이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
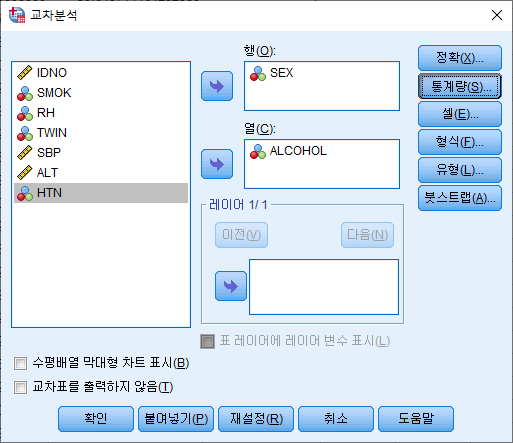
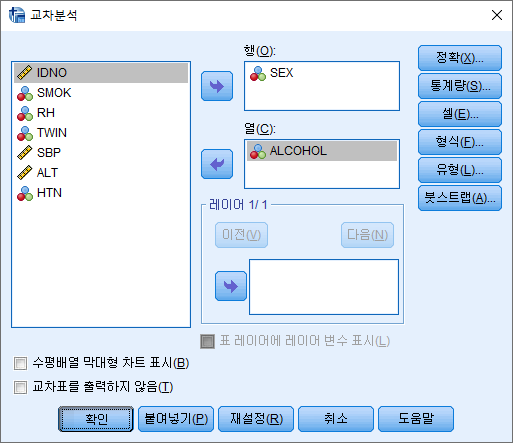
2) 행과 열에 원하는 변수를 넣어주기. 여기에서는 행에 SEX를, 열에 ALCOHOL을 넣었다. 그리고 통계량(S)를 클릭한다.
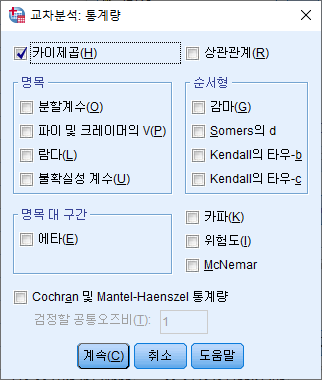
3) 카이제곱(H)의 체크박스를 선택한다. "계속(C)"버튼을 누른다.
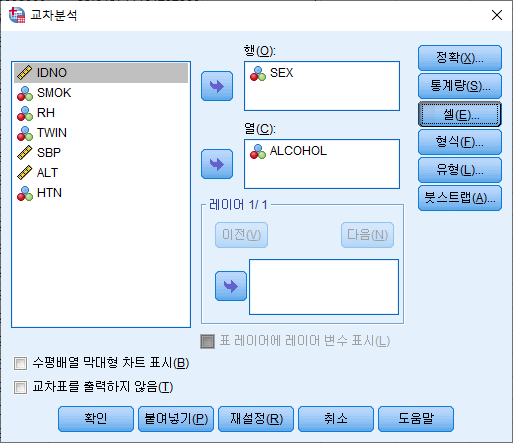
4) 셀(E)을 클릭한다.
4) 기대빈도 (E) 체크박스를 선택하고 "계속(C)"를 누른다.
5) "확인" 버튼을 눌러 결과를 확인한다.
결과
1) 기대빈도
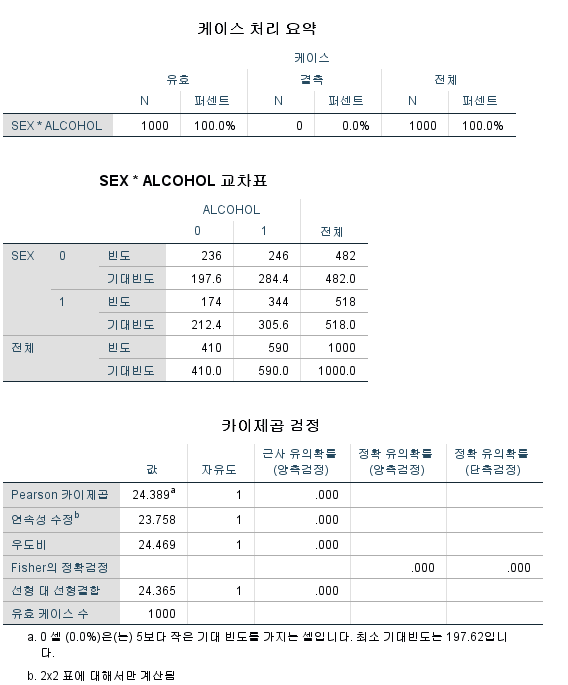
카이 제곱 검정을 시행하기 위한 전제조건은 기대 빈도가 5 미만이 셀이 전체 셀 중 25% 미만이어야 한다는 것이므로 기대 빈도를 산출해 보았고 모두 5 이상이므로 문제가 없었다.
