[R] 고급 Q-Q Plot - Van der Waerden, Rankit, Tukey, Blom
다음 글을 읽고 와야 이해하기 편하므로 먼저 읽고 올 것을 권한다.
2022.08.12 - [통계 이론] - [이론] Q-Q Plot (Quantile-Quantile Plot)
[이론] Q-Q Plot (Quantile-Quantile Plot)
[이론] Q-Q Plot (Quantile-Quantile Plot) 정규성을 검정할 때 Q-Q Plot을 쓰곤 한다. 그런데 이런 궁금증이 들 수 있다. 왜 Q-Q Plot이 직선에 가까운 것이 정규성을 따른다는 뜻인가? 이에 대해 조목조목..
medistat.tistory.com
Q-Q Plot의 이론에서 상대적 위치를 대칭적으로 정하는 방법이 여럿 있다고 언급했다. 본 글에서는 R에서 권하는 방법이 아니라, 특정 방법을 지정하여 Q-Q Plot을 그리는 법에 대해 소개하겠다.
코드를 보여드리기에 앞서 워킹 디렉토리부터 지정하겠다.
워킹 디렉토리에 관한 설명은 다음 링크된 포스트에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 작업 디렉토리 (Working Directory) 지정 - getwd(), setwd()
setwd("C:/Users/user/Documents/Tistory_blog")*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.08.10)
분석용 데이터 (update 22.08.11)
2022년 08월 11일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 통계 프로그램 사용 방법
medistat.tistory.com
데이터를 불러와 a에 객체로 저장하겠다.
데이터 불러오는 방법은 다음 링크에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : EXCEL - read_excel(), read.xlsx()
2022.08.08 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : CSV - read_csv(), read.csv(), fread()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : SAS file (.sas7bdat) - read.sas7bdat(), read_sas()
install.packages("readr")
library("readr")
a<-read_csv("Data.csv")
1) Van der Waerden 방법
Van der Waerden방법은 kn+1이라는 수식을 사용한다.
코드
ALT_Data<-sort(a$ALT)
QQ_Van<-(c(1:length(ALT_Data)))/(length(ALT_Data)+1)
Z_Van<-qnorm(QQ_Van,0,1)
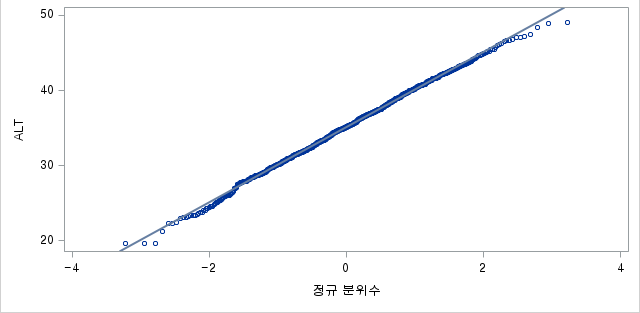
plot(Z_Van,ALT_Data)ALT_Data<-sort(a$ALT) : a라는 데이터셋의 ALT 변수를 가져와 오름차순으로 정렬하여 ALT_Data에 저장한다.
QQ_Van<-(c(1:length(ALT_Data)))/(length(ALT_Data)+1) : Van der Waerden 수식의 n에 해당하는 데이터셋의 수를 의미한다. 우리 데이터에는 1,000명의 정보가 있으므로, 이는 1,000와 같다.
QQ_Van<-(c(1:length(ALT_Data)))/(length(ALT_Data)+1) : 1부터 1,000까지 1,001로 나누어 이를 QQ1에 저장한다.
Z_Van<-qnorm(QQ_Van,0,1) : 정규분포 상 −∞부터 적분했을 때 QQ1의 각 값과 같아지는 Z값들을 구해 Z1에 저장한다.
plot(Z_Van,ALT_Data) : Z1과 ALT_Data로 plot을 그린다.
결과
2) Rankit 방법
Rankit 방법은 k−12n이라는 수식을 사용한다.
