOK, data = df)
$SMOK
diff lwr upr p adj
1-0 -9.532840 -11.79982 -7.265858 0
2-0 -18.553484 -20.96734 -16.139628 0
2-1 -9.020644 -11.65991 -6.381377 0
Tukey multiple comparisons of means 95% family-wise confidence level
결과가 복잡하지만 "p adj"만 보면 된다. 어떤 비교든 p value가 너무 작아 0으로 나타난다. 따라서, 서로 다른 모평균을 갖는다고 결론 내릴 수 있다.
이 시점에서 이런 의문이 들 수 있다.
"각각의 그룹별로 평균을 비교하면 되지, 굳이 왜 ANOVA라는 방법까지 사용하는 것인가?"
아주 논리적인 의문점이다. 하지만, 반드시 ANOVA를 사용해야 한다. 그 이유는 다음과 같다. 본 사례는 흡연 상태에 따른 조합 가능한 경우의 수가 3인데, 각각 유의성의 기준을 α=0.05α=0.05로 잡아보자. 이때 세 번의 비교에서 모두 귀무가설이 학문적인 진실인데(평균에 차이가 없다.), 세 번 모두 귀무가설을 선택할 확률은 (1−0.95)3≈0.86(1−0.95)3≈0.86이다. (이해가 어려우면 p-value에 대한 설명 글을 읽고 오길 바란다. 2022.09.05 - [통계 이론] - [이론] p-value에 관한 고찰)
그런데, ANOVA의 귀무가설은 "모든 집단의 평균이 같다."이다. 따라서 모든 집단의 평균이 같은 것이 학문적 진실일 때, 적어도 한 번이라도 대립 가설을 선택하게 될 확률은 1−0.86=0.141−0.86=0.14가 된다. 즉, 유의성의 기준이 올라가게 되어, 덜 보수적인 결정을 내리게 되고, 다시 말하면 대립 가설을 잘 선택하는 쪽으로 편향되게 된다. 학문적으로는 '다중 검정 (multiple testing)을 시행하면 1종 오류가 발생할 확률이 증가하게 된다.'라고 표현한다.
따라서, 각각을 비교해보는 것이 아니라 한꺼번에 비교하는 ANOVA를 시행해야 함이 마땅하다.
여기에서 한 번 더 의문이 들 수 있다.
"사후 분석을 할 때에는 1종 오류가 발생하지 않는가?"
그렇다. 1종 오류가 발생할 확률이 있으므로, p-value의 기준을 더 엄격하게 (0.05보다 더 작게) 잡아야 한다. P-value를 보정하는 방법은 여러 가지가 나와있는데, 그중 많이 쓰이는 네 가지를 언급한 것이다.
어떤 사후 분석을 쓸 것인가
이 논의에 대해 정답이 따로 있는 것은 아니다. 적절한 방법을 사용하여 논문에 제시하면 되고, 어떤 것이 정답이라고 콕 집어 이야기할 수는 없다. 다만, 사후 분석 방법이 여러 가지가 있다는 것은 '사후 분석 방법에 따라 산출되는 결과가 달라질 수 있다.'는 것을 의미하고, 심지어는 '어떤 사후 분석 방법을 채택하냐에 따라 유의성 여부가 달라질 수도 있다.'는 것을 의미한다. 심지어, ANOVA에서는 유의한 결과가 나왔는데, 사후 분석을 해보니 유의한 차이를 보이는 경우가 없을 수도 있다. 따라서 어떤 사후 분석 방법 결과에 따른 결과인지 유의하여 해석할 필요가 있다.
[R] 변수의 유형 (타입, type) 확인 및 변경 - as.factor(), as.numeric(), str()
변수는 보통 다음 네 가지의 종류로 나누곤 한다.
1) 명목 척도: 범주형, 순서 없음
예시) 성별 - "남성", "여성"
2) 순서 척도: 범주형, 순서 있음
예시) 암의 병기 - "1기", "2기", "3기", "4기"
3) 등간 척도: 연속형, 곱셈 불가
예시) IQ 점수 - IQ가 150인 사람보다 100인 사람은 50점이 더 높다. 100점인 사람이 50점인 사람도 똑같이 50점이 더 높다. 하지만 100점인 사람이 50점보다 두 배 더 똑똑하다고 할 수는 없다.
4) 비율 척도: 연속형, 곱셈 가능
예시) 나이 - "1세", "55세",...
그런데, 학문적으로 저렇게 나눈다고 하여도, 의학 통계를 하는 사람에게 저렇게 세분하는 것이 그렇게까지 중요한 것은 아니다. 단지 우리에게는 범주형 (비연속형, 이산형) 변수와 연속형 변수가 있다는 사실만이 중요하다. 이번 포스팅에서는 변수의 형태를 확인하고, 원하는 경우 다른 유형으로 변경하는 방법에 대해 알아보겠다.
맨 앞에 있는 "IDNO", "SEX", "SMOK", "ALCOHOL", ... ,"TRNASPORT"는 변수의 이름이다.
"IDNO"부터 "FVC_pPRED"까지는 num이라고 적혀있다. 이는 numeric의 약자이며, 숫자형 (연속형) 변수임을 의미한다.
"TRANSPORT"는 chr이라고 적혀있다. 이는 character의 약자이며, 문자형 변수임을 의미한다.
