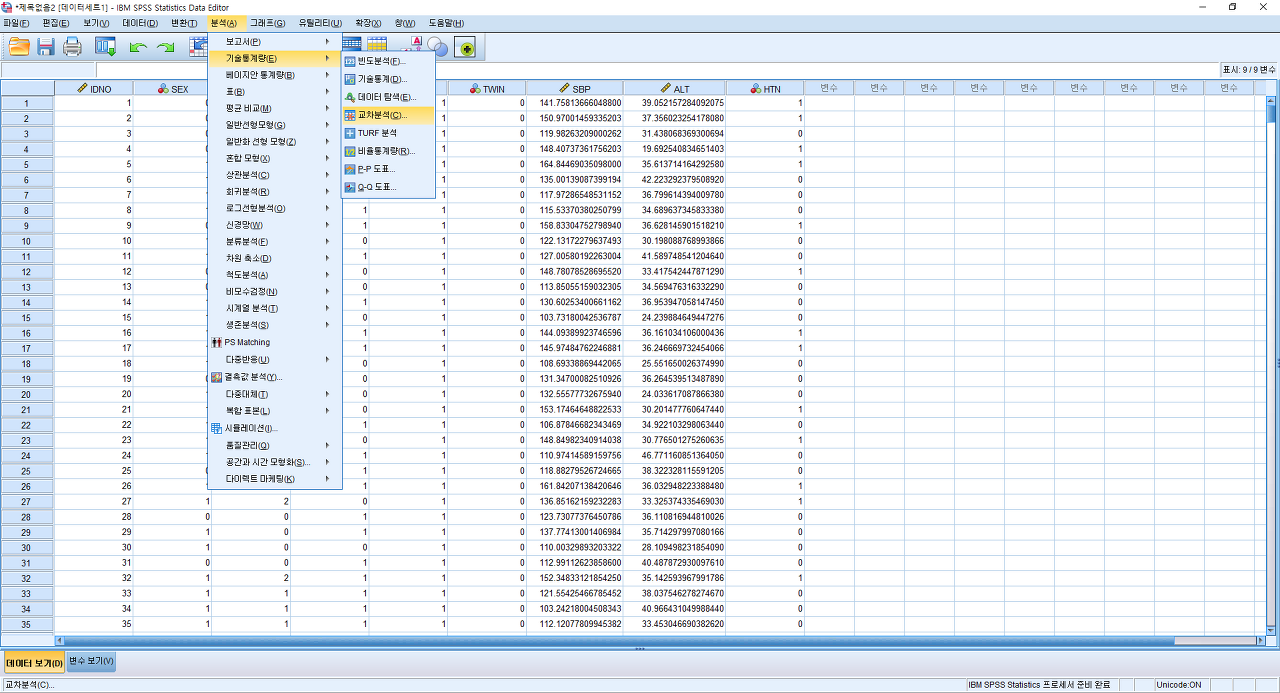
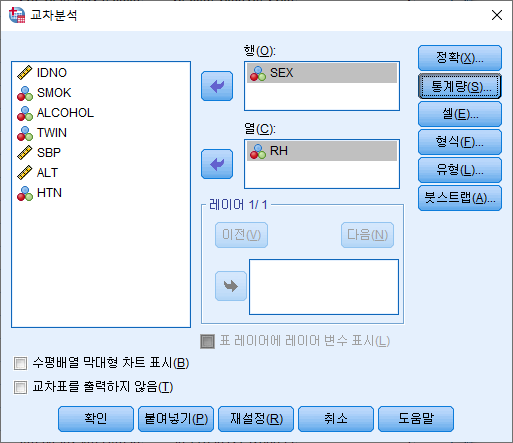
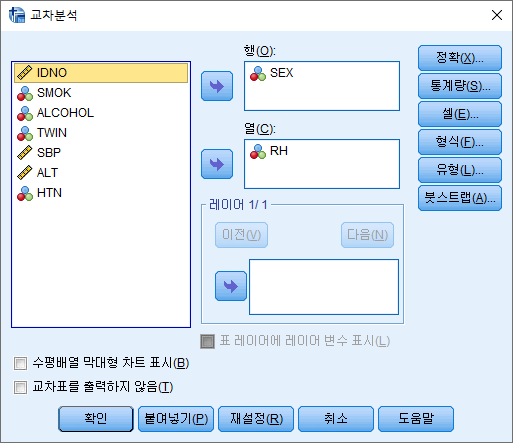
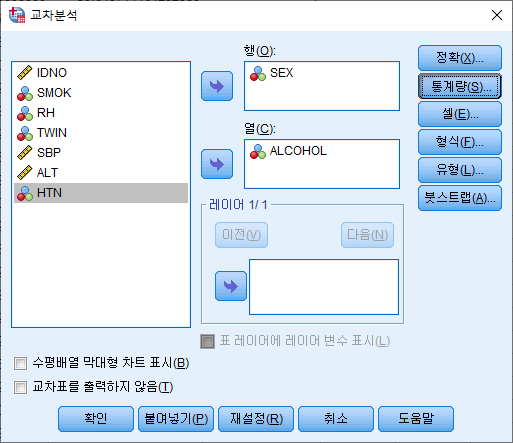
2) 행과 열에 원하는 변수를 넣어주기. 여기에서는 행에 SEX를, 열에 RH을 넣었다. 그리고 통계량(S)를 클릭한다.
