
[R] 단순 선형 회귀 분석 (Simple linear regression) - lm()
지난 상관관계 분석에서 우리는 서로 다른 두 변수가 얼마나 관련되어 있는지를 알아보았다. 즉, 한 변수의 값으로 다른 변수의 값을 예측할 수 있는 정도인 "예측도"의 관점에서 상관 계수를 이해하였다.(2022.12.15 - [상관분석/R] - [R] 피어슨 상관 계수 (Pearson's correlation coefficient) - cor.test()) 그런데, 상관 계수의 단점은 "예측도"만 확인할 수 있을 뿐, 실제로 예측을 할 수는 없다. 가령, 수축기 혈압(SBP)이 120인 사람의 심혈관 질환 위험 점수 (CVD_RISK)가 얼마인지는 알 수 없는 것이다. 이걸 가능하게 하는 것이 선형 회귀 분석 (linear regression)이다. 본 포스팅에서는 독립 변수가 1개인 단순 선형 회귀 분석 (simple linear regression)을 시행해보도록 하겠다. 이는 독립 변수가 1개라는 점에서 univariate linear regression이라고도 부른다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.12.18)
분석용 데이터 (update 22.12.18)
2022년 12월 18일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 범주형 자료 분석 - 모평균 검정 - 상관분석 - 반복 측정 자료
medistat.tistory.com
코드를 보여드리기에 앞서 워킹 디렉토리부터 지정하겠다.
워킹 디렉토리에 관한 설명은 다음 링크된 포스트에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 작업 디렉토리 (Working Directory) 지정 - getwd(), setwd()
setwd("C:/Users/user/Documents/Tistory_blog")
데이터를 불러와 df에 객체로 저장하겠다.
데이터 불러오는 방법은 다음 링크에서 볼 수 있다.
2022.08.05 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : EXCEL - read_excel(), read.xlsx()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 저장하기 : CSV 파일 - write.csv(), write_csv()
2022.08.10 - [통계 프로그램 사용 방법/R] - [R] 데이터 불러오기 : SAS file (.sas7bdat) - read.sas7bdat(), read_sas()
install.packages("readr")
library("readr")
df<-read_csv("Data.csv")
목표: 수축기 혈압(SBP)으로 심혈관 질환 위험 점수 (CVD_RISK)를 예측할 수 있는가?
선형 회귀 분석은 lm()이라는 함수를 사용한다.
코드
LR_SBP_CVD<-lm(CVD_RISK~SBP, data=df)
summary(LR_SBP_CVD)LR_SBP_CVD<-lm(CVD_RISK~SBP, data=df) : 데이터는 df를 사용한다. 독립변수를 SBP로, 종속변수를 CVD_RISK로 하는 선형 회귀 분석을 시행하고 이 결과를 LR_SBP_CVD에 저장하라.
summary(LR_SBP_CVD) : LR_SBP_CVD의 내용을 요약해서 보여달라.
결과
Call:
lm(formula = CVD_RISK ~ SBP, data = df)
Residuals:
Min 1Q Median 3Q Max
-16.6754 -3.6753 0.0733 3.4071 15.9155
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 23.036415 1.233590 18.67 <2e-16 ***
SBP 1.101935 0.009055 121.69 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 5.176 on 998 degrees of freedom
Multiple R-squared: 0.9369, Adjusted R-squared: 0.9368
F-statistic: 1.481e+04 on 1 and 998 DF, p-value: < 2.2e-16하나씩 살펴보도록 하자.
Call: lm(formula = CVD_RISK ~ SBP, data = df)
: 당신이 요청한 분석은, 데이터는 df를, 종속변수는 CVD_RISK를, 독립변수는 SBP를 사용하는 선형 회귀 분석이다.
Residuals: Min 1Q Median 3Q Max
-16.6754 -3.6753 0.0733 3.4071 15.9155
: 잔차의 최솟값은 -16.6754, 중앙값은 0.0733, 최댓값은 15.9155다.
