[R] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - CrossTable()
이전 글에서 R로 도수분포표 및 분할표를 만드는 것이 얼마나 귀찮은 일인지 설명하였다. 이 글은 아래 글의 후속 글이므로 미리 읽고 오길 권한다.
[R] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - table(), prop.table(), xtabs(), margin.table()
[R] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - table(), prop.table(), xtabs(), margin.table() 수천 명의 정보를 포함한 데이터를 한눈에 요약하고 싶을 때가 많다...
medistat.tistory.com
이 귀찮은 일을 한꺼번에 해주는 함수로 CrossTable()이 있다. 이를 소개하고 한계점 및 일부 해결 방안을 소개한다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.29)
분석용 데이터 (update 22.08.29)
2022년 08월 29일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법 1) 엑셀 파일 2) CSV 파일 3) 코드북
medistat.tistory.com
코드를 보여드리기에 앞서 워킹 디렉토리부터 지정하겠다.
워킹 디렉토리에 관한 설명은 다음 링크된 포스트에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 라이브러리 만들기 - LIBNAME
setwd("C:/Users/user/Documents/Tistory_blog")
데이터를 불러와 df에 객체로 저장하겠다.
데이터 불러오는 방법은 다음 링크에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : EXCEL - read_excel(), read.xlsx()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 저장하기 : CSV 파일 - write.csv(), write_csv()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : SAS file (.sas7bdat) - read.sas7bdat(), read_sas()
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
CrossTable() 함수는 gmodels라는 패키지에 있으므로 패키지를 설치한다.
패키지 설치 방법은 다음 글에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 패키지 설치하기 - install.packages(), library()
install.packages("gmodels")
library("gmodels")
코드
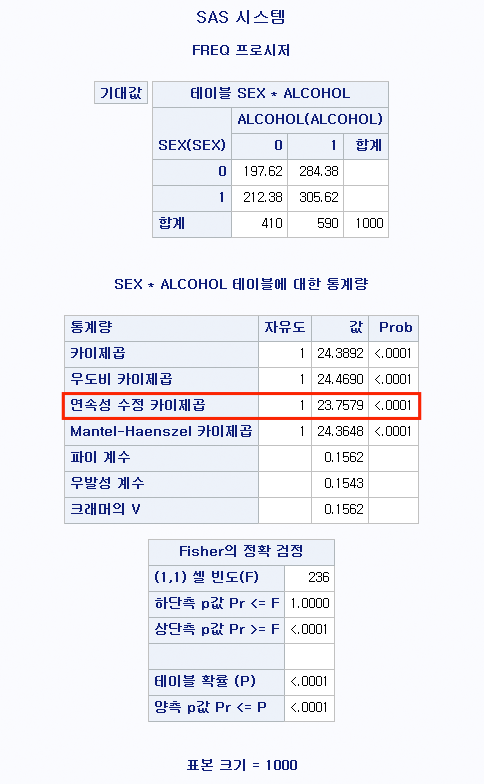
성별과 음주 여부에 대해 분할표를 작성하도록 하겠다.
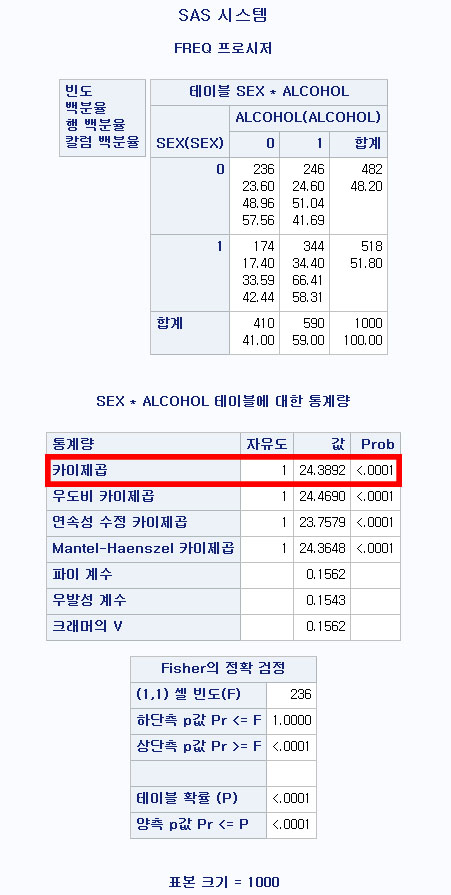
CrossTable(df$SEX, df$ALCOHOL, prop.chisq=FALSE)CrossTable(df$SEX, df$ALCOHOL, prop.chisq=FALSE) : 데이터 df에 있는 SEX와 ALCOHOL로 교차 표를 출력한다. 카이 제곱 검정 기여량은 출력하지 않는다. (백분율, 행백분율, 열백분율은 출력하는 것이 기본 설정이다.)