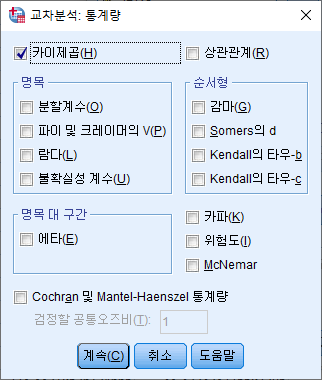
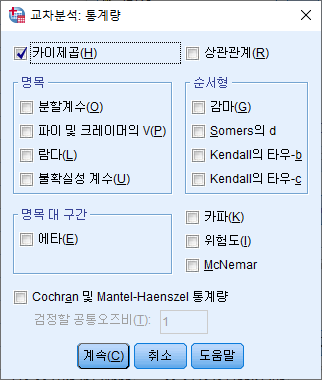
3) 카이제곱(H)의 체크박스를 선택한다. "계속(C)"버튼을 누른다.
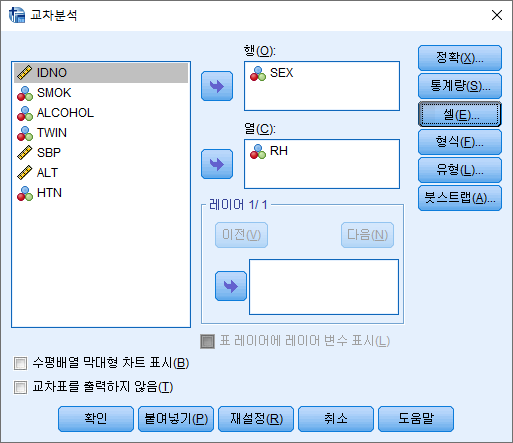
4) 셀(E)을 클릭한다.
5) 기대빈도 (E) 체크박스를 선택하고 "계속(C)"를 누른다.
6) "확인" 버튼을 눌러 결과를 확인한다.
결과
1) 기대빈도
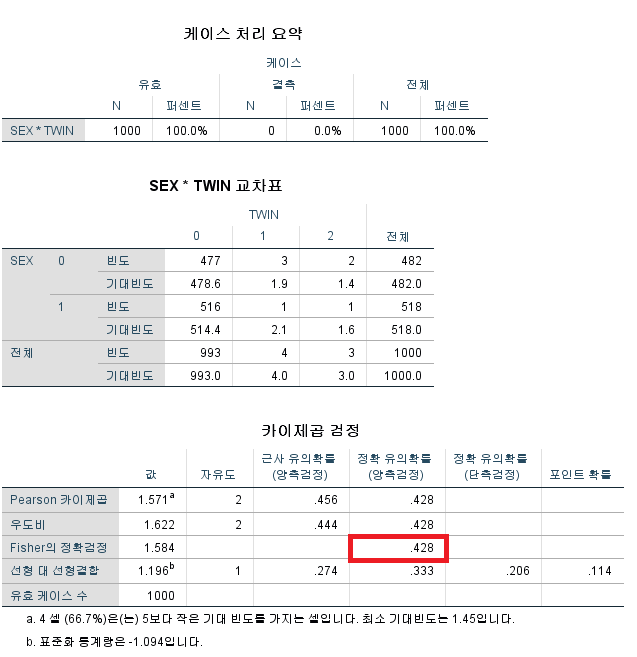
기대 빈도가 5 미만인 셀이 2개 (50%)이므로 카이 제곱 검정이 아닌 피셔 정확 검정 (Fisher's exact test)을 시행해야 한다.