잔차는 실제 관측값에서 예측값을 뺀 것이고, 예측값을 계산하는 방법은 아래에 나올 것이다.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 23.036415 1.233590 18.67 <2e-16 ***
SBP 1.101935 0.009055 121.69 <2e-16 ***
--- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
SBP에 관한 것부터 보자.
추정치(Estimate)는 1.101935다. 이는 SBP가 1 증가할 때, CVD_RISK가 1.101935 증가한다는 의미다. 즉, 이는 $xy$평면에서 기울기를 의미하고, 양의 상관관계가 있다는 말이다. 이 값은 논문에서 종종 $\beta$값으로 불린다.
추정치의 표준 오차는 0.009055다. 이는 추정치(Estimate)의 변동가능성을 의미하고, 이보다 오른쪽에 있는 Pr(>|t|)를 구할 때 사용된다.
Pr(>|t|)는 2e-16보다 작다. 이는 p-value를 의미하는데, $2\times 10^{-16}$보다 작으므로 매우 유의한 결과임을 알 수 있다. 그러므로 귀무가설을 기각하면 되는데, 선형 회귀분석에서는 귀무가설과 대립가설이 무엇일까?
귀무가설: $H_0=$ 추정치(Estimate)는 0이다. 즉, 이 표본이 기원한 모집단에서 SBP와 CVD_RISK는 아무런 관련성이 없다.
대립가설: $H_1=$ 추정치(Estimate)는 0이 아니다. 즉, 이 표본이 기원한 모집단에서 SBP와 CVD_RISK는 모종의 관련성이 있다.
따라서, 우리는 SBP와 CVD_RISK 사이의 양의 상관관계가 유의미하며, 추정치 1.101935는 유의미하다고 결론내린다.
하지만, 우리가 선형 회귀 분석을 시작한 목적은 SBP의 값으로 CVD_RISK의 값을 예측하기 위함이었는데, 기울기만 알아서는 $xy$평면에서 직선을 그릴 수 없다. 우리는 $y$절편 또한 알아야 한다. 따라서 Intercept값을 보아야 한다.
Intercept는 23.036415이다. 사실 이 값에 대한 p-value는 큰 의미가 없다. 왜냐하면 우리는 이 값이 0이든 아니든 관심이 없기 때문이다.
어찌 되었든 우리는 SBP와 CVD_RISK사이의 관계식이 다음과 같음을 알 수 있게 되었다.
$CVD\_RISK=23.036415+1.101935\times SBP$
(Residual standard error부터의 내용은 조금 뒤에 다시 설명하겠다.)
그런데 SBP와 CVD_RISK의 산점도를 그리고 위 식을 같이 그려 넣으면 다음과 같은 plot을 얻을 수 있다.
산점도 그리는 법:2022.12.07 - [[R] 그래프 작성] - [R] [plot() 함수] 산점도 그리기 (1) - plot(), colors()
추세선 그리는 법:2022.12.22 - [[R] 그래프 작성] - [R] [plot() 함수] 추세선 그리기 - plot(), abline()
#산점도 그리기
plot(df$SBP, df$CVD_RISK)
#추세선 그리기 방법 1
abline(23.036415,1.101935, col="blue", lwd=3)
#추세선 그리기 방법 2
abline(LR_SBP_CVD$coefficients[1],LR_SBP_CVD$coefficients[2], col="blue", lwd=3)
#추세선 그리기 방법 3
abline(LR_SBP_CVD, col="blue", lwd=3)추세선 그리기 방법 2는 다음과 같이 이해할 수 있다.
LR_SBP_CVD$coefficients는 위의 summary(LR_SBP_CVD)중 다음 부분만을 불러온 것이다.
Coefficients:
Estimate
(Intercept) 23.036415
SBP 1.101935
따라서 LR_SBP_CVD$coefficients의 첫 번째 항목을 의미하는 LR_SBP_CVD$coefficients[1]은 Intercept을 의미한다.
LR_SBP_CVD$coefficients의 첫 번째 항목을 의미하는 LR_SBP_CVD$coefficients[2]는 기울기를 의미한다.
