[이론] 피셔 정확 검정 (Fisher's exact test)
범주형 자료의 통계 분석을 진행하다 보면 반드시 만나게 되는 검정이 피셔 정확 검정이다. 피셔 정확 검정은 단순히 초기하 분포의 확률을 구하는 것이다. 이해할 수 있는 언어로 표현하면 다음과 같다.
초기하 분포 (Hypergeometric distritubion)
먼저 초기하 분포를 이해해야 한다.
상황: 10개의 공이 들어있는 주머니가 있다. 그중 7개는 파란색, 3개는 빨간색이다.
전제: 특정 색깔의 공이 더 잘 뽑히는 것은 아니다. 어떤 색이 뽑힐지는 랜덤이다. (=뽑는 사람은 공을 보지 않고서는 색을 알 수 없다 = 독립이다.)
문제: 5개의 공을 꺼냈는데, 3개가 파란색, 2개가 빨간색일 확률은 얼마인가?
답:
$$\frac{_{7}C_{3}\times _{3}C_{2}}{_{10}C_{5}} = \frac{\begin{pmatrix} 7 \\ 3 \end{pmatrix} \times \begin{pmatrix} 3 \\ 2 \end{pmatrix}} {\begin{pmatrix} 10 \\ 5 \end{pmatrix}}$$
해설:
분모에는 10개 공 중에서 5개를 고르는 경우의 수인 $_{10}C_{5}$을 넣는다.
분자에는 파란 공 7개 중 3개를 고르는 경우의 수인 $_{7}C_{3}$과 빨간 공 3개 중 2개를 고르는 $_{3}C_{2}$를 곱한다.
즉, $N$개 중 $n$개를 고르는데, 음이 아닌 어떤 정수 $k$에 대해, $k$개는 $K$중에서, $n-k$개는 $N-K$개에서 고르는 경우에 대해 논하는 것이 초기하 분포다. 그리고 확률 밀도 함수(discrete density function, 혹은 probability mass function)는 다음과 같이 기술된다.
$$f_{k} (k;K,N,n)=\frac{_{K}C_{k}\times _{N-K}C_{n-k}}{_{N}C_{n}} = \frac{\begin{pmatrix} K \\ k \end{pmatrix} \times \begin{pmatrix} N-K \\ n-k \end{pmatrix}} {\begin{pmatrix} N \\ n \end{pmatrix}}$$
말이 어려워 보일지 몰라도 위 문제에 대한 해설을 일반화한 것뿐이다.
피셔 정확 검정 (Fisher's exact test)은 어떻게 하는 건데?
피셔 정확 검정 결과를 직접 손으로 계산해보고자 한다.
성별과 RH 혈액형 분포가 다음과 같다고 하자.
| RH- | RH+ | 합계 | |
| 여성 | 1 | 481 | 482 |
| 남성 | 5 | 513 | 518 |
| 합계 | 6 | 994 | 1000 |
다음 두 가지를 유의하며 읽어야 한다.
1) 먼저, 카이 제곱 검정 때와 마찬가지로 합계에 있는 파란색 숫자들은 변하지 않는 고정값으로 볼 것이다.
2) 우리는 빨간색 숫자인 여성이면서 RH-인 사람의 수에 집중할 것이다.
여성은 482명, RH-는 6명이므로 빨간색 숫자가 있는 칸에는 이론적으로 0부터 6(482와 6중 작은 숫자)까지의 숫자가 들어갈 수 있다. 만약 0이라면, RH- 6명 중 전원이 남성인 것이므로 "남성에 RH-가 많다."라고 이야기할 수도 있을 것이다. 반대로 6이라면 RH- 6명 중 전원이 여성이므로 "여성에 RH-가 많다."라고 이야기할 수도 있을 것이다.
본 글의 최종 목적이 되는 양측 검정 (two-sided, two-tailed) 귀무가설은 "성별과 RH 혈액형은 관련성이 없다."이므로 빨간색 숫자가 있는 칸에 들어가는 숫자가 작아서 0에 가까워지거나 커서 6에 가까워지는 상황에서는 p-value가 작아지도록 통계량이 설계되어야 한다.
위에서 공부한 초기하 분포의 확률을 본 상황에 대입하면 다음과 같다.