또한, "2 셀 (50.0%)은(는) 5보다 작은 기대 빈도를 가지는 셀입니다."이라고 말하며 카이 제곱 검정이 아닌 피셔 정확 검정을 시행해야 한다고 경고하고 있다.
2) 피셔 정확 검정 결과
피셔 정확 검정의 결과를 볼 때에는 정확 유의확률 (양측검정)의 결과를 보는 것이 일반적이다. 유의성 기준을 0.05로 잡았을 때, 성별과 RH 혈액형 여부는 독립이 아니라고 할 수 없다. 따라서 성별과 RH 혈액형 사이에는 어떠한 관계가 있다고 볼 수 없다. 양측 검정이 아닌 단측 검정을 보아야 할 때도 있다. 이는 대립 가설이 어떤 것이냐에 따라 달라지는데 이에 대한 자세한 내용은 다음 포스팅에서 확인할 수 있다.
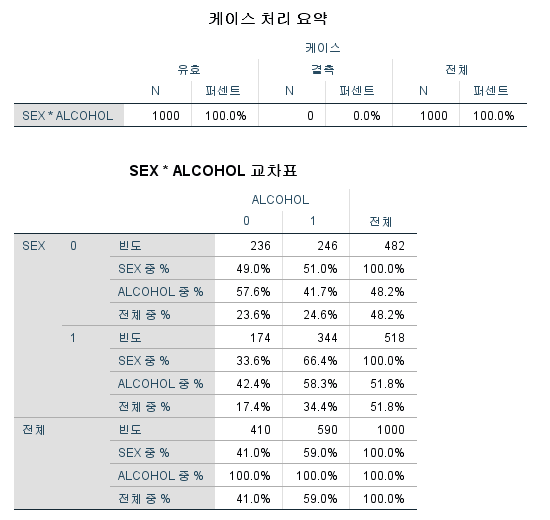
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
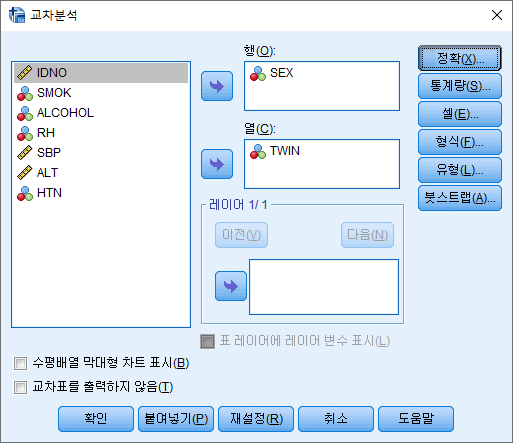
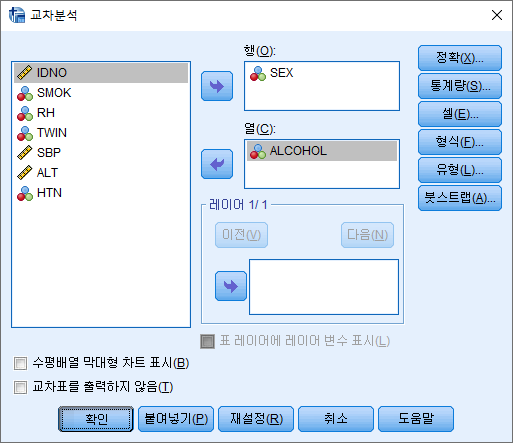
2) 행과 열에 원하는 변수를 넣어주기. 여기에서는 행에 SEX를, 열에 ALCOHOL을 넣었다. 그리고 통계량(S)를 클릭한다.
3) 카이제곱(H)의 체크박스를 선택한다. "계속(C)"버튼을 누른다.
4) 셀(E)을 클릭한다.
4) 기대빈도 (E) 체크박스를 선택하고 "계속(C)"를 누른다.