그런데, 서두에 우리는 변수를 범주형, 연속형 변수로 나누기로 했다. 그런데, 숫자로 이루어진 변수는 모두 연속형 변수로 취급되고 있고, 문자가 들어간 변수는 그저 문자형 변수로 취급되고 있다. 그런데 이는 적절하지 않다. 예를 들어 성별을 나타내는 "SEX"변수는 1과 2로 이루어진 범주형 변수다. 여성을 나타내는 0이 남성을 나타내는 1보다 작다고 할 수 없는 것이다. 그저 숫자로 나타낸 것 뿐이다. 여성을 2로 나타낼 수도 있었는데, 그렇다고 하여 여성이 남성보다 크다고 할 수는 없는 것이다.
코드북을 살펴보면 알 수 있지만, 다음과 같이 변수를 구분할 수 있다.
변수명
변수 종류
SEX
범주형
SMOK
범주형
ALCOHOL
범주형
RESID
범주형
TWIN
범주형
RH
범주형
HTN
범주형
SBP
연속형
ALT
연속형
AST
연속형
ALT_POST
연속형
FVC_pPRED
연속형
TRANSPORT
범주형
따라서, "IDNO", "SEX", "SMOK", "ALCOHOL", "RESID", "TWIN", "RH", "HTN", "TRANSPORT"는 범주형 자료로 바꿔주어야 한다. 이럴 때에는 범주형 변수로 바꾸어주는 as.factor() 함수를 사용해야 한다.
위에서 "IDNO", "SEX", "SMOK", "ALCOHOL", "RESID", "TWIN", "RH", "HTN", "TRANSPORT"의 변수 형태는 "num"이었는데 "Factor"로 바뀐 것을 알 수 있다.
"SMOK"는 "Factor w/ 3 levels"이라고 적혀있는데, 이는 "Factor with 3 levels"의 약자로 "범주형 변수인데, 3개의 범주가 존재한다"는 뜻이다. 실제로도 '비흡연자', '과거 흡연자', '현재 흡연자'로 나누어놨으니 맞게 변환된 것을 알 수 있다.
위와 같이 바꾸고 나서 가끔은 다시 연속형 변수로 바꾸거나 문자형 변수로 되돌려야 할 때가 있을 수 있다. 이때는 각각 as.numeric()과 as.character() 함수를 사용하면 된다. "RESID" 변수를 연속형 변수로, "TRANSPORT"변수를 문자형 변수로 되돌려보자.
참고로, as.factor()가 아닌 factor()라는 함수도 존재한다. 기능은 같으나 as.factor()가 특정 상황에서 조금 더 빠르게 작동하여 as.factor()를 본문에서는 소개했지만, factor() 함수를 사용해도 같은 결과를 내니 원하는 것을 사용하면 된다.
Brown&Forsythe 의 등분산 검정은 "levene.test()"라는 함수를 쓰는데, 이는 "lawstat"이라는 패키지에 있으므로 설치를 한다. Bartlett의 등분산 검정을 시행할 때 사용하는 "bartlett.test()"는 기본 내장 함수이므로 별도의 설치가 필요 없다.
#Brown&Forsythe levene.test(df$SBP, df$HTN) : df 데이터의 SBP(수축기 혈압) 변수를 df 데이터의 HTN(고혈압 여부) 변수에 따라 Brown&Forsythe 등분산 검정을 시행하라.
#Bartlett bartlett.test(df$SBP, df$HTN) : df 데이터의 SBP(수축기 혈압) 변수를 df 데이터의 HTN(고혈압 여부) 변수에 따라 Bartlett 등분산 검정을 시행하라.
결과
Modified robust Brown-Forsythe Levene-type test based on
the absolute deviations from the median
data: df$SBP
Test Statistic = 0.010831, p-value = 0.9171
Bartlett test of homogeneity of variances
data: df$SBP and df$HTN
Bartlett's K-squared = 3.5705e-07, df = 1, p-value =0.9995
Modified robust Brown-Forsythe Levene-type test based on the absolute deviations from the median
data: df$SBP Test Statistic = 0.010831, p-value = 0.9171
세상에 존재하는 모든 사람을 대상으로 연구를 하면 참 좋겠지만, 시간적인 이유로, 그리고 경제적인 이유로 일부를 뽑아서 연구를 진행할 수밖에 없다. 모든 사람을 모집단이라고 하고, 뽑힌 일부를 표본이라고 한다. 우리는 표본으로 시행한 연구로 모집단에 대한 결론을 도출해내고자 할 것이다.
1000명에게 피검사를 시행하였고, 간 기능 검사의 일환으로 ALT 수치를 모았다. 이 데이터를 기반으로 1000명이 기원한 모집단 인구에서의 ALT평균이 어떻게 될지 예측하는 것이 T-test이다. T-test는 크게 세 가지로 나눌 수 있다.