전제되는 상황: 특정 성별이 특정 RH 혈액형을 가질 가능성이 더 높지 않다. 즉 독립적이다.
"총 인원 1,000명 중 RH- 6명을 고를 건데, 1명은 여성 482명 중에서, 나머지 5명은 남성 518명 중에서 고를 것이다. 그렇게 계산될 확률은 얼마인가?"
초기하 분포의 확률 공식을 사용하여 위 문제의 답은 다음과 같이 구할 수 있다.
$$ \frac{\begin{pmatrix} 482 \\ 1 \end{pmatrix} \times \begin{pmatrix} 518 \\ 5 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.10739...$$
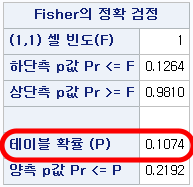
이 값이 SAS 결과에서는 "테이블 확률(P)"로 제시된다. 본 테이블이 계산될 확률을 의미한다.
사실 피셔 정확 검정에서는 여러 대립 가설이 있을 수 있다. 각 상황에 따라 피셔 정확 검정의 결과를 계산해보고자 한다.
대립 가설 1) 여성일수록 RH-일 가능성이 높아지는 관련성이 있다. (One-sided, One-Tailed)
그렇다면 우리가 구하고자 하는 p-value의 의미는 다음과 같다.
"성별과 RH 혈액형 사이에는 관련성이 없다는 것이 진실인데 여성일수록 RH-일 가능성이 높아지는 관련성이 있다고 결론을 내릴 확률"
우리 데이터를 보면 RH-인 6명 중 5명이 남성에 쏠려있으므로 이 상황에서 구해지는 p-value는 높은 값을 갖는 것이 합리적이다. 그리고 그 계산은 다음 확률을 모두 더해서 계산한다.
(1) 여성이면서 RH-인 사람이 1명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 1 \end{pmatrix} \times \begin{pmatrix} 518 \\ 5 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(2) 여성이면서 RH-인 사람이 2명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 2 \end{pmatrix} \times \begin{pmatrix} 518 \\ 4 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(3) 여성이면서 RH-인 사람이 3명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 3 \end{pmatrix} \times \begin{pmatrix} 518 \\ 3 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(4) 여성이면서 RH-인 사람이 4명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 4\end{pmatrix} \times \begin{pmatrix} 518 \\ 2 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(5) 여성이면서 RH-인 사람이 5명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 5 \end{pmatrix} \times \begin{pmatrix} 518 \\ 1 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(6) 여성이면서 RH-인 사람이 6명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 6 \end{pmatrix} \times \begin{pmatrix} 518 \\ 0 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
이 값을 모두 더하면, 즉 $$\sum_{k=1}^{6} { \frac{\begin{pmatrix} 482 \\ k \end{pmatrix} \times \begin{pmatrix} 518 \\ 6-k \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}}=0.98085...$$
가 되어 SAS 결과에서의 "상단측 p값 Pr>=F"값이 산출된다.
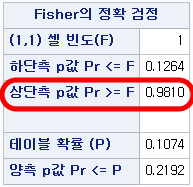
(1) 여성이면서 RH-인 사람의 수는 1이다. 이를 F라 칭한다.
(2) 여성이면서 RH-인 사람의 수가 F 이상인 확률들의 총합을 "상단측 p값 Pr>=F"라고 한다.
만약 유의성의 기준 ($\alpha$)이 0.3였다면 다음과 같이 해석된다.
성별과 RH혈액형 사이에 관련성이 없다는 것이 진실이라고 가정하자. 이때 RH- 환자 6명 중 한 명 이상이 여성일 확률은 0.9810다. 이건 0.3보다도 높으므로 현실적으로 일어날 수 있는 일이다. 따라서 여성일수록 RH- 혈액형을 가질 것이라고는 할 수 없다고 결론지어진다.
대립 가설 2) 여성일수록 RH-일 가능성이 낮아지는 관련성이 있다. (One-sided, One-Tailed)
그렇다면 우리가 구하고자 하는 p-value의 의미는 다음과 같다.