5) "확인" 버튼을 눌러 결과를 확인한다.
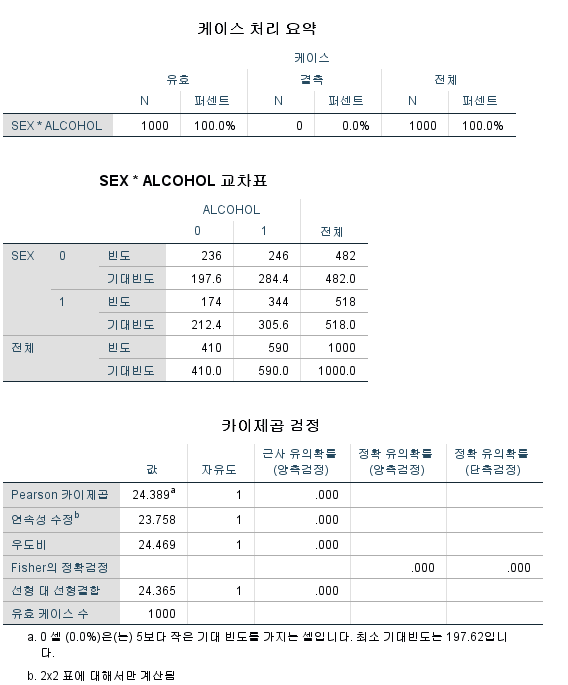
결과
1) 기대빈도
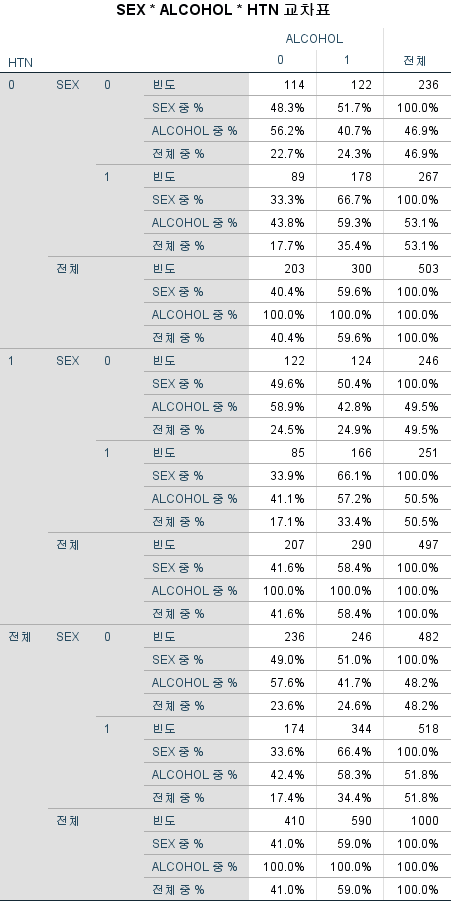
카이 제곱 검정을 시행하기 위한 전제조건은 기대 빈도가 5 미만이 셀이 전체 셀 중 25% 미만이어야 한다는 것이므로 기대 빈도를 산출해 보았고 모두 5 이상이므로 문제가 없었다.
또한, "0 셀 (0.0%)은(는) 5보다 작은 기대 빈도를 가지는 셀입니다."이라고 말하며 카이 제곱 검정을 시행해도 된다고 안심시켜주고 있다.
2) 카이 제곱 검정 결과
카이 제곱 검정의 결과를 볼 때에는 첫 번째 행 "Pearson 카이제곱"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. "0.000"이라고 쓰여있는 것은 "<0.001"을 의미한다. 따라서 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
3) 연속성 수정 카이 제곱 검정 결과 (Chi-squared test with Yates's correction for continuity)
연속성 수정을 하고 싶은 경우 두 번째 행 "연속성 수정"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. p-value는 0.001보다 작으므로 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
[SPSS] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기
수천 명의 정보를 포함한 데이터를 한눈에 요약하고 싶을 때가 많다. 나이, 혈압과 같은 연속형 변수는 평균으로 요약하곤 하는데, 성별이나 음주 여부는 평균을 구할 수 없으니 빈도를 제시하곤 한다. 이를 표로 제시하면 도수분포표 (Frequency table)가 된다. 이를 넘어서 남성 중 음주자가 몇 명인지, 여성중 비음주자가 몇 명인지 알고 싶을 때가 있는데, 이때 사용하는 것이 분할표 (Contingency table)이다. 즉 본 글의 목적은 다음 두 개의 표 내용을 채우는 것이다.