Shapiro-Wilk normality test
data: df_whtn$SBP
W = 0.9975, p-value = 0.6677
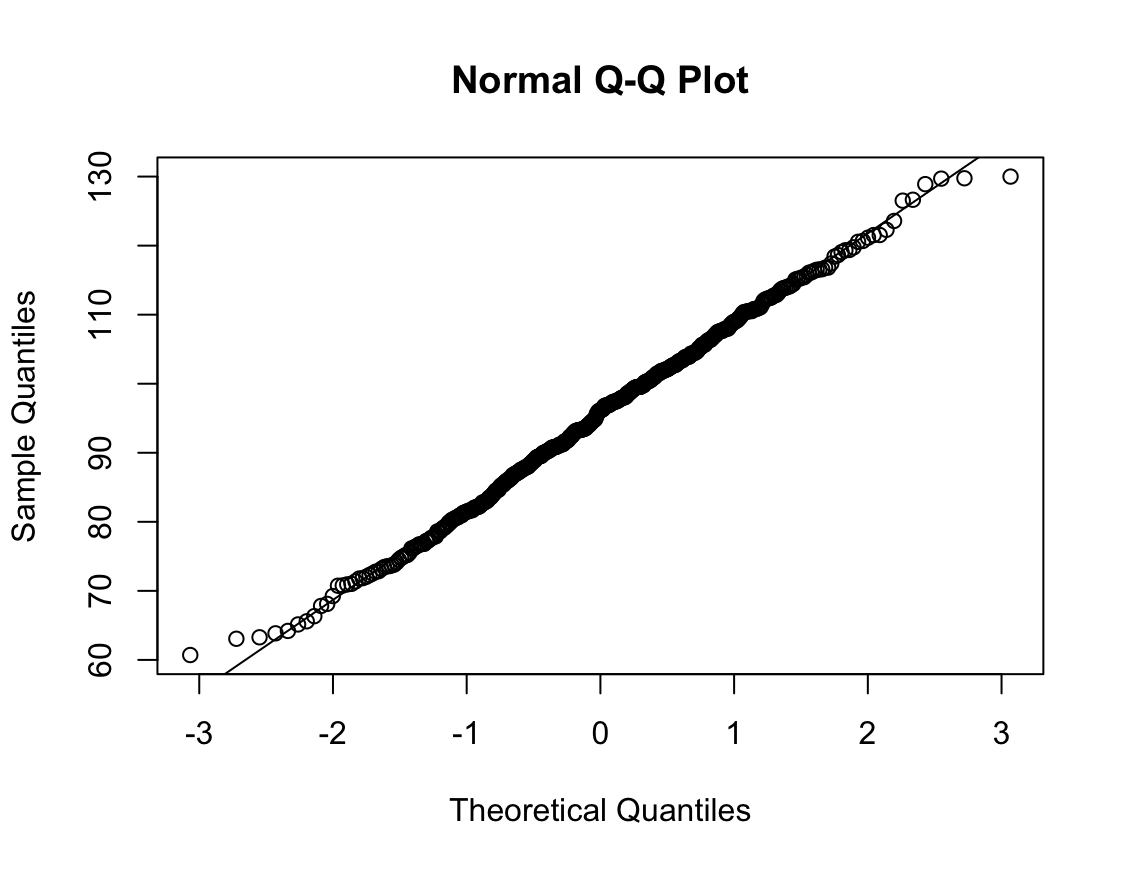