결과
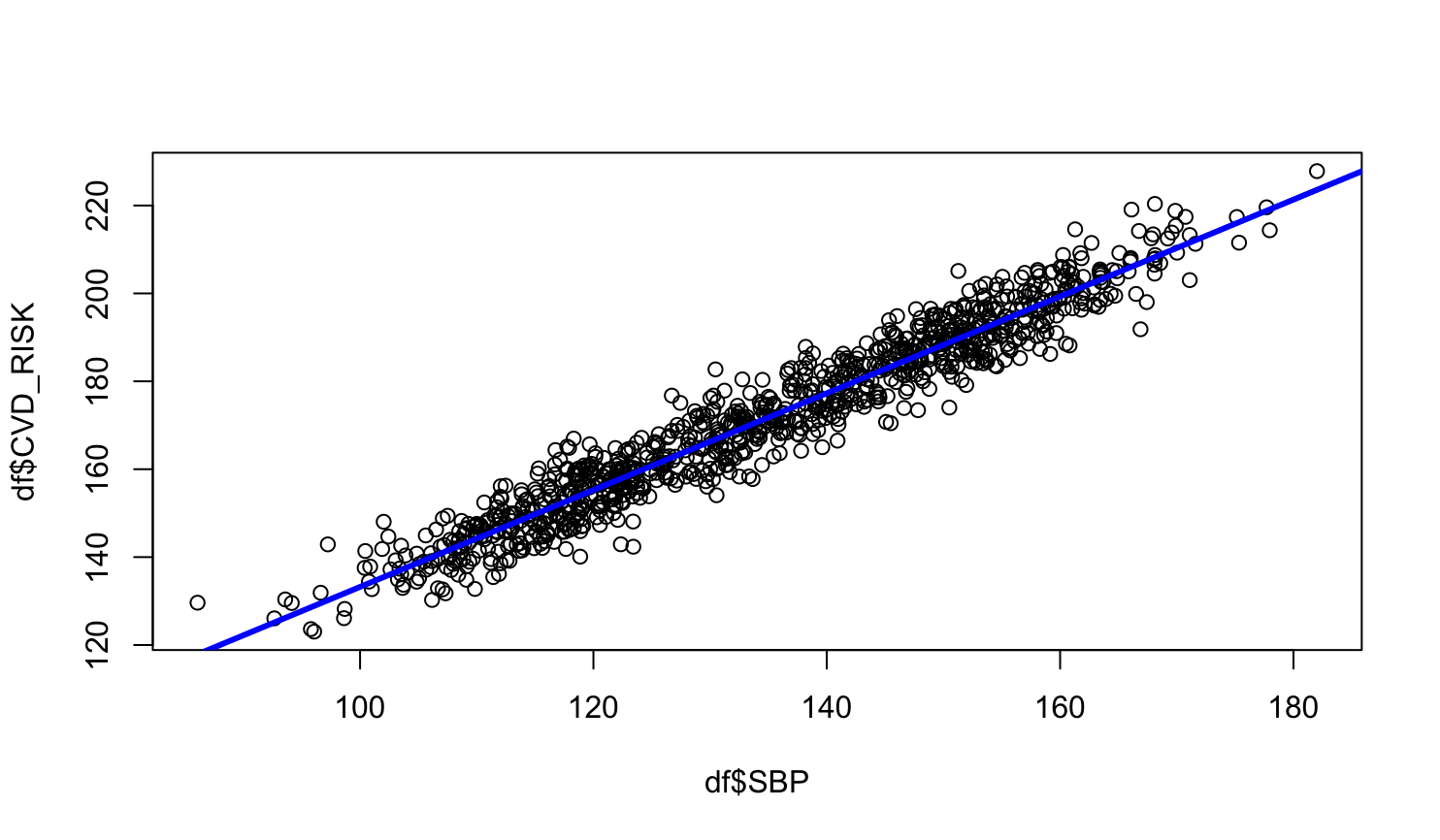
추세선처럼 데이터에서 SBP가 증가할수록 CVD_RISK가 증가하고 있다. 하지만 모든 데이터가 완벽히 선 위에 있는 것은 아니다. 선 위의 값들은 예측된 값이므로 실제값과는 차이가 있다. 이 차이를 Residual라고 한다.