의학 및 보건학 논문을 읽다 보면 빠지지 않고 나오는 숫자가 p-value다. 연구를 하는 사람들도 그저 p-value는 0.05보다 작기만을 바라는 경향이 있다. 하지만, p-value에 관한 의미를 정확히 이해하지 못한다면 엉뚱한 결론을 짓는 잘못을 저지를 수도 있다. 따라서 본 포스팅에서는 p-value가 무엇인지 알아보고자 한다.
왜 다들 p-value를 이해하려 하지 않을까?
논문을 쓰는 저자들도, 읽는 독자들도 p-value의 의미를 이해하지 않고 사용하는 경향이 있다. 이는 아마 p-value의 개념 자체가 꽤 복잡하기 때문일 것이다. 본 포스팅이 그 복잡한 내용으로 시작한다면 그들과 똑같은 짓을 하는 것일 테니, 학문적으로 복잡한 내용은 글 말미에 언급하도록 하겠다.
실생활에 존재하는 p-value (One-tailed)
인식은 못하고 있겠지만, 여러분 모두 p-value가 무엇인지 아주 깊이 이해하고 있다. 다음 상황을 보자.
어느 동네에 야바위꾼이 여행객을 유혹한다.
야바위꾼: "동전을 던져 앞면이 나오면 제가, 뒷면이 나오면 당신이 이기는 것입니다. 진 사람은 이긴 사람에게 10,000원을 주면 됩니다." 여행객 A: "내가 하겠소. 10판을 합시다."
야바위꾼은 동전을 10번 던졌고, 앞면이 9회, 뒷면이 1회 나왔다.
야바위꾼: "나에게 80,000원을 주시오." 여행객 A: (돈을 던지며) "이 나쁜 사기꾼아!!"
누구든 저 여행객 A 입장이 되면 야바위꾼이 사기꾼이라고 생각할 것이다. 놀랍게도 이 짧은 이야기에 귀무가설, 대립 가설, p-value에 관한 내용이 모두 담겨있다. 다시 이야기로 돌아가 왜 여행객 A가 야바위꾼이 사기꾼이라고 생각하게 됐는지 그 사고 과정을 낱낱이 살펴보도록 하자. 여행객 A는 아마 다음과 같은 사고 과정을 거쳤을 것이다.
(야바위꾼의 호객행위를 들었을 때)
- "저 동전은 공정한 동전이라 앞면이 나올 확률이 $1/2$, 뒷면이 나올 확률이 $1/2$일 거야."
- "10번 던지면 5회쯤은 앞면이, 5회쯤은 뒷면이 나오겠지. 물론 5:5가 아니라 6:4 정도의 결과도 발생할 수는 있겠지. 운이 좋아 뒷면이 6회가 나온다면 내가 20,000원을 따겠구먼."
(동전을 던지고 난 뒤)
- "어떻게 앞면이 9번이나 나올 수가 있어?! 이 정도의 일이 일어날 확률이 얼마나 된다고?!"
- "분명 저 동전은 일반 동전이 아닐 거야. 앞 면이 더 잘 나오도록 어떤 조치를 취해뒀을 거야."
이 이야기의 귀무가설, 대립 가설, p-value은 다음과 같다.
귀무가설 : "저 동전은 공정한 동전이라 앞면이 나올 확률이 $1/2$, 뒷면이 나올 확률이 $1/2$일 거야."
대립 가설: "앞 면이 더 잘 나오도록 어떤 조치를 취해뒀을 거야"
p-value: "이 정도의 일이 일어날 확률"
p-value
위 내용에서 "이 정도의 일이 일어날 확률"은 얼마나 될까?
또한, "이 정도의 일"이란 무엇일까?
여행객 A는 앞면이 10회 나왔다면 더 화가 났을 것이다. 앞면이 8회 나온 상황에서도 화가 날 수 있지만,"이 정도의 일"까지는 아닌 것이다. 따라서"이 정도의 일"이란 "앞면이 10회 나오는 일"과 "앞면이 9회 나오는 일"인 것이다. 이런 확률은 다음과 같이 계산된다.