또한, "0 셀 (0.0%)은(는) 5보다 작은 기대 빈도를 가지는 셀입니다."이라고 말하며 카이 제곱 검정을 시행해도 된다고 안심시켜주고 있다.
2) 카이 제곱 검정 결과
카이 제곱 검정의 결과를 볼 때에는 첫 번째 행 "Pearson 카이제곱"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. "0.000"이라고 쓰여있는 것은 "<0.001"을 의미한다. 따라서 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
3) 연속성 수정 카이 제곱 검정 결과 (Chi-squared test with Yates's correction for continuity)
연속성 수정을 하고 싶은 경우 두 번째 행 "연속성 수정"의 세 번째 열 "근사 유의확률 (양측검정)"을 확인해야 한다. p-value는 0.001보다 작으므로 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 데이터를 보면 남성이 음주할 확률이 더 높다고 할 수 있다.
이전 글에서 R의 chisq.test() 함수를 사용하여 카이 제곱 검정을 하는 방법을 소개하였다(2022.08.31 - [범주형 자료 분석/R] - [R] 카이 제곱 검정 - chisq.test()). 하지만 SAS나 SPSS는 분할표와 카이 제곱 검정 결과를 같이 보여주는 데에 반해 R의 chisq.test()는 카이 제곱 검정 결과만 보여주어 불편한 감이 있다. 따라서 분할표와 카이 제곱 검정 결과를 한꺼번에 보여주는 CrossTable() 함수를 이용하여 카이 제곱 검정을 하고자 한다.
카이 제곱 검정은 범주형 변수 간에 분포의 유의미한 차이가 있는지 확인하는 방법이다. 이해할 수 있는 언어로 표현하면 다음과 같다. 분할표를 작성하였을 때 다음과 같다고 하자. (출처 및 분할표 작성법:
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
Statistics for All Table Factors
Pearson's Chi-squared test
------------------------------------------------------------
Chi^2 = 2.403963 d.f. = 1 p = 0.1210283
Pearson's Chi-squared test with Yates' continuity correction
------------------------------------------------------------
Chi^2 = 1.30126 d.f. = 1 p = 0.2539832
Warning messages:
1: In chisq.test(t, correct = TRUE, ...) :
Chi-squared approximation may be incorrect
혹시 걱정되면 "expected=TRUE" 구문을 넣어 기대 빈도를 확인해보면 된다. 이 경우 카이 제곱 검정이 자동으로 실행되므로 "chisq=TRUE"구문이 필요 없게 된다.
범주형 자료 분석을 할 때 "기대 빈도가 5 미만인 셀이 25% 이상인 경우 카이 제곱 검정을 신뢰할 수 없으며 피셔 정확 검정의 결과를 확인해야 한다."라는 말을 정말 많이 보게 된다. 도대체 카이 제곱 검정과 피셔 정확 검정이 무슨 관계이길래 이렇다는 건지 궁금증이 유발될 것이다. 모든 것을 설명할 수는 없지만, 왜 이런 이야기들이 나오는지 대략적으로 설명하고자 한다.
본 글을 읽기 전에 카이 제곱 검정과 피셔 정확 검정의 이론 내용에 관한 포스트를 읽고 오기를 강력히 권한다.
먼저 이해해야 하는 것은 "왜 카이 제곱 검정을 쓰게 되었는가?"일 것이다. 결론적으로는 정확한 방법인 피셔 정확 검정 시 계산량이 너무 방대하여 그에 근사하는 카이 제곱 분포를 사용했다는 것이다.
물론 Pearson 경이 어떤 생각으로 카이 제곱 검정을 만들었는지 정확하게 알 수는 없을 뿐 아니라, 그나마 세간에 알려진 이유도 나에게는 그다지 와닿지는 않는다. 피어슨 경의 생각을 읽어보면 아마도 다음과 같을 것이다. (따라서 본 포스팅은 문헌을 리뷰하거나 참고한 것이 아니며 피어슨 입장에서 생각해본 '뇌피셜'이다.)