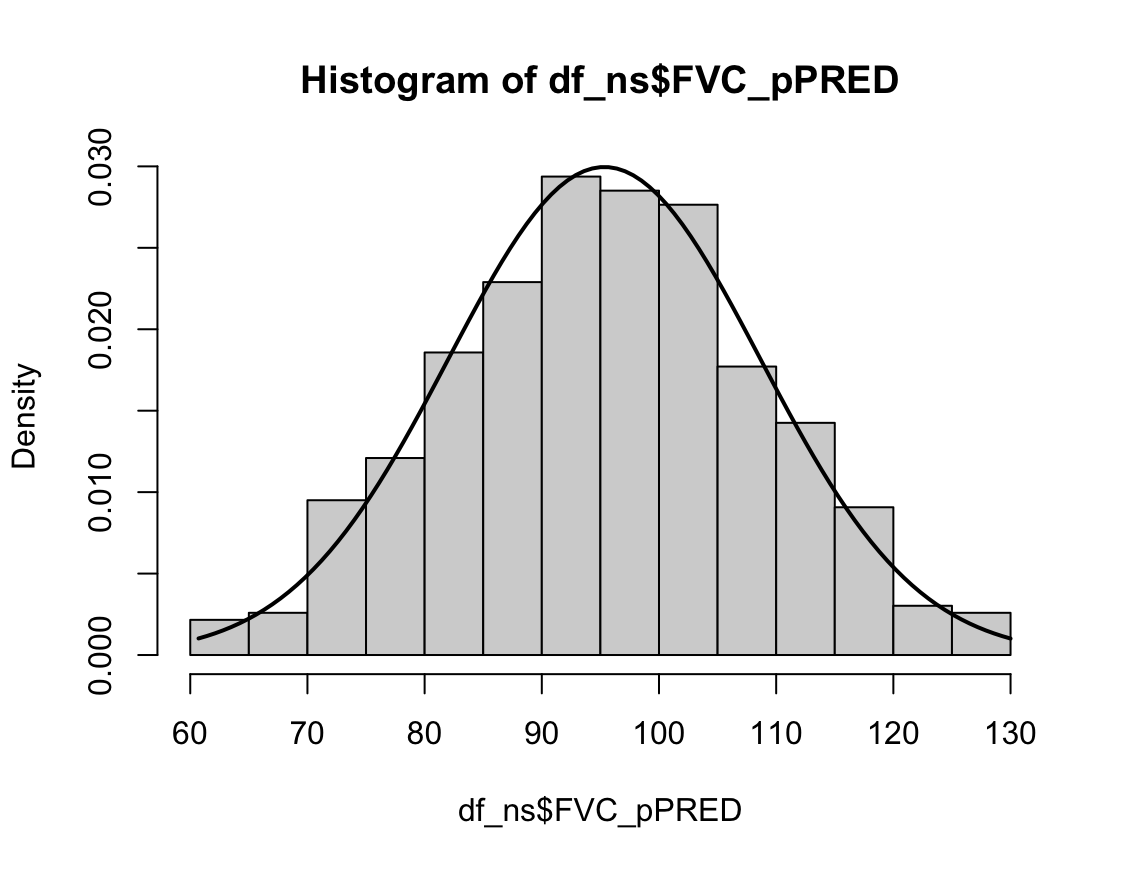
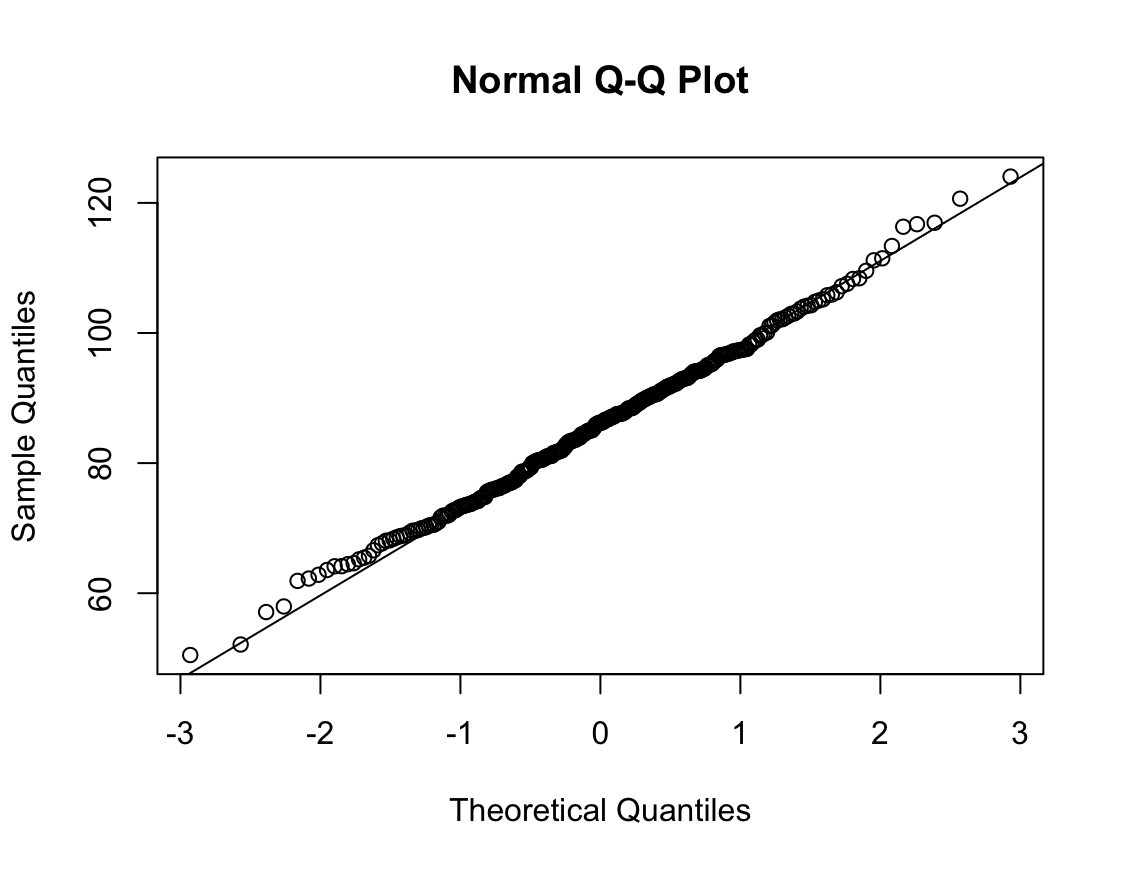
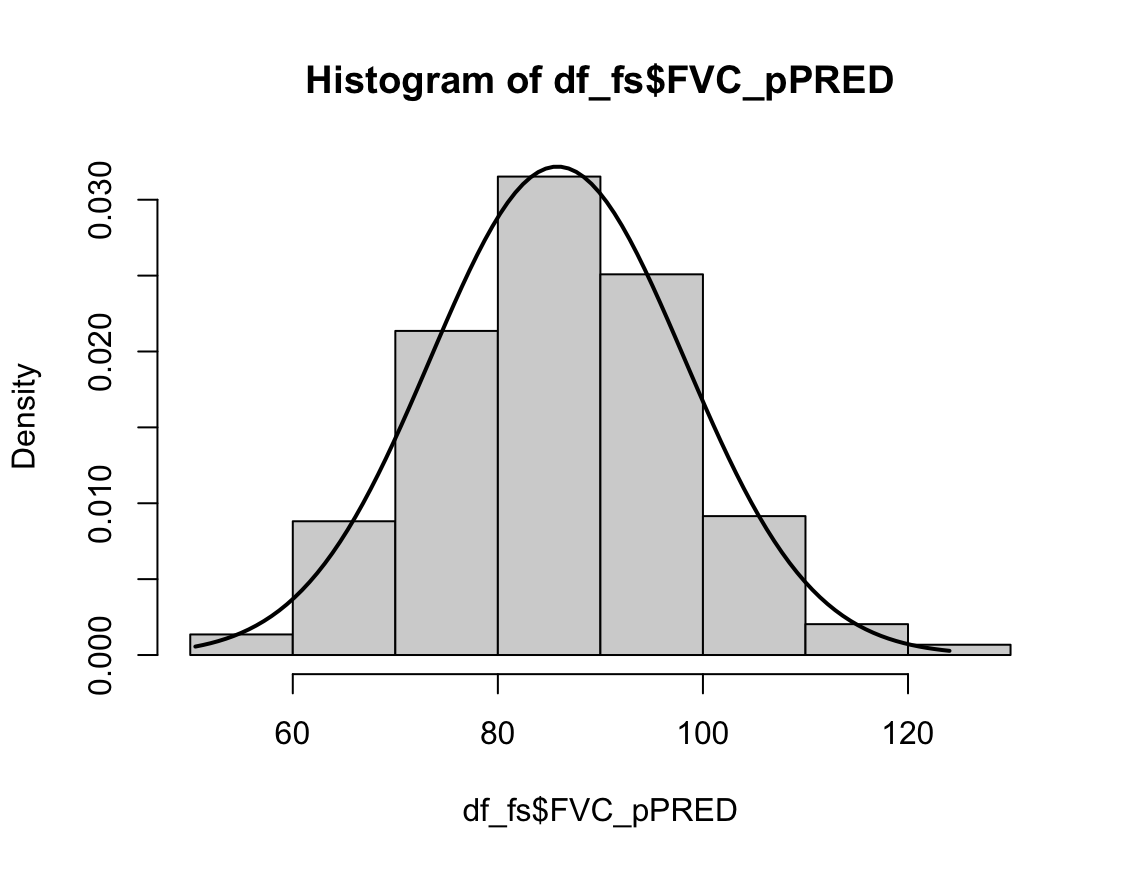