즉 여행객 A는 1.07%의 확률을 뚫고 일어난 일이 본인에게 발생했다는 것을 믿을 수 없어 "앞 면이 더 잘 나오도록 어떤 조치를 취해뒀을 거야"라는 생각을 하는 것이 합리적이라고 봤을 것이다.
실생활에 존재하는 p-value (Twe-tailed)
위의 상황은 "one-tailed"의 상황이었다. 이게 뭔지 몰라도 아래 "two-tailed"을 다루는 이야기를 보면 이해가 될 것이다.
어느 동네에 야바위꾼 두 명이 여행객들을 유혹한다.
야바위꾼A: (야바위꾼 B를 보며) "동전을 던져 앞면이 나오면 제(야바위꾼 A)가, 뒷면이 나오면 당신(야바위꾼 B)이 점수 1점을 획득합니다. 10번을 던졌을 때 저희 둘 중 한명이 9점 이상을 얻으면 저희의 승리, 둘 다 8점 이하라면 여행객 여러분들의 승리입니다. 패자는 승자에게 100,000원을 주면 됩니다." 여행객들: "내가 하겠소."
야바위꾼A는 동전을 10번 던졌고, 앞면이 9회, 뒷면이 1회 나왔다.
야바위꾼: "제가 9점을 얻었습니다. 여행객 여러분은 제게 100,000원을 주시오." 여행객들: (돈을 던지며) "이 나쁜 사기꾼아!!"
이 상황에서도 여행객들은 화가 날 것이다. "이런 일"이 일어날 확률이 얼마 되지 않을 테니 사기를 쳤다고 확신할 것이다. 하지만 앞의 상황과는 "이런 일"의 정의가 조금 바뀌게 된다. 동전을 던지고 난 뒤 여행객들의 생각은 다음과 같을 것이다.
(동전을 던지고 난 뒤)
- "어떻게 한쪽이 9번이나 나올 수가 있어?!이 정도의 일이 일어날 확률이 얼마나 된다고?!"
- "분명 저 동전은 일반 동전이 아닐 거야.앞 면이든 뒷면이든 한쪽이 더 잘 나오도록 어떤 조치를 취해뒀을 거야."
앞의 상황(one-tailed)에서는 "앞면"이었던 것이 "한쪽"으로 바뀌었다. 누가 이기든 극단적인 양쪽(Two-tailed, two-sided)의 사건이 발생할 확률로 확인하는 것이 양측 검정이다.
P-value의 학술적인 표현
P-value는 다음과 같이 기술할 수 있다. "귀무가설이 맞다고 할 때 이런 현상이 발생했을 확률"
이 정의는 좀 날 것 그대로니 학술적인 수정을 가하면 다음과 같다. "귀무가설이 맞는 데도 불구하고, 대립 가설을 선택했을 확률"
보통 관련성이 없는 내용을 귀무가설로 설정하므로 "아무 관련성이 없는 게 학문적 진실인데, 관련성이 있다고 결론 내렸을 확률"이라고도 할 수 있다.
통계 검정으로의 적용
P-value=0.01이라고 하자.
(1) 귀무가설: 독립 변수(X)와 종속 변수(Y) 사이에 아무 관련성이 없다는 것이 사실이라고 했을 때
(2) p-value: 지금과 같은 현상이 일어날 확률은 0.01이므로 일어나기 어려운 일이다.
(3) 대립 가설: 따라서 모종의 관련성이 있다고 하자.
아무 관련성이 없다는 말은 분석 방법에 따라 다르게 표현된다.
(1) 로지스틱 회귀분석에서는 $\beta=0$ 혹은 $OR=1$으로 표현된다.
(2) 선형 회귀분석에서는 $\beta=0$으로 표현된다.
(3) Cox 회귀분석에서는 $\beta=0$ 혹은 $HR=1$으로 표현된다.
분석 방법에 따라 귀무가설이 표현되는 방법은 서로 다르다.
통계 검정으로의 적용 - 예외
다음 세 가지 분석은 다른 분석과는 다르게 귀무가설이 채택되기를 바라는 분석이다.