코드
ALT_Data<-sort(a$ALT)
QQ_Rankit<-(c(1:length(ALT_Data))-1/2)/length(ALT_Data)
Z_Rankit<-qnorm(QQ_Rankit,0,1)
plot(Z_Rankit,ALT_Data)결과
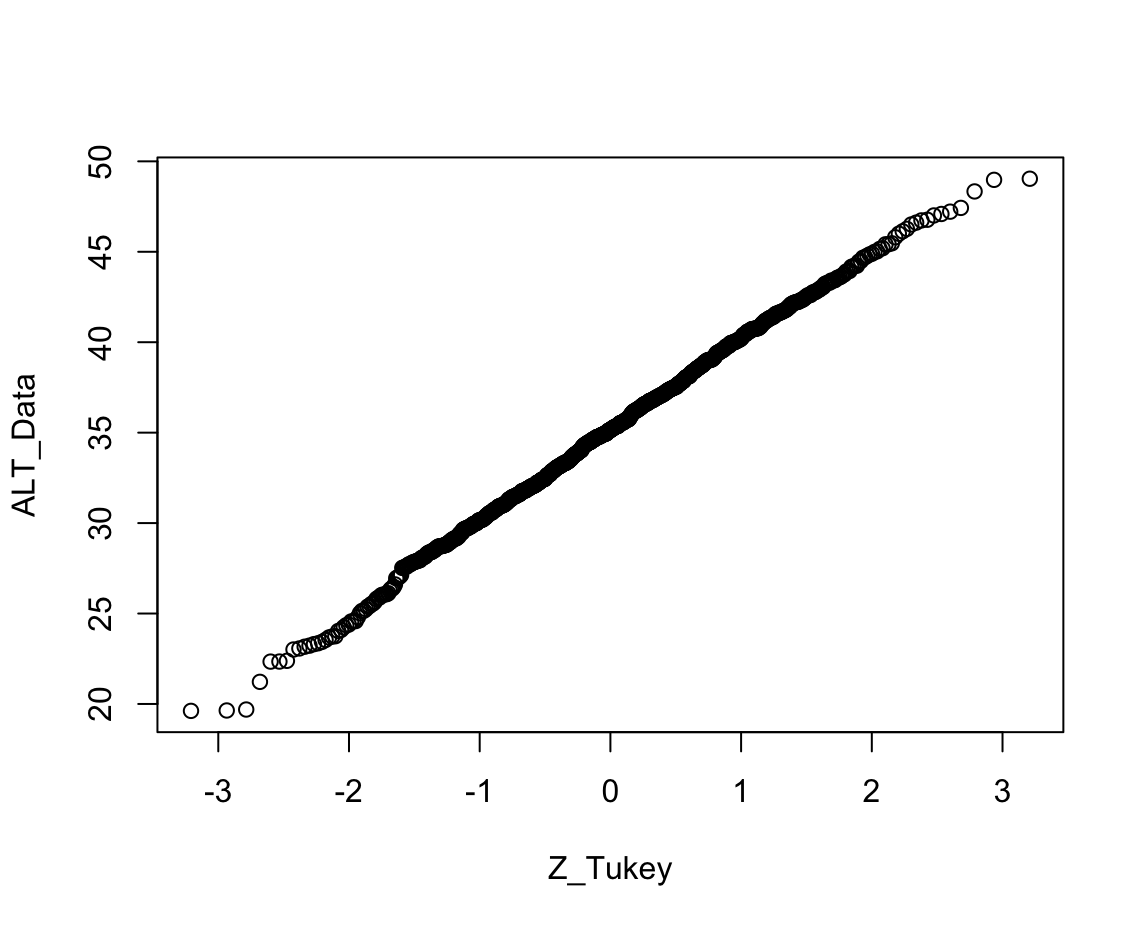
3) Tukey 방법
Tukey 방법은 k−13n+13이라는 수식을 사용한다.
코드
ALT_Data<-sort(a$ALT)
QQ_Tukey<-(c(1:length(ALT_Data))-1/3)/(length(ALT_Data)+1/3)
Z_Tukey<-qnorm(QQ_Tukey,0,1)
plot(Z_Tukey,ALT_Data)결과
4) Blom 방법
Blom 방법은 k−38n+14이라는 수식을 사용한다.
코드
ALT_Data<-sort(a$ALT)
QQ_Blom<-(c(1:length(ALT_Data))-3/8)/(length(ALT_Data)+1/4)
Z_Blom<-qnorm(QQ_Blom,0,1)
plot(Z_Blom,ALT_Data)결과
지금까지의 결과를 보면 알겠지만, 그림의 차이를 찾아볼 수 없을 정도로 거의 동일하다. 이렇게 n수가 충분하면 어떤 방법을 고르든 거의 똑같은 결과를 내주므로 적용할 방법에 대해 크게 연연할 필요가 없다.
[R] 고급 Q-Q Plot 정복 완료!
작성일: 2022.08.16.
최종 수정일: 2022.08.16.
이용 프로그램: R 4.1.3
RStudio v1.4.1717
RStudio 2021.09.1+372 "Ghost Orchid" Release
운영체제: Windows 10, Mac OS 10.15.7