분포가 무엇인지 대충이라도 상상해보기
흡연과 폐암의 빈도 표가 다음과 같다고 하자.
흡연자
비흡연자
총합
폐암 환자
(A)
200
정상인
800
총합
300
700
1000
각 셀 안의 값은 정확히 모르지만 빨간색으로 표시된 총합의 값은 정확히 알려져 있다고 하자. 이때 (A)에 들어갈 수 있는 숫자는 이론적으로 0부터 200 사이의 값이다. 흡연과 폐암에 아무런 관련성이 없을 때 (A)에 들어갈 것으로 생각되는 숫자를 생각해보자. 폐암은 흡연과 관련이 없고, 전체 인구 중 흡연자는 30%를 차지하므로 폐암 환자 200명 중 30%인 60명이 있을 것으로 기대된다. 당연하게도 60명이 있을 확률이 가장 높아야 하고, 60보다 커지거나 작아질수록 그 확률은 감소해야 한다. 따라서 확률 분포 함수는 다음과 같을 것이다.
대립 가설 검정하기 <흡연자일수록 폐암환자일 가능성이 높아지는 관련성이 있다.> (One-sided, One-Tailed)
실제로 관찰 빈도가 다음과 같았다고 하자.
관찰 빈도
흡연자
비흡연자
총합
폐암 환자
75
125
200
정상인
225
575
800
총합
300
700
1000
아무런 관련성이 없었다면 폐암 환자이면서 흡연자일 것으로 예상되는 사람의 수는 60명이었는데 75명이 관찰되었으므로 흡연자일수록 폐암환자일 가능성이 높아질 것이라고 예상해볼 수 있다. 이것이 통계적으로 유의미한지 확인하는 사고 과정은 다음과 같다.
"흡연자이면서 폐암환자로 예상된 사람은 60명이었는데 75명이나 있네?"
$\rightarrow$ "이 말은 폐암과 흡연이 관련성이 있다는 것 아닐까?"
$\rightarrow$ [가정] "흡연이랑 폐암 간에 아무런 관계가 없다고 가정해보자."
$\rightarrow$ "그런 가정 하에서 흡연자이면서 폐암환자인 사람이 75명 이상일 확률이 얼마인지 구해보자."
$\rightarrow$ "그러면 차라리 흡연자일수록 폐암에 걸릴 확률이 높은 게 진실이고 그런 현실 속에서 발생한 일이라고 보는 게 낫겠다."
위 사고 구조의 비현실성: 방대한 계산량
위 사고 과정은 틀린 것이 없고 논리적이기만 하다. 하지만 피어슨(Pearson) 경이 활동했을 1900년 경에는 복잡한 계산을 순식간에 해줄 계산기가 없었기 때문에, "75명일 확률", "76명일 확률", "77명일 확률",... , "200명일 확률"을 일일이 계산한다는 것은 굉장히 귀찮고 시간이 많이 걸리지만 그에 비해 그만한 가치는 별로 없는 일이었을 것이다.
수식을 보면 정규 분포를 정의하는 데에 오직 평균($\mu$)과 표준편차($\sigma$)만이 필요하다는 것을 알 수 있다. 즉, 초기하 분포의 평균과 표준편차 (혹은 분산)를 알아내면 근사하는 정규분포를 지정할 수 있다.
(1) 평균
초기하 분포 (hypergeometric distribution)의 이산 밀도 함수 (discrete density function)은 $$f_{k} (k;K,N,n)= \frac{\begin{pmatrix} K \\ k \end{pmatrix} \times \begin{pmatrix} N-K \\ n-k \end{pmatrix}} {\begin{pmatrix} N \\ n \end{pmatrix}}$$ 이므로 평균($\mu$)은 다음과 같이 구할 수 있다.
다른 방법으로는 factorial moment를 사용하여 $[E(X(X-1))]$을 구하는 방법도 있다. 수식이 조금 더 간단해진다.
따라서 흡연자이면서 폐암 환자인 사람의 수는 평균이 $\frac {Kn} {N} $, 분산이 $n \cdot \frac {K} {N} \frac {N-K} {N} \frac {N-n} {N-1} $인 정규분포를 따른다고 할 수 있다.
정규 분포가 아닌 카이 제곱 분포를 사용하자
피어슨 경은 이 정규 분포를 바로 사용하는 것이 아니라 카이 제곱 분포를 사용하고자 했다. 이런 2*2 분할표 (contingency table)에서는 정규 분포를 쓰든 카이 제곱 분포를 쓰든 아무 상관이 없겠지만 표가 더 커지면 문제가 발생하기 마련이다.