1) 정규성 검정 (Normality test): Shapiro-Wilk test, Kolmogorov-Smirnov test
2) Ordinal logistic regression의 proportional odds assumption 검정인 Score test
3) Cox regression의 proportional hazard assumption 검정인 Schoenfeld residual test
각 통계분석의 귀무가설은 다음과 같다.
1) 데이터가 정규성을 따른다.
2) Proportional odds assumption을 만족한다.
3) Proportional hazards assumption을 만족한다.
즉 p-value가 0.05보다 작은 경우 귀무가설을 기각할 수 있으므로 정규성을 따르지 않는다거나, proportional odds/hazard를 만족하지 않는다고 할 수 있다. 하지만 p-value가 0.05보다 큰 경우 귀무가설을 기각할 수는 없다. 하지만 이 말이 귀무가설이 맞다는 말이 아니므로 정규성을 만족한다든가, proportional odds/hazard를 만족한다고 할 수는 없는 것이다. 이 점에 유의하며 p-value를 해석해야 한다. 따라서 우리가 통계 검정을 할 때에는 귀무가설이 무엇인지, 대립 가설이 무엇인지 항상 생각해야 한다.
CrossTable(df$SEX, df$RH, prop.chisq=FALSE, fisher=TRUE,expected=TRUE, prop.r=FALSE, prop.c=FALSE, prop.t=FALSE) : df에 있는 SEX변수와 RH변수로 분할표를 만들라. 카이 제곱 기여분은 표시하지 말라 (prop.chisq=FALSE), 피셔 정확 검정은 시행하고 셀 별로 기댓값을 산출하라 (fisher=TRUE,expected=TRUE), 행백분율, 열백분율, 백분율은 산출하지 말라 (prop.r=FALSE, prop.c=FALSE, prop.t=FALSE)]
결과
'Cell Contents
|-------------------------|
| N |
| Expected N |
|-------------------------|
Total Observations in Table: 1000
| df$RH
df$SEX | 0 | 1 | Row Total |
-------------|-----------|-----------|-----------|
0 | 1 | 481 | 482 |
| 2.892 | 479.108 | |
-------------|-----------|-----------|-----------|
1 | 5 | 513 | 518 |
| 3.108 | 514.892 | |
-------------|-----------|-----------|-----------|
Column Total | 6 | 994 | 1000 |
-------------|-----------|-----------|-----------|
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 2.403963 d.f. = 1 p = 0.1210283
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 1.30126 d.f. = 1 p = 0.2539832
Fisher's Exact Test for Count Data
------------------------------------------------------------
Sample estimate odds ratio: 0.2135842
Alternative hypothesis: true odds ratio is not equal to 1
p = 0.2191681
95% confidence interval: 0.004505326 1.918452
Alternative hypothesis: true odds ratio is less than 1
p = 0.1264398
95% confidence interval: 0 1.492381
Alternative hypothesis: true odds ratio is greater than 1
p = 0.9809505
95% confidence interval: 0.009115443 Inf
Warning messages:
1: In chisq.test(t, correct = TRUE, ...) :
Chi-squared approximation may be incorrect
2: In chisq.test(t, correct = FALSE, ...) :
Chi-squared approximation may be incorrect
1) Pearson's Chi-squared test ,Pearson's Chi-squared test with Yates' continuity correction
카이 제곱 검정을 시행하는 말은 없었으나, 기댓값을 산출하라는 코드(expected=TRUE)가 있었으므로 카이 제곱 검정은 자동으로 시행한다. 하지만 맨 밑에 경고에서 볼 수 있듯이 카이 제곱 검정 결과는 사용하지 않는 게 좋다.
2) Alternative hypothesis: true odds ratio is not equal to 1 p = 0.2191681
양측 검정의 결과 p-value는 0.2192다.
3) Alternative hypothesis: true odds ratio is less than 1 p = 0.1264398
하단측 p-value는 0.1264다
4) Alternative hypothesis: true odds ratio is greater than 1 p = 0.9809505
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
우리가 봐야 할 곳은 세 번째 줄의 "p-value = 0.2192"이다. 피셔 정확 검정 결과 p-value는 0.2192로 0.05보다 크므로 "성별에 따라 RH혈액형의 분포가 다르다고 할 수 없다."라고 결론지어야 한다.