"성별과 RH 혈액형 사이에는 관련성이 없다는 것이 진실인데 여성일수록 RH-일 가능성이 낮아지는 관련성이 있다고 결론을 내릴 확률"
우리 데이터를 보면 RH-인 6명 중 1명만이 여성이므로 이 상황에서 구해지는 p-value는 상대적으로 낮은 값을 갖는 것이 합리적이다. 그리고 그 계산은 다음 확률을 모두 더해서 계산한다.
(1) 여성이면서 RH-인 사람이 0명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 0 \end{pmatrix} \times \begin{pmatrix} 518 \\ 6 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
(2) 여성이면서 RH-인 사람이 1명일 확률 :$ \frac{\begin{pmatrix} 482 \\ 1 \end{pmatrix} \times \begin{pmatrix} 518 \\ 5 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}$
이 값을 모두 더하면, 즉 $$\sum_{k=0}^{1} { \frac{\begin{pmatrix} 482 \\ k \end{pmatrix} \times \begin{pmatrix} 518 \\ 6-k \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}}=0.12644...$$
가 되어 SAS 결과에서의 "하단측 p값 Pr>=F"값이 산출된다.
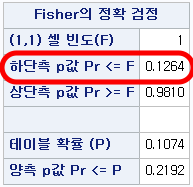
(1) 여성이면서 RH-인 사람의 수는 1이다. 이를 F라 칭한다.
(2) 여성이면서 RH-인 사람의 수가 F 이하인 확률들의 총합을 "하단측 p값 Pr<=F"라고 한다.
만약 유의성의 기준 ($\alpha$)이 0.3였다면 다음과 같이 해석된다.
성별과 RH혈액형 사이에 관련성이 없다는 것이 진실이라고 가정하자. 이때 RH- 환자 6명 중 한 명 이하만이 여성일 확률은 0.1264다. 이 값은 0.3보다도 낮으므로 이렇게 적은 숫자의 여성이 RH-혈액형을 갖는 것은 현실적으로 일어나기 어려운 일이다. 그러므로 성별과 RH혈액형 사이에 관련성이 없다고 봤던 가정에 문제가 있다고 할 수 있다. 따라서 차라리 여성일수록 RH-혈액형일 가능성이 떨어진다고 보는 것이 합리적이다.
즉 사고의 흐름은 다음과 같다.
"RH-인 사람 중 여성이 1명밖에 안되네?"
$\rightarrow$ "1명 혹은 0명 밖에 없다는 것은 여성일수록 RH-일 가능성이 떨어진다는 것 아닐까?"
$\rightarrow$ [가정] "성별이랑 RH혈액형 간에 아무런 관계가 없다고 가정해보자."
$\rightarrow$ "그때 RH-중 1명 혹은 0명만이 여성일 확률이 얼마라고? 0.1264라고."
$\rightarrow$ "이게 현실적으로 일어나기는 어려운 일 아니야?"
$\rightarrow$ "그러면 차라리 여성일수록 RH-일 확률이 높은 게 진실이고 그런 현실 속에서 발생한 일이라고 보는 게 낫겠다."
대립 가설 3) 성별과 RH 혈액형 사이에는 모종의 관련성이 있다. (Two-sided, Two-Tailed)
그렇다면 우리가 구하고자 하는 p-value의 의미는 다음과 같다.
"성별과 RH 혈액형 사이에는 관련성이 없다는 것이 진실인데 여성일수록 RH-일 가능성이 높아지거나 낮아지는 관련성이 있다고 결론을 내릴 확률"
모종의 관련성이 있다면 여성이면서 RH-인 사람의 수는 극도로 작아지거나 커질 것이다. 여기에서는 그 수가 1이다. 1이 될 확률은 위에서 0.1074로 산출이 되었다. 그 확률보다 작은 경우는 여성이면서 RH-인 사람의 수가 1보다 적거나, 6에 가까운 경우일 뿐일 것이다. 그 확률들의 총합이 피셔 정확 검정의 양측 검정 p-value이다.
