[SAS] 편상관 계수, 부분 상관 계수 (Partial correlation coefficient) - PROC CORR
세상의 많은 지표들은 서로 상관되어있는 경우가 많다. 비흡연자에 비해 흡연자가 폐암에 잘 걸리고, 부모의 키가 클수록 아이의 키도 크다. 소득 수준이 높은 나라일수록 평균 수명도 길고, 수학 점수가 높은 학생은 물리 점수가 높으며, 식당에서 음식을 많이 시킬수록 계산해야 하는 금액도 커진다. 변수의 형태에 따라 피어슨 상관 계수 (Pearson's correlation coefficient)를 구하거나 스피어만 상관 계수 (Spearman's correlation coefficient), 혹은 켄달의 타우 (Kendall's tau)를 구하기도 한다. 관련 내용은 다음 링크에서 확인할 수 있다.
2023.04.10 - [상관분석/SAS] - [SAS] 피어슨 상관 계수 (Pearson's correlation coefficient) - PROC CORR ()
그런데 만약 다음과 같은 상황이라면 어떨까?
목표: 수축기 혈압이 심혈관 질환 위험에 미치는 영향을 알아보고자 한다.
상황: 수축기 혈압이 높은 사람은 일반적으로 BMI도 높다. 그런데, 높은 BMI는 심혈관 질환의 위험 인자다.
문제: 높아진 심혈관 질환 위험이 수축기 혈압 때문인지, BMI 때문인지 구분할 수가 없다.
이런 상황에서 BMI를 교란 요인 (confounding factor, confounding variable, confounder)이라고 하며, 교란요인의 영향을 보정하는 것은 의학 통계 전반에 있어서 아주 중요한 문제다.
상관 계수 (correlation coefficient)를 구할 때 교란 변수를 보정하는 방법은 편상관 계수 혹은 부분 상관 계수(partial correlation coefficient)를 구하는 것이다. 이에 대해서 알아보도록 하겠다.
*실습용 데이터는 아래 링크를 클릭하면 다운로드할 수 있습니다.
2022.08.04 - [공지사항 및 소개] - 분석용 데이터 (update 22.12.18)
분석용 데이터 (update 22.12.18)
2022년 12월 18일 버전입니다. 변수는 계속하여 추가될 예정입니다. 다음 카테고리에 있는 글에서 이용된 데이터입니다. - 기술 통계 - 범주형 자료 분석 - 모평균 검정 - 상관분석 - 반복 측정 자료
medistat.tistory.com
시작하기 위해 라이브러리를 만들고, 파일을 불러온다.
라이브러리 만드는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 라이브러리 만들기 - LIBNAME
파일 불러오는 방법: 2022.08.05 - [통계 프로그램 사용 방법/SAS] - [SAS] 데이터 불러오기 및 저장하기 - PROC IMPORT, PROC EXPORT
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
목표: BMI의 영향을 배제 혹은 교정하고도 수축기 혈압은 심혈관 질환 위험과 상관 관계를 갖는가?
코드 - 일반적인 피어슨 상관 계수 구하기
먼저 수축기 혈압과 심혈관 질환 위험 간의 상관 계수를 구해보자. 이는 이전 포스팅에서 다룬 PROC CORR 함수를 사용하면 된다.
2023.04.10 - [상관분석/SAS] - [SAS] 피어슨 상관 계수 (Pearson's correlation coefficient) - PROC CORR
PROC CORR DATA=hong.df;
VAR SBP CVD_RISK;
RUN;
결과
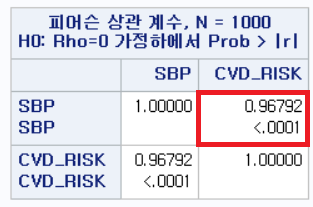
상관 계수가 0.96792로 매우 높다.
그렇다면, BMI의 영향을 배제하는 코드는 어떻게 될까?
코드 - 편상관 계수 / 부분 상관 계수
PROC CORR DATA=hong.df;
VAR SBP CVD_RISK;
PARTIAL BMI;
RUN;PROC CORR DATA=hong.df; : 상관계수를 구하는 작업을 시작하되, 데이터는 hong라이브러리의 df를 사용하라.
VAR SBP CVD_RISK; : SBP와 CVD_RISK간의 상관계수를 구하라
PARTIAL BMI; : 근데, BMI의 영향은 배제시킨 편상관 계수 / 부분 상관 계수를 구하라.
결과
BMI로 보정하면, SBP와 CVD_RISK사이의 상관 계수는 0.85242로 보정하기 전의 0.96792보다는 소폭 감소한 모양이다. BMI가 CVD_RISK를 증가시키는 설명력을 배제하였기 때문이다. 이때의 p-value는 0.0001보다 작으므로 0이 아니라는 대립 가설을 택할 수 있다.