피셔 정확 검정을 구동하는 또 다른 방법이 있다. 먼저 분할표를 만든 뒤 시행하는 것이다.
freq_sex_rh<-xtabs(~SEX+RH, data=df) : xtabs()함수를 이용하여 SEX와 RH의 분할표를 만들어라. 단 데이터는 df를 사용하라. 만든 것은 freq_sex_rh에 저장하라. table_sex_rh<-table(df$SEX, df$RH) : df의 SEX와 df의 RH로 분할표를 만들어라. 만든 것은 table_sex_rh에 저장하라.
-freq_sex_rh사용한 결과
Fisher's Exact Test for Count Data
data: freq_sex_rh
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
-table_sex_rh사용한 결과
Fisher's Exact Test for Count Data
data: table_sex_rh
p-value = 0.2192
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.004505326 1.918452173
sample estimates:
odds ratio
0.2135842
#상단 측 p-value
fisher.test(df$SEX, df$RH, alternative="greater")
#하단 측 p-value
fisher.test(df$SEX, df$RH, alternative="less")
결과
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.981
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
0.009115443 Inf
sample estimates:
odds ratio
0.2135842
Fisher's Exact Test for Count Data
data: df$SEX and df$RH
p-value = 0.1264
alternative hypothesis: true odds ratio is less than 1
95 percent confidence interval:
0.000000 1.492381
sample estimates:
odds ratio
0.2135842
이전 글에서 R의 chisq.test() 함수를 사용하여 카이 제곱 검정을 하는 방법을 소개하였다(2022.08.31 - [범주형 자료 분석/R] - [R] 카이 제곱 검정 - chisq.test()). 하지만 SAS나 SPSS는 분할표와 카이 제곱 검정 결과를 같이 보여주는 데에 반해 R의 chisq.test()는 카이 제곱 검정 결과만 보여주어 불편한 감이 있다. 따라서 분할표와 카이 제곱 검정 결과를 한꺼번에 보여주는 CrossTable() 함수를 이용하여 카이 제곱 검정을 하고자 한다.
카이 제곱 검정은 범주형 변수 간에 분포의 유의미한 차이가 있는지 확인하는 방법이다. 이해할 수 있는 언어로 표현하면 다음과 같다. 분할표를 작성하였을 때 다음과 같다고 하자. (출처 및 분할표 작성법:
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 2.403963 d.f. = 1 p = 0.1210283
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 1.30126 d.f. = 1 p = 0.2539832
Warning messages:
1: In chisq.test(t, correct = TRUE, ...) :
Chi-squared approximation may be incorrect
혹시 걱정되면 "expected=TRUE" 구문을 넣어 기대 빈도를 확인해보면 된다. 이 경우 카이 제곱 검정이 자동으로 실행되므로 "chisq=TRUE"구문이 필요 없게 된다.
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
chisq.test(df$SEX, df$ALCOHOL, correct=FALSE) : df 데이터의 SEX 변수와 ALCOHOL 변수 사이의 카이 제곱 검정을 시행하라. 이때 연속성 수정은 하지 않는다.
결과
Pearson's Chi-squared test
data: df$SEX and df$ALCOHOL
X-squared = 24.389, df = 1, p-value = 7.871e-07
결과에서 중점적으로 봐야할 곳은 "p-value=7.871e-07"로 이는 "p-value가 $7.871\times10^{-7}= 0.0000007871$이다"라는 뜻이다. p-value가 0.05보다 낮으므로 성별과 음주의 분포에는 유의미한 차이가 있다고 결론내릴 수 있다.
왜 "correct=FALSE"?
R의 chisq.test() 함수는 연속성 수정을 하는 것을 디폴트 값으로 갖는다. 따라서 "correct=FALSE"라고 쓰지 않으면 "correct=TRUE"로 받아들이게 된다. 실제로 코드를 돌려보면 다음과 같다.
코드
chisq.test(df$SEX, df$ALCOHOL)
결과
Pearson's Chi-squared test with Yates' continuity correction
data: df$SEX and df$ALCOHOL
X-squared = 23.758, df = 1, p-value = 1.092e-06
보는 바와 같이 "with Yates' continuity correction"이라고 적혀있다. 즉 연속성 수정을 기본적으로 시행하게 된다. 해석 방법은 위의 일반적인 카이 제곱 검정과 같다.