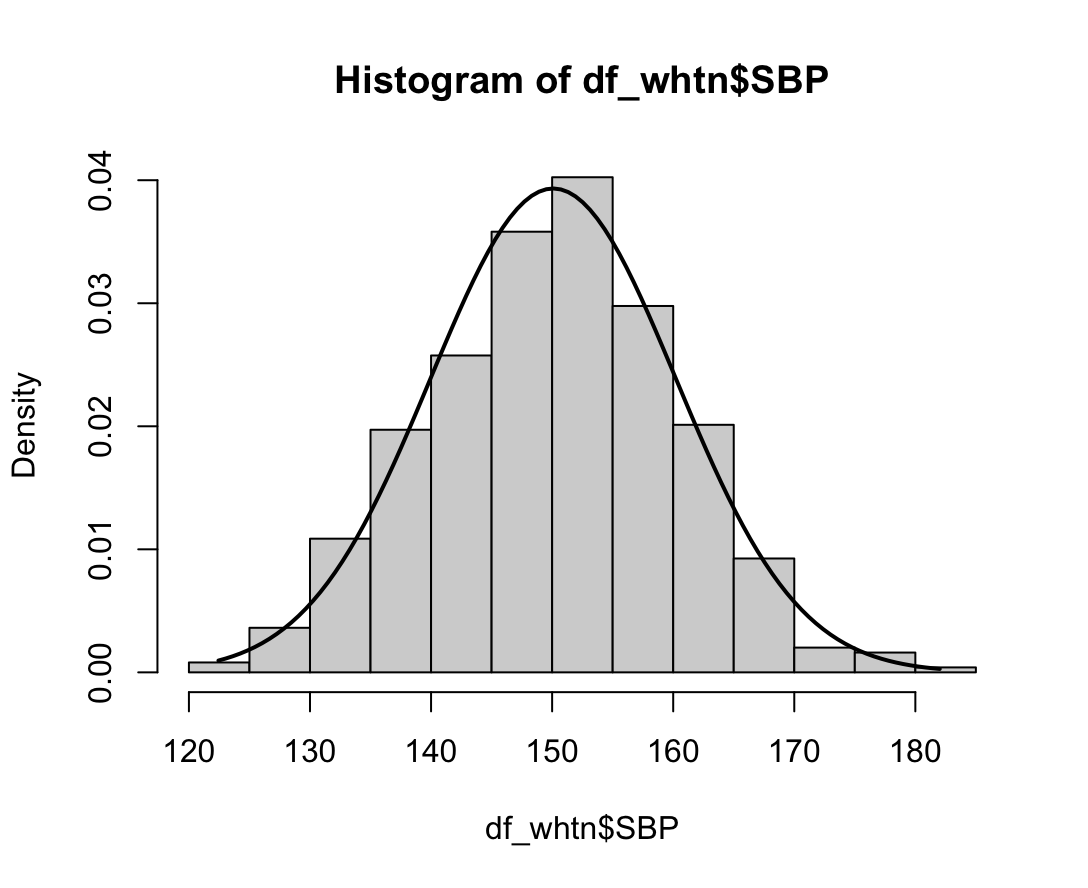
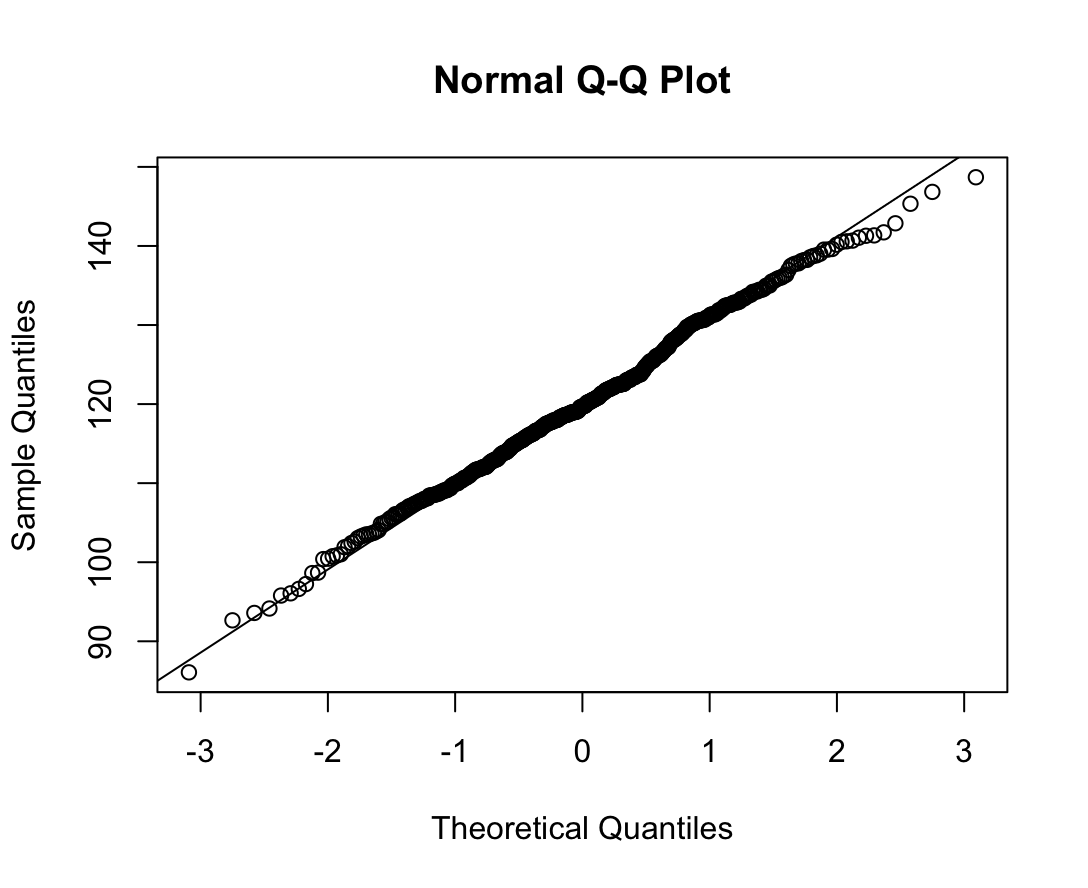
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다.