| 여성 & RH-인 사람의 수 | 초기하 분포에 따른 확률 (A) | (A)가 테이블 확률보다 작은가? |
| 0 | $ \frac{\begin{pmatrix} 482 \\ 0 \end{pmatrix} \times \begin{pmatrix} 518 \\ 6 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.01905$ | Yes |
| 1 | $ \frac{\begin{pmatrix} 482 \\ 1 \end{pmatrix} \times \begin{pmatrix} 518 \\ 5 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.10739$ | Yes |
| 2 | $ \frac{\begin{pmatrix} 482 \\ 2 \end{pmatrix} \times \begin{pmatrix} 518 \\ 4 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.25124$ | No |
| 3 | $ \frac{\begin{pmatrix} 482 \\ 3 \end{pmatrix} \times \begin{pmatrix} 518 \\ 3 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.31222$ | No |
| 4 | $ \frac{\begin{pmatrix} 482 \\ 4 \end{pmatrix} \times \begin{pmatrix} 518 \\ 2 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.21737$ | No |
| 5 | $ \frac{\begin{pmatrix} 482 \\ 5 \end{pmatrix} \times \begin{pmatrix} 518 \\ 1 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.08039$ | Yes |
| 6 | $ \frac{\begin{pmatrix} 482 \\ 6 \end{pmatrix} \times \begin{pmatrix} 518 \\ 0 \end{pmatrix}} {\begin{pmatrix} 1000 \\ 6 \end{pmatrix}}=0.01234$ | Yes |
Yes에 해당하는 사람들의 확률을 모두 더하면 $0.21917$이 계산되며 이는 SAS 결과에서의 "양측 p값 Pr>=P"와 같다. 또한, 이 값이 보통 논문에서 사용되는 피셔 정확 검정의 값이다.
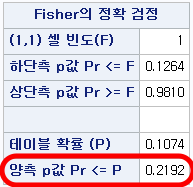
만약 유의성의 기준 ($\alpha$)이 0.3였다면 다음과 같이 해석된다.
성별과 RH혈액형 사이에 관련성이 없다는 것이 진실이라고 가정하자. 이때 RH- 환자 6명 중 한 명만이 여성일 확률은 0.1074다. 이 확률보다 일어나기 어려운 현상은 RH-인 여성이 0명인 상황, 5명인 상황, 6명인 상황이다. 이런 일들이 일어날 확률은 0.2192다. 이건 0.3보다도 낮으므로 현실적으로 일어나기 어렵다. 즉, 성별과 RH혈액형 사이에 관련성이 없다고 봤던 가정에 문제가 있다고 할 수 있다. 따라서 차라리 여성일수록 RH-혈액형일 가능성이 높아지거나 낮아지는 것이 진실이라고 보는 것이 합리적이다.
세 가지 p-value 중 어떤 값을 써야 하는가?
피셔 정확 검정의 p-value는 아무 거나 쓰는 것이 아니다. 어떤 대립 가설을 사용하는지에 따라 크게 달라진다.
1) 상단측 p값 Pr>=F : 분할표의 대각선에 많은 데이터가 몰릴 것으로 예상될 때 사용한다. 만약 변수가 순서형 변수라면 크기순으로 행과 열을 채우니 일반적으로 양의 상관관계가 예상될 때 사용한다고 할 수 있다.
2) 하단측 p값 Pr<=F : 분할표의 대각선에 외의 셀에 많은 데이터가 몰릴 것으로 예상될 때 사용한다. 만약 변수가 순서형 변수라면 크기순으로 행과 열을 채우니 일반적으로 음의 상관관계가 예상될 때 사용한다고 할 수 있다.
3) 양측 p값 Pr<=P : 대립 가설이 없을 때 사용한다. 즉, 어느 방향으로든 관련성이 있는지 보고자 할 때 사용하는 값이다.
[이론] 피셔 정확 검정 (Fisher's exact test) 정복 완료!
작성일: 2022.08.26.
최종 수정일: 2022.08.27.
이용 프로그램: SAS v9.4
운영체제: Windows 10
'통계 이론' 카테고리의 다른 글
| [이론] p-value에 관한 고찰 (0) | 2022.09.05 |
|---|---|
| [이론] 연속성을 수정한 카이 제곱 검정 (Chi-squared test with Yates's correction for continuity) (0) | 2022.08.30 |
| [이론] 카이 제곱 검정과 피셔 정확 검정의 관계 (0) | 2022.08.29 |
| [이론] 카이 제곱 검정 (Chi-squared test) (3) | 2022.08.16 |
| [이론] Q-Q Plot (Quantile-Quantile Plot) (0) | 2022.08.12 |