결과
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 1000
| df$ALCOHOL
df$SEX | 0 | 1 | Row Total |
-------------|-----------|-----------|-----------|
0 | 236 | 246 | 482 |
| 0.490 | 0.510 | 0.482 |
| 0.576 | 0.417 | |
| 0.236 | 0.246 | |
-------------|-----------|-----------|-----------|
1 | 174 | 344 | 518 |
| 0.336 | 0.664 | 0.518 |
| 0.424 | 0.583 | |
| 0.174 | 0.344 | |
-------------|-----------|-----------|-----------|
Column Total | 410 | 590 | 1000 |
| 0.410 | 0.590 | |
-------------|-----------|-----------|-----------|이전 글 (2022.08.31 - [기술 통계/R] - [R] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 - table(), prop.table(), xtabs(), margin.table())과 거의 같은 결과가 도출된다.
코드-퍼센트를 산출 및 소수점 이하 숫자 제한하고 싶을 때
CrossTable(df$SEX, df$ALCOHOL, prop.chisq=FALSE, format=c("SPSS"), digits=2)결과
Cell Contents
|-------------------------|
| Count |
| Row Percent |
| Column Percent |
| Total Percent |
|-------------------------|
Total Observations in Table: 1000
| df$ALCOHOL
df$SEX | 0 | 1 | Row Total |
-------------|-----------|-----------|-----------|
0 | 236 | 246 | 482 |
| 48.96% | 51.04% | 48.20% |
| 57.56% | 41.69% | |
| 23.60% | 24.60% | |
-------------|-----------|-----------|-----------|
1 | 174 | 344 | 518 |
| 33.59% | 66.41% | 51.80% |
| 42.44% | 58.31% | |
| 17.40% | 34.40% | |
-------------|-----------|-----------|-----------|
Column Total | 410 | 590 | 1000 |
| 41.00% | 59.00% | |
-------------|-----------|-----------|-----------|
참 강력한 툴이지만 단점이 존재한다.
1) 도수분포표의 경우 누적 도수를 산출해주지 않는다.
2) 세 개 이상의 변수를 사용한 분할표를 작성해주지 않는다.
첫 번째 단점은 해결할 수 없다.
두 번째 단점인 "세 개 이상의 변수를 사용한 분할표"는 억지로 작성할 수는 있다.
성별과 음주 여부에 관한 분할표를 고혈압 여부에 따라 작성하고자 한다고 하자. 그렇다면 고혈압이 있는 집단과 없는 집단을 미리 나눠놔야 한다.
코드
subsample_wohtn<-df[df$HTN==0,]
subsample_whtn<-df[df$HTN==1,]
CrossTable(subsample_wohtn$SEX, subsample_wohtn$ALCOHOL, prop.chisq=FALSE)
CrossTable(subsample_whtn$SEX, subsample_whtn$ALCOHOL, prop.chisq=FALSE)subsample_wohtn<-df[df$HTN==0,] : 데이터 df의 HTN변수가 0인 사람만 뽑아 "subsample_wohtn"에 저장한다.
subsample_whtn<-df[df$HTN==1,] : 데이터 df의 HTN변수가 1인 사람만 뽑아 "subsample_whtn"에 저장한다.
CrossTable(subsample_wohtn$SEX, subsample_wohtn$ALCOHOL, prop.chisq=FALSE) : HTN변수가 0인 사람들로만 성별과 음주 여부의 분할표를 작성한다.
CrossTable(subsample_whtn$SEX, subsample_whtn$ALCOHOL, prop.chisq=FALSE) : HTN변수가 1인 사람들로만 성별과 음주 여부의 분할표를 작성한다.
결과
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 503
| subsample_wohtn$ALCOHOL
subsample_wohtn$SEX | 0 | 1 | Row Total |
--------------------|-----------|-----------|-----------|
0 | 114 | 122 | 236 |
| 0.483 | 0.517 | 0.469 |
| 0.562 | 0.407 | |
| 0.227 | 0.243 | |
--------------------|-----------|-----------|-----------|
1 | 89 | 178 | 267 |
| 0.333 | 0.667 | 0.531 |
| 0.438 | 0.593 | |
| 0.177 | 0.354 | |
--------------------|-----------|-----------|-----------|
Column Total | 203 | 300 | 503 |
| 0.404 | 0.596 | |
--------------------|-----------|-----------|-----------|
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 497
| subsample_whtn$ALCOHOL
subsample_whtn$SEX | 0 | 1 | Row Total |
-------------------|-----------|-----------|-----------|
0 | 122 | 124 | 246 |
| 0.496 | 0.504 | 0.495 |
| 0.589 | 0.428 | |
| 0.245 | 0.249 | |
-------------------|-----------|-----------|-----------|
1 | 85 | 166 | 251 |
| 0.339 | 0.661 | 0.505 |
| 0.411 | 0.572 | |
| 0.171 | 0.334 | |
-------------------|-----------|-----------|-----------|
Column Total | 207 | 290 | 497 |
| 0.416 | 0.584 | |
-------------------|-----------|-----------|-----------|
[R] 도수분포표 (Frequency table), 분할표 (Contingency table) 만들기 정복 완료!
작성일: 2022.08.31.
최종 수정일: 2022.08.31.
이용 프로그램: R 4.1.3
RStudio v1.4.1717
RStudio 2021.09.1+372 "Ghost Orchid" Release
운영체제: Windows 10, Mac OS 10.15.7