2) 정상인
Shapiro-Wilk normality test
data: df_wohtn$SBP
W = 0.99676, p-value = 0.4119
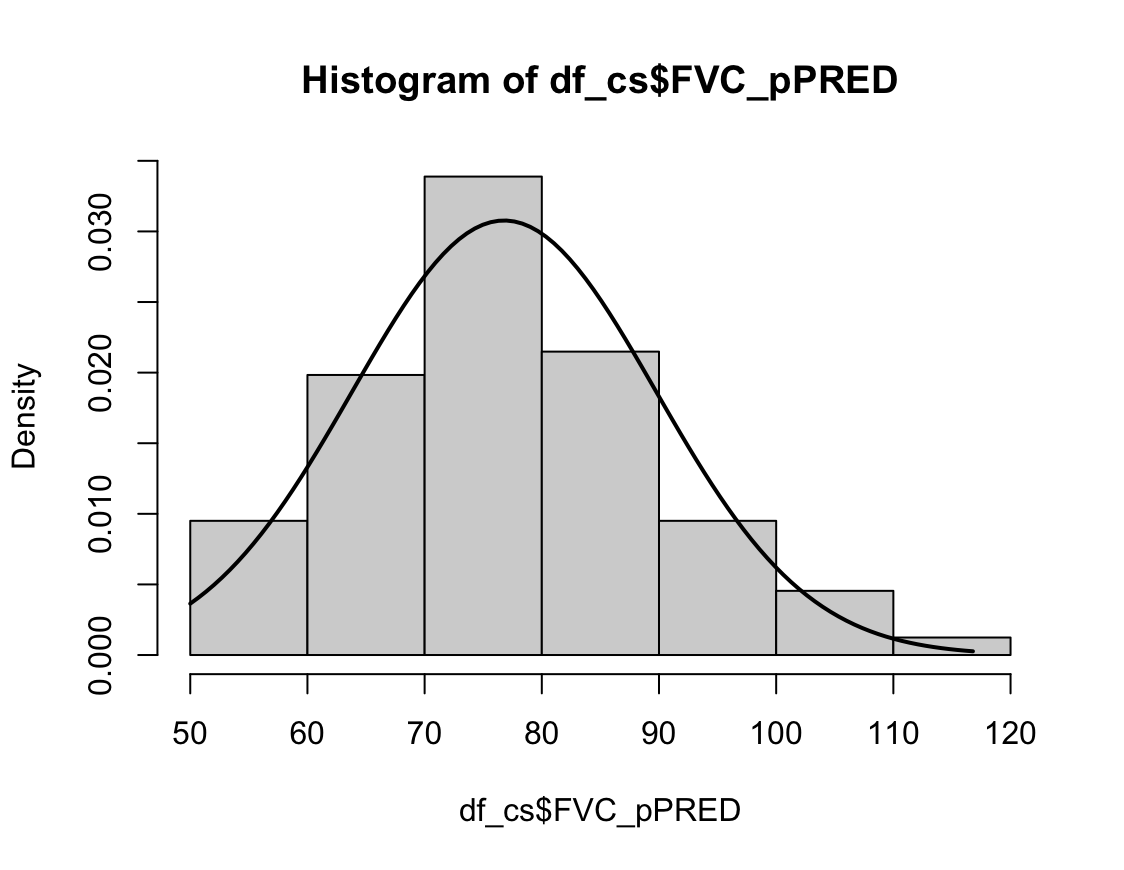
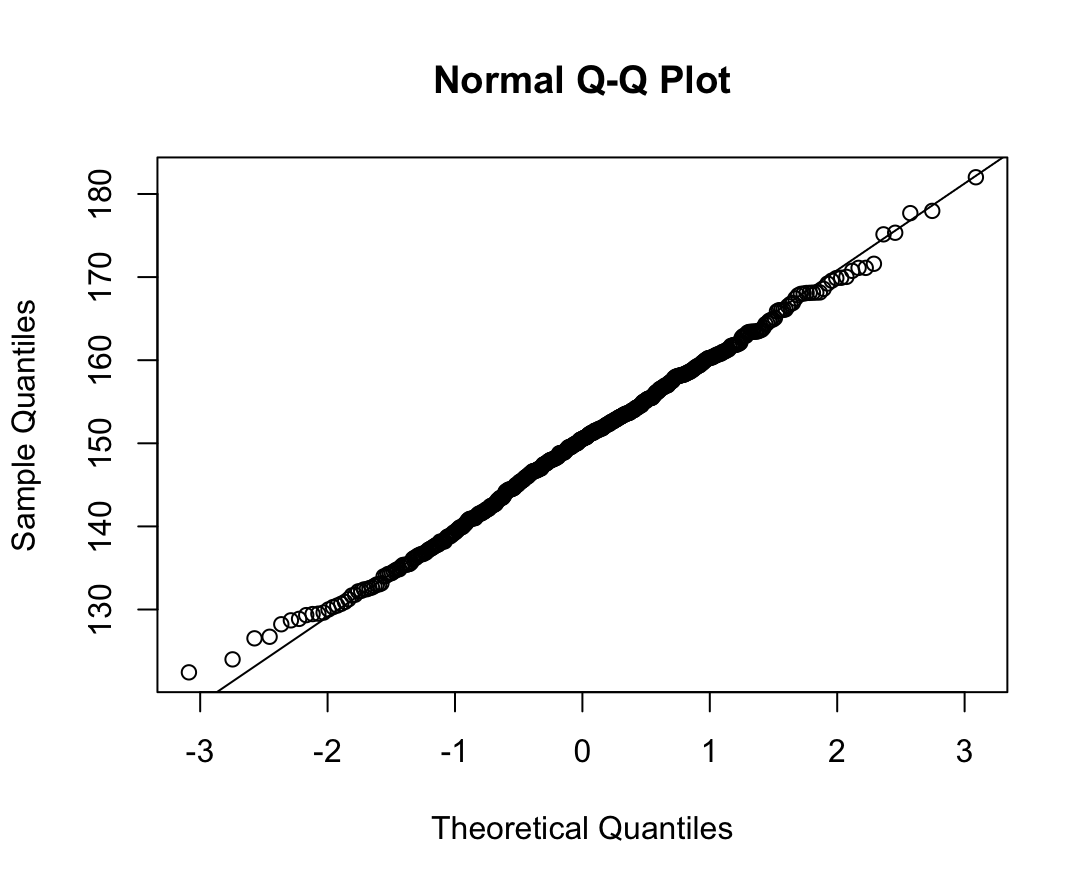