<2*2 분할표>
범주1(1)
범주1(2)
합계
범주2(1)
(A)
범주2(2)
합계
<3*3 분할표>
범주1(1)
범주1(2)
범주1(3)
합계
범주2(1)
(ㄱ)
(ㄴ)
범주2(2)
(ㄷ)
(ㄹ)
범주2(3)
합계
2*2 분할표에서는 자유도가 1이므로 한 개의 값만 지정하면 되지만, 3*3 분할표만 되어도 자유도가 4이므로 자유롭게 정할 수 있는 값이 4개가 된다. 이런 경우 정규 분포를 바로 사용할 수 없다. 따라서 정규분포를 사용하지만 자유도의 개념이 있는 카이 제곱 분포를 사용하고자 했을 것이다.
설명을 용이하게 하기 위해 2*2 분할표로 설명을 이어가도록 하겠다. 흡연자이면서 폐암 환자인 사람의 수($X$)를 표준화한 뒤 제곱해주면 카이 제곱 분포를 따른다고 할 수 있다. 평균이 $\frac {Kn} {N} $, 분산이 $n \cdot \frac {K} {N} \frac {N-K} {N} \frac {N-n} {N-1} $이므로
이때 $N$이 굉장히 크면 $N\sim \left(N-1\right)$이므로 $(1)$식은 $$\frac{\left(X-\frac {Kn} {N}\right)^2}{ n \cdot \frac {K \cdot (N-K) \cdot(N-n)} {N^3}}\sim \chi^2(1) \tag{2}$$
에 근사 시킬 수 있다.
수식을 정리해보자
한편 수식$(2)$에서 쓰인 문자들은 표에서 다음과 같이 나타난다.
관찰 빈도
흡연자
비흡연자
총합
폐암 환자
$a_{11}=X$
$a_{12}=n-X$
$n$
정상인
$a_{21}=K-X$
$a_{22}=N-K-n+X$
$N-n$
총합
$K$
$N-K$
$N$
수식$(2)$을 어떻게 잘 정리해야 세상에 잘 먹힐지 피어슨 경은 고민이 많았을 것이다. 저 식은 너무 복잡해서 일반적인 연구자가 쓰기엔 복잡할 뿐만 아니라 쓰고 싶지 않게 생겼기 때문이다. 피어슨 경은 뛰어난 직관으로 해결했을 수도 있지만 나에게는 다음과 같이 계산되는 결과가 매력적으로 느껴졌다.
먼저 기대 빈도를 구하면 다음과 같다.
기대 빈도
흡연자
비흡연자
총합
폐암 환자
$$e_{11}=\frac {Kn} {N}$$
$$e_{12}=\frac {(N-K)n} {N}$$
$n$
정상인
$$e_{21}=\frac {K(N-n)} {N}$$
$$e_{22}=\frac {(N-K)(N-n)} {N}$$
$N-n$
총합
$K$
$N-K$
$N$
관찰 빈도에서 기대 빈도를 뺀 뒤 제곱한 값은 놀랍게도 모든 셀에서 같다. (사실 자유도가 1이므로 당연한 현상이긴 하다.)
게다가 이 값은 수식$(2)$인 $\frac{\left(X-\frac {Kn} {N}\right)^2}{ n \cdot \frac {K \cdot (N-K) \cdot(N-n)} {N^3}}$의 분자에 해당하는 내용이다. 따라서 이 수식은 다음과 같이 바꿔보고 싶은 욕구가 차오른다.
이제 정확한 초기하 분포의 확률을 구하기 위해 $1000!$같은 무식한 계산을 하지 않아도 된다. $2*2$ 분할표라면 관찰 빈도와 기대 빈도로 계산한 $(3)$ 식의 값이 3.84를 넘기만 하다면 분포에 통계적으로 유의한 차이가 있다고 양측 검정 (Two-tailed or two-sided)을 한 셈이니 말이다. (3.84는 자유도가 1인 카이 제곱 분포의 누적 확률이 0.95가 되는 지점이다.) $m*n$ 분할표일 때에도 식 $(3)$과 비슷하게 계산을 먼저 하고 그 값이 카이 제곱 분포표에서 자유도 $(m-1)\times(n-1)$일 때 $\alpha=0.05$인 지점보다 큰지만 확인하면 된다.