그럼 원래 summary(LR_SBP_CVD)의 내용으로 돌아가보자.
Residual standard error: 5.176 on 998 degrees of freedom :
이는 위에서 설명한 residual의 표준오차가 5.176이라는 뜻이다. 자유도(degrees of freedom)가 언급된 이유는, 표준오차를 계산할 때 자유도를 이용하기 때문이다.
Multiple R-squared: 0.9369 : R squared는 SBP가 CVD_RISK를 어느 정도 설명하는지를 의미한다. 여기에서는 SBP가 CVD_RISK를 93.69% 설명한다고 말할 수 있다.
Adjusted R-squared: 0.9368 : 본 분석은 독립 변수가 1개이므로 별로 의미는 없는 지표이다. 그럼에도 불구하고 Adjusted R-squared를 설명하면, 다음과 같다. 독립 변수가 많아지면 많아질수록 종속 변수를 설명하는 능력은 증가되기 마련이다. 하지만 마냥 변수가 많아진다고 실제로 설명력이 높아지는 것은 아니다. 따라서 어느 정도의 페널티를 주어야 하는데, 이 패널티를 고려한 것이 Adjusted R-squared이다.
F-statistic: 1.481e+04 on 1 and 998 DF, p-value: < 2.2e-16 : 이 내용도 독립 변수가 1개인 본 분석에는 별로 의미가 없다. 그럼에도 불구하고 설명하면 이 p-value의 귀무가설은 "모든 독립 변수의 Estimate가 0이다"이다. p-value가 0.05보다 작으므로 적어도 한 개 이상의 Estimate가 유의미한 값을 갖는다는 결론을 내리게 된다. 하지만 여기에서는 독립 변수가 원래 1개이므로 그 독립변수, SBP가 유의미하다는 것을 알 수 있다.
가정
단순 선형 회귀 분석 자체는 간단하지만, 단순 선형 회귀 분석 시행의 전제조건을 따지는 것이 이보다 까다롭고 더 중요하다. 이는 내용이 꽤 많으므로 다음 포스팅을 참고하길 바란다.2022.12.22 - [선형 회귀 분석/R] - [R] 선형 회귀 분석의 전제 조건 - lm(), plot()
독립 변수의 종류: 연속형
필자는 연속형 변수인 SBP를 독립 변수로 사용하였다. 만약 범주형 변수를 사용하고자 한다면 분석 방법이 약간은 달라지게 된다. 이에 관한 내용은 다음 링크에서 확인할 수 있다.2022.12.22 - [선형 회귀 분석/R] - [R] 범주형 변수의 선형 회귀 분석 (Simple linear regression with categorical variables) - lm(), factor()
[R] 단순 선형 회귀 분석 (Simple linear regression) 정복 완료!
작성일: 2022.12.22.
최종 수정일: 2023.05.14.
이용 프로그램: R 4.2.2
RStudio v2022.07.2
RStudio 2022.07.2+576 "Spotted Wakerobin" Release
운영체제: Windows 10, Mac OS 12.6.1
'선형 회귀 분석 > R' 카테고리의 다른 글
| [R] 선형 회귀 분석의 모델 최적화 : 전진 선택법, 후진 제거법 - lm(), step() (1) | 2022.12.23 |
|---|---|
| [R] 다중 선형 회귀 분석 (Multiple linear regression) - lm(), factor() (0) | 2022.12.23 |
| [R] 범주형 변수의 선형 회귀 분석 (Simple linear regression with categorical variable) - lm(), factor() (1) | 2022.12.22 |
| [R] 선형 회귀 분석의 전제 조건 - lm(), plot(), gvlma() (2) | 2022.12.22 |