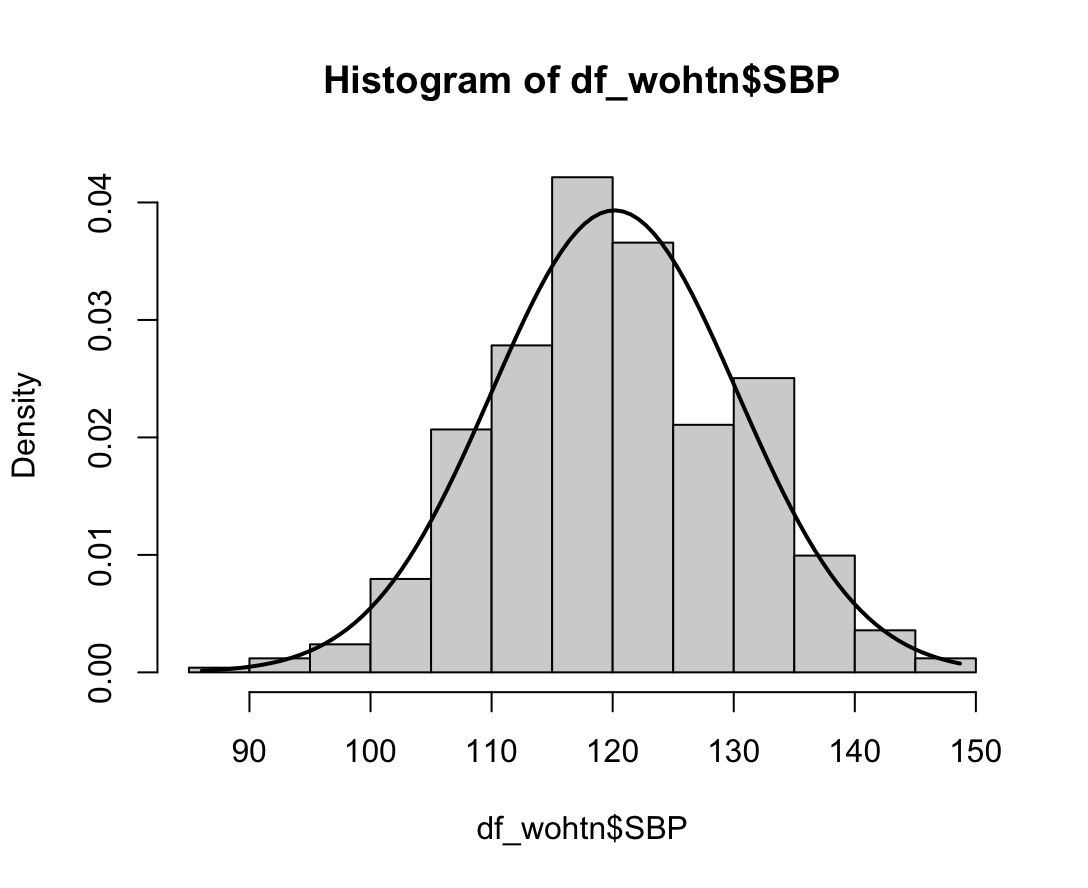
N수가 2,000개 미만이므로 Shapiro-Wilk 통계량의 p-value를 보면 0.05 이상이며, Q-Q Plot은 대부분의 데이터가 선상에 있고, 히스토그램에서도 정규성을 따르는 것처럼 볼 수 있다.