이를 보면 비음주자 중에는 여성이 많고, 음주자 중에는 남성이 많다. 그렇다면 "성별과 음주 여부는 무관하다(=독립이다)."라는 말이 틀리다고 할 수 있을까? 즉, "특정 성별은 음주자일 확률이 더 높다."라고 할 수 있을까? 이에 대한 검정이 바로 카이 제곱 검정이다.
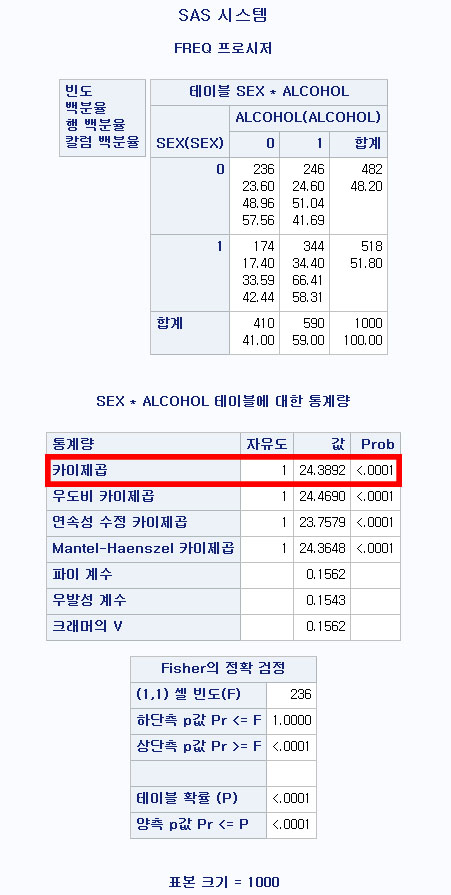
PROC FREQ DATA=hong.df; : 빈도수를 계산하는 코드를 시작하며, 데이터는 hong 라이브러리의 df 파일을 이용한다. TABLE SEX*ALCOHOL/CHISQ; : SEX와 ALCOHOL의 분할표를 계산하며, 카이 제곱 검정을 시행한다.
분할표를 작성하는 코드와 거의 똑같고, TABLE 구문에 옵션으로 "CHISQ"가 추가된 것만이 다르다.
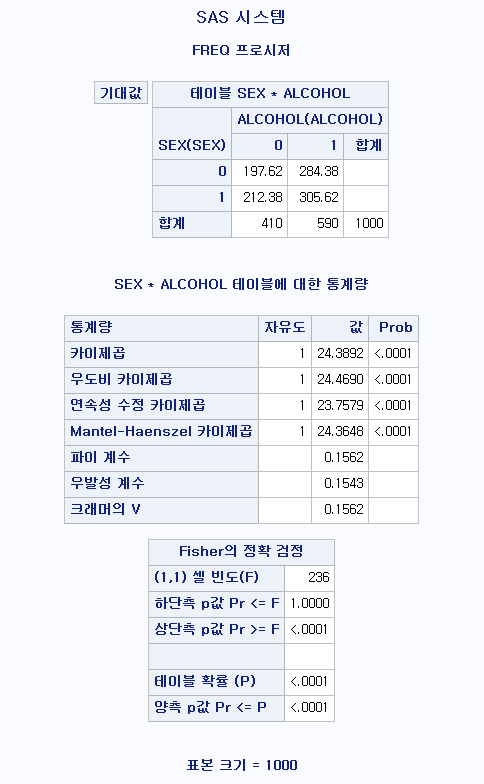
결과
많은 값들이 산출되지만 봐야 할 것은 카이제곱 검정량이다. 카이 제곱 검정량은 24.3892이며, 자유도가 1인 카이제곱 분포에서 이런 일이 발생할 확률은 0.0001 미만이다. 따라서 유의성 기준을 0.05로 잡았을 때, 성별과 음주 여부는 독립이 아니라고 할 수 있으며, 남성이 음주할 확률이 더 높다고 할 수 있다.
이 해석을 할 때에, 빈도, 백분율, 행 백분율, 칼럼 백분율은 사실 필요가 없다. 따라서 이 지표들을 산출하지 않기 위해 옵션으로 TABLE구문에 NOFREQ NOPERCENT NOROW NOCOL를 추가하기도 한다. 또한, 카이 제곱 검정을 시행하기 위한 전제조건은 기대 빈도가 5 미만이 셀이 전체 셀 중 25% 미만이어야 한다는 것이므로 기대 빈도를 확인해볼 수 있는 옵션인 EXPECTED를 추가하기도 한다.