두 개 이상의 교란 변수를 보정
만약, 두 개 이상의 교란 변수를 보정하고자 한다면 보정할 변수들을 list로 만들어 넣으면 된다. BMI뿐만 아니라 흡연력인 SMOK도 보정변수로 넣고 싶다면 다음과 같은 코드를 쓰면 된다. (SMOK는 순서형 변수이므로 Pearson이 적절하지 않으므로 Spearman이나 Kendall 사이에서 골라야 하는데, 같은 값을 갖는 사람(tie)이 많으므로 Kendall의 tau를 구하도록 한다.)
PROC CORR DATA=hong.df KENDALL;
VAR SBP CVD_RISK;
PARTIAL BMI SMOK;
RUN;
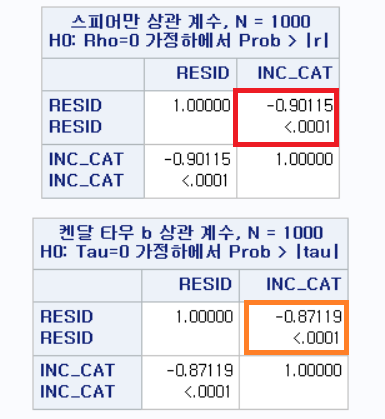
결과
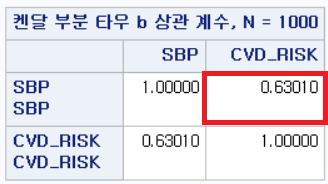
결과에 p-value가 제시되지 않는다. SAS 로그창에는 다음과 같이 언급된다:
NOTE: 켄달의 부분 타우-b 에 대한 확률값을 이용할 수 없습니다.이는 당연하다. SAS의 PROC CORR 다큐먼트에 의하면 다음과 같이 쓰여있다.
If you use a PARTIAL statement, probability values for Kendall’s partial tau-b are not available.
이에 대해 이 방법론의 개발자인 Kendall은 "p-value를 구할 수 있는 방법이 없다." 라고 언급하고 있다. (출처: Goodman, Leo A. "Partial tests for partial taus." Biometrika 46.3/4 (1959): 425-432.)
그런데, 같은 내용을 다룬 R에서는 p-value를 제시하고 있다. 2022.12.18 - [상관분석/R] - [R] 편상관 계수, 부분 상관 계수 (Partial correlation coefficient) - pcor.test() 그 사이 무슨 특별한 방법이라도 개발된 것일까? 당연히 그렇지 않은 것으로 보인다. R에서 제시하는 Kendall's partial tau의 p-value는 일반 Kendall's tau의 p-value와 같은 방법으로 구하고 있는 것으로 보인다. 쌍이 50개 미만이고, tie가 없다면 exact p-value를 구해주고. 그 이상이라면 정규분포를 따른다고 생각되는 통계량을 구한 뒤 그에 대한 p-value를 제시한다.
얼마나 높아야 높다고 할 수 있는가?
상관계수가 "얼마나 높아야 높다고 할 수 있는가?"라는 의문이 들 수 있다. 즉, "how high is high?"라는 질문에 대한 답은 사실 정해져 있진 않다. 연구자마다 기준은 다른데, 그중 한 가지는 다음과 같다.
| 상관 계수의 절댓값 $ ( \vert \rho \vert )$ | 해석 |
| $0.0<\vert \rho \vert\le0.2$ | Very weak |
| $0.2<\vert \rho \vert\le0.4$ | Weak |
| $0.4<\vert \rho \vert\le0.6$ | Moderate |
| $0.6<\vert \rho \vert\le0.8$ | Strong |
| $0.8<\vert \rho \vert\le1.0$ | Very strong |
코드 정리
*라이브러리 지정하기;
LIBNAME hong "C:/Users/User/Documents/Tistory_blog";
*파일 불러오기;
PROC IMPORT
DATAFILE="C:\Users\user\Documents\Tistory_blog\Data.xlsx"
DBMS=EXCEL
OUT=hong.df
REPLACE;
RUN;
*편상관계수 구하기;
PROC CORR DATA=hong.df;
VAR SBP CVD_RISK;
PARTIAL BMI;
RUN;
*두 변수로 보정한 편상관계수(Kendall) 구하기;
PROC CORR DATA=hong.df KENDALL;
VAR SBP CVD_RISK;
PARTIAL BMI SMOK;
RUN;
[SAS] 편상관 계수, 부분 상관 계수 (Partial correlation coefficient) 정복 완료!
작성일: 2023.04.20.
최종 수정일: 2023.10.17.
이용 프로그램: SAS v9.4
운영체제: Windows 11
'상관분석 > SAS' 카테고리의 다른 글
| [SAS] 스피어만 상관 계수, 켄달의 타우 (Spearman's rank correlation coefficient, Kendall's tau) - PROC CORR (0) | 2023.04.10 |
|---|---|
| [SAS] 피어슨 상관 계수 (Pearson's correlation coefficient) - PROC CORR (0) | 2023.04.10 |