전제조건이 성립한다. 즉, 고혈압 유병 여부에 따른 수축기 혈압 (SBP)의 분포가 정규성을 따른다고 할 수 있다. 따라서 독립 표본 T 검정 (Independent samples T test, Two samples T test)을 시행할 수 있다.
등분산성 검정
독립 표본 T 검정 (Independent samples T test, Two samples T test)은 고혈압 유병 여부에 따른 수축기 혈압의 분포의 분산이 같은지 여부에 따라 시행하는 검사 방법이 다르다. 따라서 분산이 같은지 확인하는 등분산성 검정을 먼저 시행해야 한다.
#F test var.test(SBP~HTN, data=df) : 등분산 검정을 하는데, HTN에 따라 SBP의 분포의 분산이 같은지 검정하라. 데이터는 df를 사용한다.
#Levene의 등분산 검정
install.packages("lawstat") : Levene의 등분산 검정을 하기 위해서는 lawstat이라는 패키지를 설치해야 한다. library("lawstat") : lawstat패키지를 불러온다. levene.test(df$SBP, df$HTN, location="mean") : df 데이터의 HTN에 따라 df 데이터의 SBP의 분포의 분산이 같은지 검정하라. 이때 [location="mean"]을 적어주어야 Levene의 등분산 검정을 시행한다.
결과
F test to compare two variances
data: SBP by HTN
F = 0.99995, num df = 502, denom df = 496, p-value =
0.9994
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.8387988 1.1919414
sample estimates:
ratio of variances
0.9999465
Classical Levene's test based on the absolute deviations
from the mean ( none not applied because the location is
not set to median )
data: df$SBP
Test Statistic = 0.010363, p-value = 0.9189
F test to compare two variances data: SBP by HTN F = 0.99995, num df = 502, denom df = 496, p-value =0.9994 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.8387988 1.1919414 sample estimates: ratio of variances 0.9999465 Classical Levene's test based on the absolute deviations from the mean ( none not applied because the location is not set to median ) data: df$SBP Test Statistic = 0.010363, p-value = 0.9189
결과 창에 나오는 것들이 많아 복잡해 보이지만 위에 파란색 볼드로 처리해놓은 내용만 보면 된다. F test의 p-value는 0.9994, Levene의 등분산 검정의 p-value는 0.9189이다. 모두 0.05보다 크므로 귀무가설을 기각할 수 없으며 귀무가설을 택해야 한다. 여기에서의 귀무가설은 "HTN에 따라 SBP의 분포의 분산에 차이가 없다."이므로 분산이 같다는 결론을 내린다.
t.test(df_wohtn$SBP, df_whtn$SBP, var.equal=TRUE) : 고혈압이 없는 사람들의 수축기 혈압 (df_wohtn$SBP)과 고혈압이 있는 사람들의 수축기 혈압 (df_whtn$SBP)으로 t-test를 시행하라. 대신 두 군의 분산은 같다고 가정한다.
만약, 등분산성 검정 결과 분산이 다르다고 결론이 났으면 "var.equal=FALSE" 라고 적으면 된다. 혹은 t.test의 var.equal은 FALSE를 기본값으로 가지므로, "var.equal=TRUE"를 그냥 지워도 된다.
결과
Two Sample t-test
data: df_wohtn$SBP and df_whtn$SBP
t = -46.666, df = 998, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-31.19793 -28.68000
sample estimates:
mean of x mean of y
120.1473 150.0862
Two Sample t-test
data: df_wohtn$SBP and df_whtn$SBP
t = -46.666, df = 998, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
결과가 복잡한 듯 하지만 파란색 글씨만 읽으면 된다. p-value는 $2.2 \times 10^{-16}$보다 작다. 따라서 귀무가설을 기각할 수 있으며, 본 검정에서 귀무가설은 "HTN에 따라 SBP의 평균이 같다."이므로 "HTN에 따라 SBP의 평균은 다르다."라고 결론 내릴 수 있다. 마지막 행을 보면 "mean of x"은 120.1473, "mean of y"은 150.0862라고 알려주고 있는데, x는 코드에 처음 들어간 "df_wohtn$SBP"를 의미하고, y는 두 번째로 들어간 "df_whtn$SBP"를 의미한다. 즉 고혈압이 없는 군의 수축기 혈압 평균은 120.1473, 고혈압이 없는 군의 수축기 혈압 평균은 150.0862다.
df_whtn<-df[df$HTN==1,] df에서 HTN이 1인 행만 추출하여 df_whtn에 저장한다. (행이라서 쉼표 앞에 조건이 붙는다.) df_wohtn<-df[df$HTN==0,]df에서 HTN이 0인 행만 추출하여 df_wohtn에 저장한다. (행이라서 쉼표 앞에 조건이 붙는다.)
"%>%"은 dplyr에서 chain operation이라고 불리는 연산자인데, Ctrl(Cmd for mac) + Shift + M이라는 단축키로 입력할 수 있고, 처음에는 어색해 보일 수 있지만 쓰다 보면 이렇게 편한 연산자가 없다. 이는 생각의 흐름대로 분석을 할 수 있게 해 준다.
이 경우, "데이터 df을 가져와서 HTN이 1인 데이터만 고르는 필터링을 하라."로 이해할 수 있다.